图的遍历
图的遍历是指从图中的某一顶点出发,按照某种搜索方式沿着途中的边对图中所有顶点访问一次且仅访问一次。图的遍历主要有两种算法:广度优先搜索和深度优先搜索。
广度优先遍历BFS
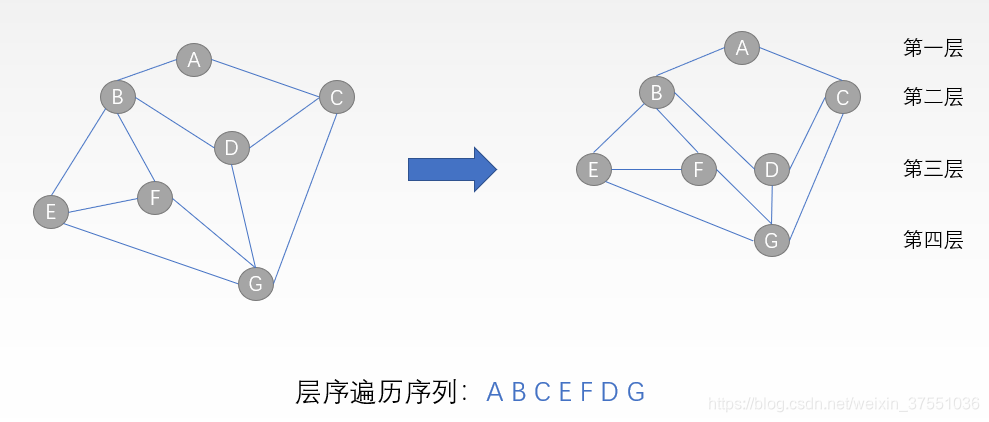
广度优先遍历(BFS 也叫广度优先搜索)类似于二叉树的层序遍历算法
#define MaxSize 100;
bool visited[MaxSize]; //访问数组,记录顶点是否被访问过,初始都赋值为false
void BFS(Graph G,int v){ //图用邻接表存储,从下标为v的位置开始遍历
ArcNode *p; //工作指针p
InitQueue(Q); //初始化一个队列
visit(v); //访问第一个顶点v 具体可以是Print
visited[v]=TRUE; //对v做已访问标记
Enqueue(Q,v); //顶点v入队列
while(!isEmpty(Q)){ //只要队列不空
DeQueue(Q,v); //顶点v出队列
p=G->adjList[v].firstedge; //指针p指向当前顶点的边表链表头指针
while(p){
if(!visited[p->adjvex]){ //p所指向顶点如果未被访问
visit(p->adjvex); //访问p所指向的顶点
visited[p->adjvex]=TRUE; //对这个顶点做已访问标记
EnQueue(Q,p->adjvex); //这个顶点入队列
}
p=p->next; //p指向该顶点的下一条边
}
}
}
void BFSTraverse(Graph G){
int i; //单独定义是为了方便多个循环中使用
for(i=0; i<G->vexnum; i++)visited[i]=false; //将标志数组初始化 (全局数组)
for(i=0; i<G->vexnum; i++){
if(!visited[i])BFS(G,i);} //为了避免非连通图一些顶点访问不到 若是连通图只会执行一次
}
}
BFS复杂度分析
- 不论是邻接表还是邻接矩阵的存储方式,BFS算法都需要借助一个辅助队列Q,n个顶点均需入队一次,在最坏的情况下,空间复杂度为 。
- 当采用邻接表存储方式时,每个顶点均需要搜索一次(或者入队一次)姑时间复杂度为 ,在搜索任意一顶点的临接点时,每条边需要访问一次,故时间复杂度为 。算法的总时间复杂度为 。
- 当采用邻接矩阵存储方式时,查找每个顶点的临接点所需的时间为 ,故算法的时间复杂度为 。
BFS应用
BFS解决单源非带权图最短路径问题:按照距离由近到远来遍历图中每个顶点
void BFS_MIN_Distance(Graph G,int u){
//d[i]表示从u到i结点的最短路径
for(i=0;i<G.vexnum;++i) d[i]=∞; //初始化路径长度
