机器学习分为三个阶段:
-
第一阶段:学习模型。采用学习算法,通过对训练集进行归纳学习得到分类模型;
-
第二阶段:测试模型。将已经学习得到的分类模型用于测试集,对测试集中未知类别的实例进行分类。
-
第三阶段:性能评估。显然,通过测试集产生的分类未必是最佳的,这就导致对测试集的分类可能产生错误。而人们希望尽量得到信呢个最佳的分类模型,就是的对分类器性能评价至关重要。只有通过优秀的评价标准才能选择出性能更好的分类器。
不同机器学习算法的评价指标:

回归评估
-
(1)平均绝对误差(Mean Absolute Error,MAE)又被称为 l1 范数损失(l1-norm loss)

-
(2)平均平方误差(Mean Squared Error,MSE)又被称为 l2 范数损失(l2-norm loss)

分类评估
(1)
准确率(accuracy)
计算公式:Accuracy = (TP+TN)/(TP+TN+FP+FN)
在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用Accuracy,即使全部预测成负类(不点击)Accuracy也有 99% 以上,没有意义。
精确率(precision)
-
定义:正确分类的正例个数占分类为正例的实例个数的比例,也称查准率。
-
计算公式:
TP/(TP+FP)
召回率(recall)
-
定义:正确分类的正例个数占实际正例个数的比例 也称查全率。
-
计算公式:
TP/(TP+FN)
F-值(F-Measure)
-
定义:F-Measure是查全率与查准率加权调和平均,又称为F-Score。
-
计算公式:(1)
F1 = 2PR/(P+R)=2TP/(2TP+FP+FN)
(2)F- = (α^2+1)PR/(α^2)P + R)
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。F值就是用来
权衡Precision和Recall这两个指标的。
上述的评价标准对于类分布的改变较敏感。
MCC 马修斯相关系数
MCC(Matthews correlation coefficient):是应用在机器学习中,用以测量二分类的分类性能的指标[83]。该指标考虑了真阳性、真阴性和假阳性和假阴性,通常认为该指标是一个比较均衡的指标,即使是在两类别的样本含量差别很大时,也可以应用它。MCC本质上是一个描述实际分类与预测分类之间的相关系数,它的取值范围为[-1,1],取值为1时表示对受试对象的完美预测,取值为0时表示预测的结果还不如随机预测的结果,-1是指预测分类和实际分类完全不一致。

