一、文章来由
原博客来自:http://blog.csdn.net/scythe666/article/details/75265338
因为篇幅太长,不宜阅读与编辑,分篇如下
二、cs231n 课程
第二讲:数据驱动的图像分类方式:K最近邻与线性分类器
(1)经典图像识别算法不可扩展,data-driven的方式更科学
早期没有使用的原因是早期没有这么多data,训练的模型是一个类
(2)nearest neighbor classifier
记住所有training images和他们的label,找一个最相近的label
这种方法简单,但是应用时效率低
CNN相对于这个方法反过来,不论训练数据多少,分类时间都是固定的
KNN是nearest neighbor classifier的一种,找到最近K个images,have them vote on the label
5个最近点,分界线变得平滑
超参数:
1)最好的距离选取标准
2)k如何选
(3)5折理论
将所有data5折,其中一折用于超参数的设置
循环验证,选取不同的折来设置超参
(4)线性分类器
类似于filter或者模板
f = Wx+b
将x展平,相乘于W,再加上b
所有的分数都是所有像素点值的加权和
W和b要训练出来
(5)为了定量选择的模型或者权值,定义了loss函数
为了让loss函数最小化
第三讲: 线性分类器损失函数与最优化
(1)计算loss,采用multiclass SVM loss
相当于单个相减,然后加安全系数1(可以是任意正数),hinge loss

full training loss就是在其上除以总数

代码实现

但这个里面有一个bug
如果double每个值,其实结果没有影响,但是会使数据间的差值越来越大
(2)正则化,给每个数字的权值尽量平均
分散权值

(3)softmax classifier

(4)不同的loss函数的比较
最大化log概率比直接最大化概率好
最大不同:
SVM比softmax稳定,就算slightly提高值也不会变化(前提条件是误分类评分小于正确评分减一),softmax不然,将所有样本点纳入考量

(5)梯度下降法
计算复杂,且如果参数很多的时候,每个都要计算不太可能
用微积分求解
要检查,写起来简单
并不是全部数据,而是抽样
SGD是一种常用的更新W的方法
(6)经典方法是用 特征+线性分类器 的方法
比如颜色直方图+hog边缘特征,这样线性分类器就有办法处理,通常是将一幅图人为拆分成多个特征的组合
=== 某种程度上的统计特征
传统方法 vs 深度学习

第四讲:反向传播与神经网络初步
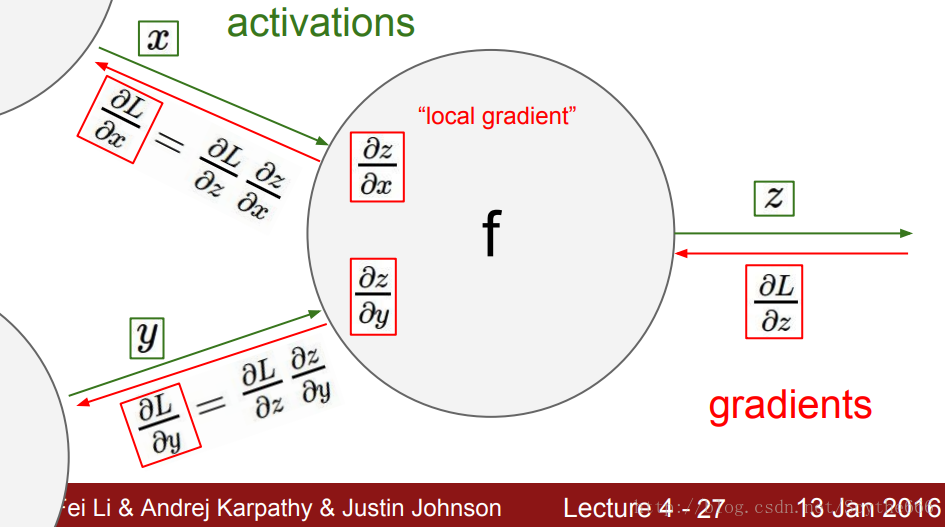
1、求偏导
反向传播
在正向计算的时候,每个参数就能够把其对最后的结果偏导公式计算出来
导数的意义是,因变量的增量与自变量增量的比值