visited[u]=TRUE; d[u]=0;
EnQueue(Q,u);
while(!isEmpty(Q)){
DeQueue(Q,u);
ArcNode *p=G->adjList[u].firstedge;
while(p){
If(!visited[p->adjvex]){
visited[p->adjvex]=TRUE;
//路径长度加1
d[p->adjvex]=d[u]+1;
EnQueue(Q, p->adjvex);
}
p=p->next;
}
}
}
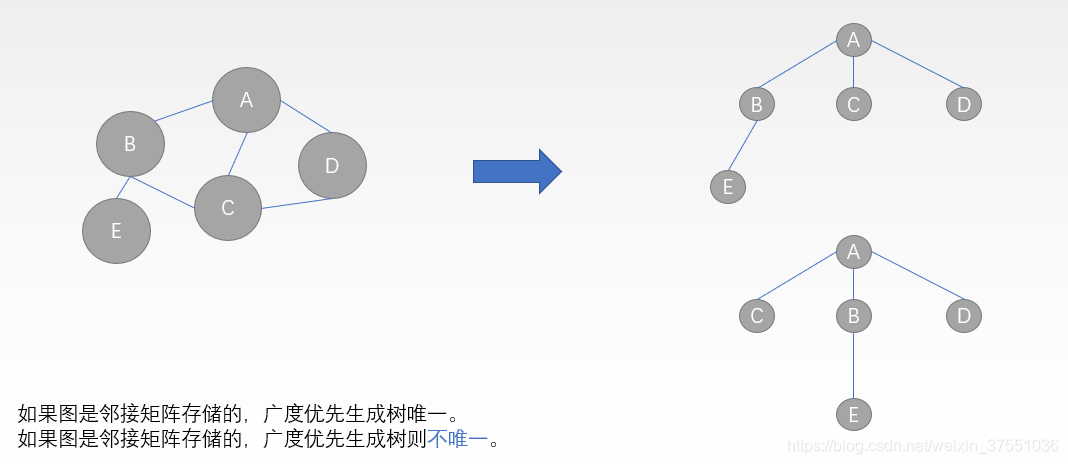
广度优先生成树
深度优先遍历DFS
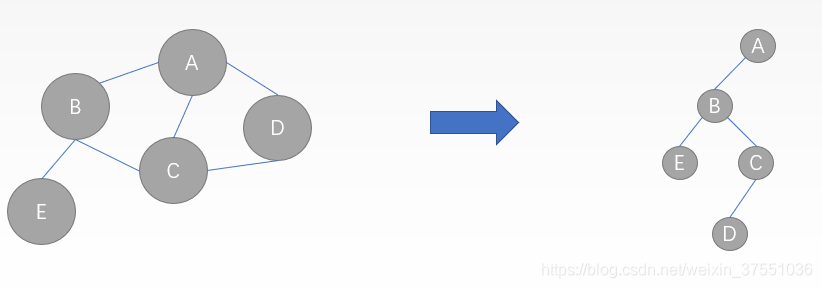
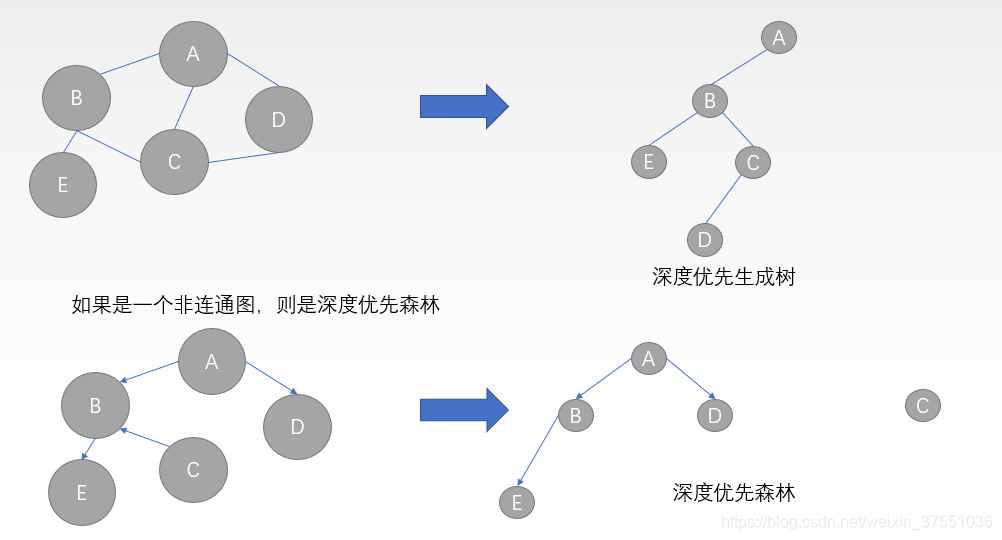
深度优先遍历(DFS:Depth-First-Search):深度优先遍历类似于树的先序遍历算法
首先访问图中某一起始顶点v,然后由v出发,访问与v邻接且未被访问的任一顶点w1,再访问与w1邻接且未被访问的任一顶点w2,……重复上述过程。当不能再继续向下访问时,依次退回到最近被访问的顶点,若它还有邻接顶点未被访问过,则从该点开始继续上述搜索过程,直到图中所有顶点均被访问过为止
#define MaxSize 100;
bool visited[MaxSize];
void DFS(Graph G,int v){
ArcNode *p; //工作指针p
visit(v); //访问顶点v(一般是打印,即printf)
visited[v]=TRUE; //修改访问标记
p=G->adjlist[v].firstarc; //指针p开始指向该顶点的第一条边
while(p!=NULL){ //没遍历完顶点的所有邻接顶点
if(!visited[p->adjvex]){ //如果该顶点没被访问
DFS(G,p->adjvex); //递归访问该顶点
}
p=p->nextarc; //看还有没有其他未访问的顶点
}
void DFSTraverse(Graph G){
int i; //单独定义是为了方便多个循环中使用
for(i=0; i<G->vexnum; i++)visited[i]=false; //将标志数组初始化 (全局数组)
for(i=0; i<G->vexnum; i++){
if(!visited[i]) DFS(G,i); //对所有
}
DFS算法是一个递归算法,需要借助一个递归工作栈,故她的空间复杂度为
。
遍历图的过程实质上是对每个顶点查找其临接点的过程,其耗费的时间取决于所采用的存储结构。
- 当以邻接表表示时,查找所有顶点的临接点所需时间为 ,访问顶点所需时间为 ,此时,总的时间复杂度为 。
- 当以邻接矩阵进行表示时,查找每个顶点的邻接点所需时间为 ,故总的时间复杂度为 。
深度优先生成树
参考资料
王道数据结构