衡量不平衡数据集的指标比较好。
AUC(Area Under Curve)
ctr(click through rate)在线广告的点击率。
不可见曝光的ctr大概在1/1000左右,对于可见曝光的广告,其点击率则是在1/100左右,可见多数的曝光是没有click发生的。因此,投放一个可能会被高
概率点击的广告是非常重要的,一方面有效利用了本次曝光,同时一方面也实现了流量变现。
因此,展现的广告完成准确的点击率预估显得非常重要。
ctr预估过程:
即利用历史log,进行训练model,线上server加载这个
model。当有广告展现请求时候,server根据请求的上下文信息计算出候选广告的预估点击率,从其中选择出
最高预估ctr进行展现。
常见的feature有:
- 广告主特征:如行业分类
- 受众特征:如cookie,性别等
- 广告自身特征:如物料的类型(文字链、图片、flash等类型)、广告的核心词等。
AUC在特征选择中的作用
在优化模型的时候,我们期望能够加入足够多有典型区分度的特征。特征有良好的区分度,有助于在筛选广告
阶段进行准确的排序。
对于同一个网页上的广告位而言,用户在浏览页面的时候,从页面上方到下方,广告位的点击率是骤降的,甚至第二位的position,其ctr相对第一position
的ctr会下降90%。
在这种情况下,假定候选广告按照预估ctr(pCTR)进行降序排列后,top前2个广告(命名为a、b)需要选择出
进行展现。一个特征的加入或者缺失,都会影响到a、b的排名。假设a的收益更大,如果排序为b、a,那显然
a的ctr会下降较多,而b的收益又较小,那总体上,本次广告的曝光展现并不是最优的。所以,任何一个特征
的引入或者删除,都要基于实际的历史样本来进行评估这么做的影响,而AUC恰好是用来量化这种影响的重要
指标,或者说AUC是用来评估模型排序能力的重要指标。
在介绍AUC之前,需要引入两个前提概念:ROC以及confusion matrix。
- ROC的全名叫做Receiver Operating Characteristic,其主要分析工具是一个画在二维平面上的曲线
- ——ROC curve。平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)
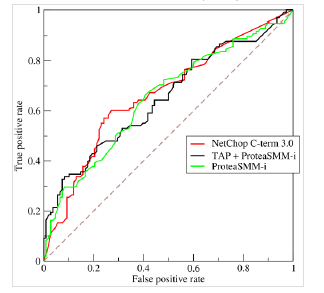
定义roc曲线下面的面积称之为AUC(area under curve)。
总面积为单位矩形(1*1),而AUC的值范围是0~1。一般的,当加入一个高区分度的特征时候,模型的AUC通常是增加的,图片
中的虚线下的面积是0.5。
AUC的计算,需要引入confusion matrix(混淆矩阵)
一个典型的两类混淆矩阵如下:
| 正样本个数P | 负样本个数N | predict |
| ————– | :————: | ——: |
| true positive | false positive | Y |
| false negative | true negative | N |
在AUC的计算中,我们站在正样本的角度来看问题,即使用相关的两个数据项,true positive以及false
positive。在上述的分类结果下,正样本都被分正确的比率是:
tpr = tp / P(真实正样本的个数TP+FN)
,而false positive的比率为:
fpr = fp / N(真实负样本的个数 FP+TN)
将所有广告按照pCTR降序排列,再结合实际的样本数据,就可以计算AUC了。
discrimination threshold,直译为”区分阈值”。 指的是,每次在一个pCTR 上进行划分,取划
分这个pCTR 为阈值,高于这个阈值的是预估的正样本,低于这个阈值,是预估的负样本。在这种情况下,计
算当前这个划分的tpr 和fpr 。得到一个点对( fpr , tpr )。每个划分都会得到一个点对,那么就可以绘
制出ROC,进而计算出AUC。
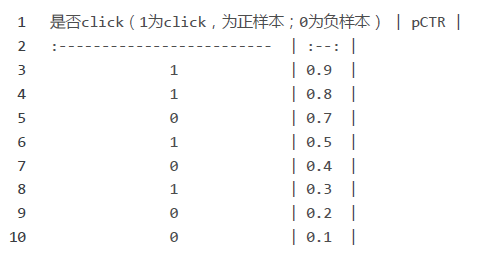
为了计算简答,给出了8个样本,4个正样本,4个负样本。(当然,实际情况下,正负样本的比例远比这个大
的,是imbalance的)为了区分,其中1表示实际的样本是发生了click,而0则表示实际情况下并没法有产生
click。而pCTR为预估的ctr。我们的期望是我们的预估的ctr高的广告,其实际应该有click,这样就说明我的
预估是有效且准确的,当然没有click发生也是可以理解,预估目前还做不到100%的准确。
其划分区间的方式是:
- 在0.9划分,认为>=0.9的都是正样本,<0.9的都是负样本。次划分下, , 。
- 继续,在0.8处划分,认为>=0.8的都是正样本,即会高概率发生click的,<0.8则预估为负样本,此划
- 分下, , 。
- 继续,在0.7处划分,认为>=0.7的预估为正样本,<0.7的为负样本。此时,有1个是误报的。
- , .
- …
- 以此类推,可以计算出所有的fpr、tpr,按照这些点对画出ROC曲线即可。当样本数量足够多情况下,ROC曲线就越平滑。计算的时候将曲线下的每个”小矩形”进行面积累加即可.
理想的排序能力是按照pCTR进行预估降序排列
后,所有的正样本都排在负样本的前面,即预估会排在前面的广告都会被click,此时靠前面的几次划分
fpr都是fpr = 0 / N
模型优化的目标是就是努力向这个理想的目标靠拢。
ROC曲线和AUC的优势:不受类分布的影响,适合与评估、比较类分布不平衡的数据集。因此ROC曲线与AUC已被广泛用于医疗决策制定、模式识别和数据挖掘等领域。但是ROC和AUC仅适合于两类问题 ,对多类问题 ,无法直接应用。