一个storm拓扑有一系列特殊的“acker”任务用来跟踪 每一个spout发送的所有tuple的dag(directed acyclic graph有向无环图)。当一个acker看到一个dag完成以后,它会给创造spout touple的spout task发送一个应答ack消息。你可以设置一个拓扑的acker task的个数在Config.TOPOLOGY_ACKERS,默认情况下每个任务的每个worker有一个acker。
理解storm可靠性的最好方式是看tuple的生命周期和tuple dags。当一个拓扑中的一个tuple产生时,无论他是一个spout或者一个bolt,都会随机给定一个64位的id,这些id用来让ackers跟踪dag中的每一个spout tuple。
每个tuple知道存在于他们的tuple 树的spout tuple的ids(也就是这个tuple的源tuple的id(祖宗id)) ,问你在一个bolt中发送一个新的tuple时,他的源spout tuple id会被复制给这个新的tuple。当一个tuple被ack,他发送一个消息到正确的acker task,信息内容包括这个tuple tree是怎么改变的。特别的,他会告诉acker“我是这个源spout tuple的tuple树内部完成的,并且这些是从我产生的新的tuples”。(请继续跟踪他们)
例如,如果tuple“D"和”E“是基于tuple”C”产生的,那么当C ack的时候,tuple 树是这样变化的:
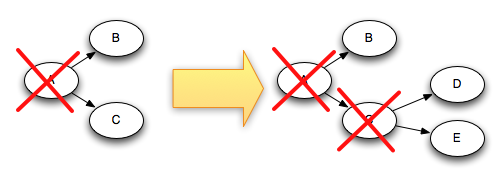
由于C从树中被删除的同时D和E同时被添加进树,这个树绝不会被永久性的完成。
还有一些细节,正如前文所提到,你可以在一个拓扑中有一个任意个数的acker tasks,那么引出一个问题:当拓扑中的一个tuple被ack了,他怎么知道给哪个ack task发送这个ack消息呢?
storm使用mod hashing来处理spout tuple和ack task之间的映射。由于每个tuple都会携带他所处的所有tuple tree的所有源spout tuple id,因此他们知道要跟哪个ack task交流。
另一个storm的细节是ack tasks如何跟踪哪一个spout task负责的所有spout tuple。当一个spout task发送一个新的tuple,他简单地给正确的acker发送一个消息告诉他他要跟踪的任务id,然后当一个acker看到一个树被完成,他知道要给哪个task id发送完成消息。
ack task不显式跟踪tuples的tuple tree,对于那些有几千个节点或者更多的节点的大型tuple树,跟踪所有tuple tree可能会用ackers压倒性的占用内存。替而代之的是,ackers 采取不同的策略,每个源spout id只需要一个固定空间(20bites)。这个跟踪算法就是storm工作的关键,也是他所取得的重大突破之一。
一个acker存储了一个从spout tuple id到 一对数值的一个映射。这一对值中,第一个值是task id,就是创造了spout touple 的task id(spout task id)这个id用来接收完成消息。第二个值是64位的“ack cal”。ack val是整个tuple 树的状态的表现形式,无论这个树多大或者多小,他都是所有无论是acked或者created的tuple id异或的结果。
当一个acker task发现一个ack val变成了0,他就知道这个tuple tree已经完成了。由于tuple id是一个随机的64位数,ack val突然变成0 的几率及其小,数学上,每秒钟10K ack,需要花50000000年才会出现一个错误。即使是这样,那个拓扑的tuple失效了也只会导致数据丢失。
现在,总结storm是如何避免数据丢失的:
由于一个task挂掉了而导致一个tuple不能acked:这种情况下这个失效的tuple所在的树的源spout tuple id将会超时,然后会被重发
acker task 挂掉:这种情况下所有这个acker跟踪的spout tuple id会超时并且重发
spout task挂掉:这个spout交流的source将会重发消息,例如,队列如Kestrel和RabbitMQ 当一个用户失去连接以后将会替换队列中所有挂起的消息。
因此,storm的可靠性机制是完全分布式的、可拓展的、和可容错的。
acker task是轻量级的,一个拓扑中不需要太多acker task,你可以从storm UI(component id“_acker”)中跟踪他们的性能,如果吞吐量看着不太对,你可能需要增加更多的acker tasks。
如果可靠性不重要,你可以忍受发生故障情况下的数据丢失,你可以不跟踪spout tuple,不跟踪可以减少一半的消息传送量,(因为一般每个树里的没个tuple都有一个ack message要传输)还能减少带宽。
有三种方法可以去除可靠性,这里不详述了
原文地址http://storm.apache.org/releases/current/Guaranteeing-message-processing.html