参考:
http://cs231n.github.io/neural-networks-2/
https://blog.csdn.net/zhangxb35/article/details/55223142
一、激励函数
1.sigmoid

[0,1]之间的压缩,模拟神经元的激活
问题
(1)饱和神经元将使得梯度消失
比如对于x = -10,梯度会接近0
x = 0,此时没有问题
x = 10时,梯度也接近0
即对于过大或者过小的数,即位于sigmoid平滑区域的数,会使得梯度消失
(2)sigmoid是一个非零中心的函数
当输入全部为正或者为负时,相当于把上游的梯度符号传了回来,使得权重的更新会一直朝着一个方向,对于梯度的更新非常低效。

因为输出结果在 [0,1]之间,都是整数,所以造成了某些维度一直更新正的梯度,某些则相反。就会造成 zig-zagging 形状的参数更新。不过利用 batch sgd 就会缓解这个问题,没有第一个问题严重。
(3)指数函数整体计算代价比较高
2.tanh(x)
tanh(x) = 2σ(x) - 1

仍有梯度消失的问题,但是解决了第二个问题
3.ReLU
f(x)=max(0,x)
收敛快,在正方向上没有上述会有的饱和问题,杀死一半的神经元
问题:
(1)不是以零为中心的
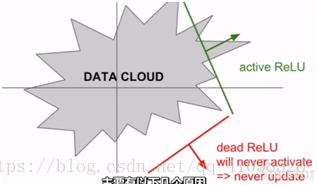
(2)负半轴会产生饱和,而产生梯度消失
比如在数据云中,有部分数据不会激活ReLU,使得它永远不会被更新
发生这种情况的可能原因有:
1.权重初始化差,使得ReLU不会被激活,不会有梯度传回
2.更可能的原因是,学习率太大,在大批量更新的时候,权值不断波动,ReLU就会被数据的多样性淘汰
4.Leaky ReLU
f(x)=max(0.01x,x)
5.PReLU
f(x)=max(αx,x)
α为可学习的参数
6.ELU
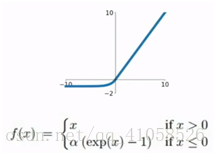
建立一个负饱和机制,使得模型对噪音更具有鲁棒性
7.maxout

泛化的ReLU
问题:参数增加了一倍
经验:
1.一般使用ReLU,但要注意学习率
2.可以尝试Leaky ReLU,maxout,ELU,tanh,但是效果可能不会太好
3.最好不使用sigmoid
二、数据处理

零均值化:解决前面全正全负的数据,使得权重更新向着最优方向。但对于sigmoid,这步处理只能解决第一层的问题,在后续的深度神经网络中,仍然不能解决问题,而且会变得更严重。
归一化:机器学习中各个特征差别较大时会做归一化,但在图像处理中一般不使用
作用:能够更加的抗数据扰动,对数据中的小扰动不敏感
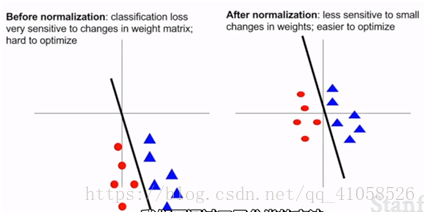
如在左图中,分类函数稍微偏动,对分类结果影响较大,而对于右图影响较小
三、权重初始化
1.全零初始:
会使得所有输出相同,所有梯度相同,所有的更新相同,使得所有的神经元都相同
2.随机极小权重初始

对于很深的网络可能会存在问题,随着层数增加,激活值会从高斯分布,变为一堆0,所有的激活值变成了0,
上层梯度传回,乘以很小的W后会变得很小,基本没有更新

3.较大权重初始
使用1,0代替0.01,对于tanh激活值会饱和,使得所有梯度变为0,权重得不到更新
4.Xavier初始化
要求输入的方差等于输出的方差。对于极少的输入,需要较大的权重,对于较多的输入,需要较小的权重,来使得输入的方差等于输出的方差
5.MSRA初始化
batchnormalization(批量归一化)
给一个输入,计算小批量均值,方差,通过均值方差进行归一化
在神经网络中多加一层,在每个全连接层后面加入批量归一化,使得每个输出都变为均值为0,方差为1
三、学习过程
1.双重确认loss是合理的
(1)对于softmax,reg = 0,则loss = ln(1/n),其中n = class个数
(2)reg = 1e3,则loss上升
2.开始训练,从小数据集开始,小数据集会拟合的很好,得到很小的loss函数,准确率可以为1
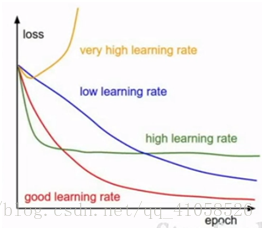
3.调整学习率
从小开始,1e-6,若loss没有很大变化,则学习率设置过低
一般学习率在[1e-3...1e-5]之间
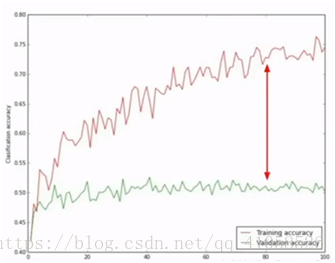
gap过大:overfitting,增大reg
gap过小,模型的capacity不够
4.超参数优化
使用交叉验证,在验证集上检测超参数效果
粗细粒交叉搜索:
(1)范围较宽的区域内,确保参数在范围内,选择较为分散的超参数,然后用几个epoch的迭代去学习。
(2)在得到较好的区间里,做精准搜索,使用10的幂次做搜索比均匀搜索效果更好

learning rate最重要,首先确定
reg,learning rate decay,model size没有那么敏感
来回迭代找出最佳学习率,然后寻找不同模型的大小
用已知的范数来记录更新值,权重更新和权重幅值的比率,使得权重过大过小时就停止训练,避免无用功
5.随机梯度下降的问题
(1)之字型的前进和后退,实际问题中,参数更多,情况更加复杂

(2)局部极小值:看起来像是个大问题,但是事实上,在高维问题上,所有方向都增大,比较罕见,不是严重的问题
鞍点(梯度为0处):在高维问题上,为一个点有些方向损失增大,有些方向损失减少,有一亿个维度,则发生较为频繁。是个大问题,行进会很慢
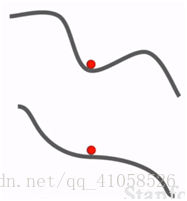
解决:加入冲量,可以对抗部分噪声的影响,速度也能更快


变种:Nesterov Momentum
在取得的速度上进行行走,评估该位置的梯度,然后退回起始点,混合这两个

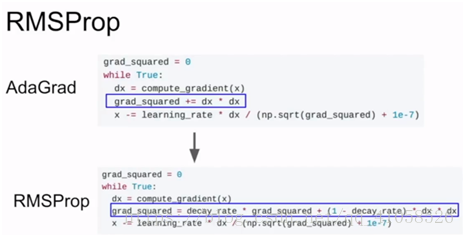
AdaGrad:
添加梯度平方和,更新梯度时去除以平方和

1e-7防止除以零
使得梯度小的维度更新较慢,梯度大的维度更新较快,但是在使用过程中更新速度回越来越慢,在凸函数情况下效果很好,但是在非凸函数情况下,会导致更新卡在一些点。所以实际使用的时候不倾向用
RMSProp
把平方和加到冲量中,改进上述缺点
Adam
RMSProp + 动量 / 动量 + 第二个梯度平方

在初始第一步时,第一动量很小,乘以一个很小的数,再除以很小的第二动量,可能有时候会导致第一步的步长变得非常大,可能会导致初始化完全失败
故加入偏置纠正:
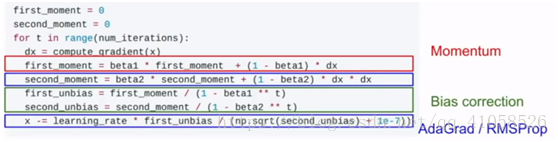
首选,beta1 = 0.9,把它 = 0.999,学习率1e-3、5e-4

learning rate decay:
注意:
(1)Adam这类优化算法中很少用到
(2)二阶超参数,一般不在一开始就使用,一开始就挑选一个较好的学习率,然后仔细观察loss曲线,看看希望在哪儿开始衰减
6.二阶优化
使用二阶导数,牛顿步长,但是不实用,需要求n*n的海森矩阵的逆,n为参数个数。用拟牛顿法去逼近
7.正则化
(1)dropout:
在每层中随机置零部分激活函数,每层计算都是上层激活函数乘以权重得到下一个激活函数
测试时不需要dropout
(2)数据增强:不改变标签的情况下,改变数据
对于图像,随机的左右翻转,选择不同尺寸,调整对比度亮度,色彩抖动,将这类应用于训练,有类似正则化的效果
顺序:
先使用batch normalization
而后可以增加dropout
迁移学习:
在数据量小的情况下,先使用imagenet进行训练cnn,而后再进行精细调整。在文本上可以预先训练一些词向量。