正向和反向传播的时间差不多相同。
2、反向传播门的性质
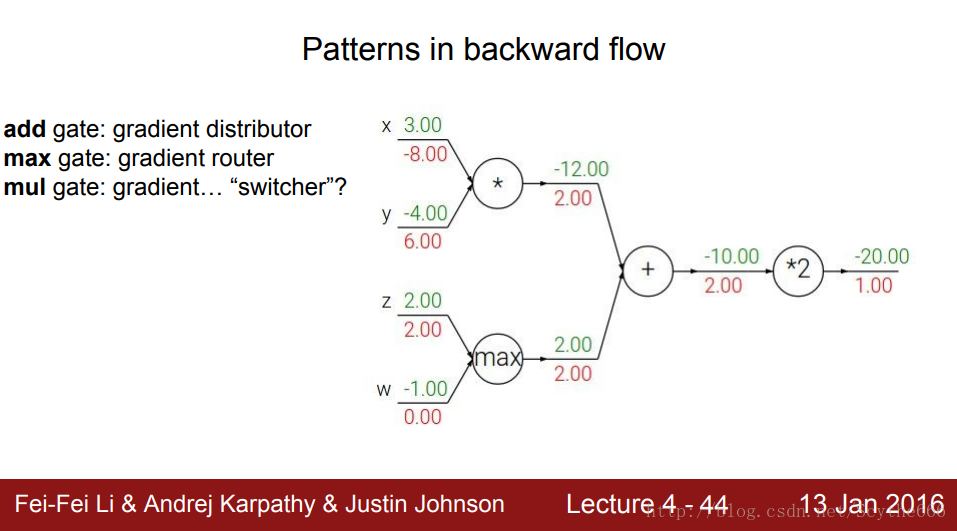
加法门:梯度分配器,将梯度分配到前面的门
max门:梯度路由,将最大梯度放入路由,反向传播的时候只分配给最大的那个(因为不是最大的,对结果产生不了影响)
乘法门:梯度开关
没有回路
3、正向传播与反向传播
1、总结前馈和反馈
对于每次更新,都要进行一次完整的前馈与反馈:
前馈计算loss,反馈计算梯度,update在负权值上权值微调
雅可比矩阵是一阶偏导组成的矩阵
特殊情况下,不必计算雅可比行列式所有值
每一层之间都是通过矩阵连接
2、神经网络
隐含层可以有多个数,自己定义
隐含层引入多样化
换算成公式太复杂,反向传播简化计算
每个单个的neuron都可以看作一个线性分类器
各种激活函数

relu会让神经网络快很多,默认激活函数首选
算神经网络的层数是算有权值的层数
正则化系数越低,拟合程度越高,也越容易过拟合
几条线就大概是几条边界,所以对于circle data来说,3条就好
三条边的组合,第二层只是把这些组合拼在一起
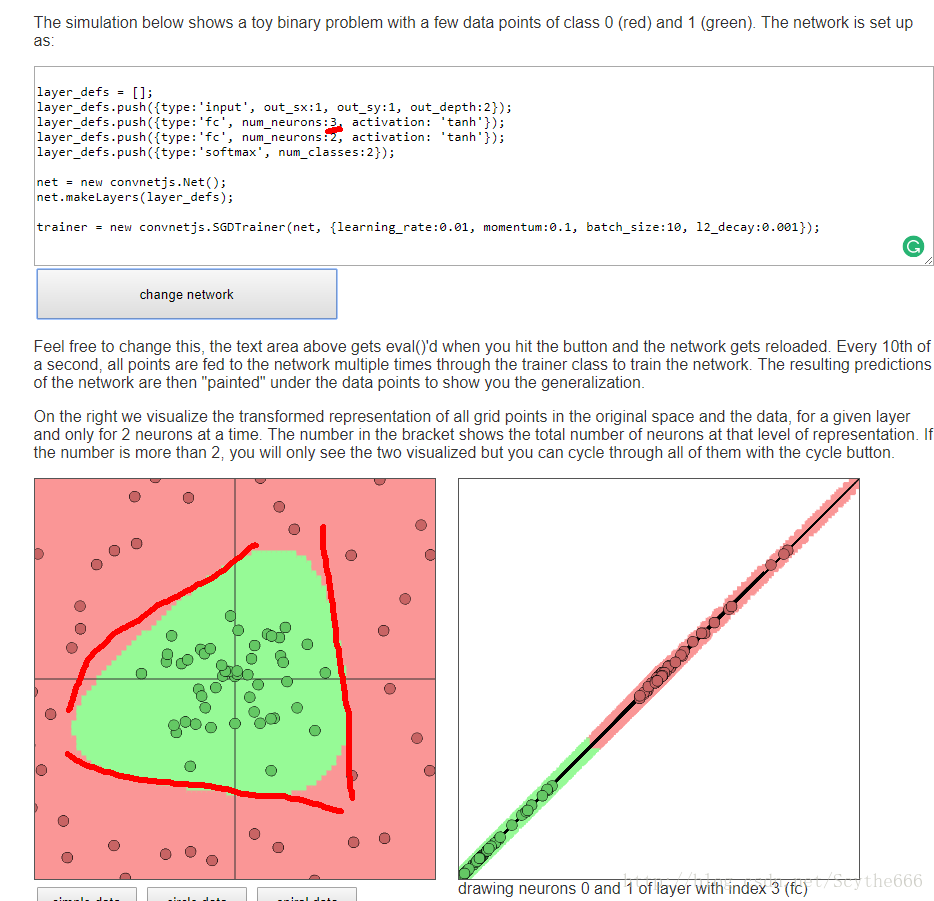
网络中的neuron越多越好,但是要选择合适的正则化项,而不是减少neuron,但可能有没时间训练等因素,所以选用更小的network
如果网络很小,有一种网络优化算法L-BFGS,mini-batch好用,通常用不上
对于更深还是更宽也没有一个确定的答案,对于图片来说,层数更重要
对于其他问题,是data相关的
不同层用不同的激活函数
通常不会这样做,通常是选一个激活函数,整个网络都用,不同层中换不同激活函数一般并没有什么好处
第五讲:神经网络训练细节
https://github.com/BVLC/caffe/wiki/Model-Zoo
大量已经训练好cnn权值数据的模型已经上传到网上,超参数也设置好了
讲述步骤

激励函数
(1)sigmoid function

梯度消失问题
问题很多,饱和的神经元要么非常接近0,要不非常接近1
—>反向的时候,梯度趋于0
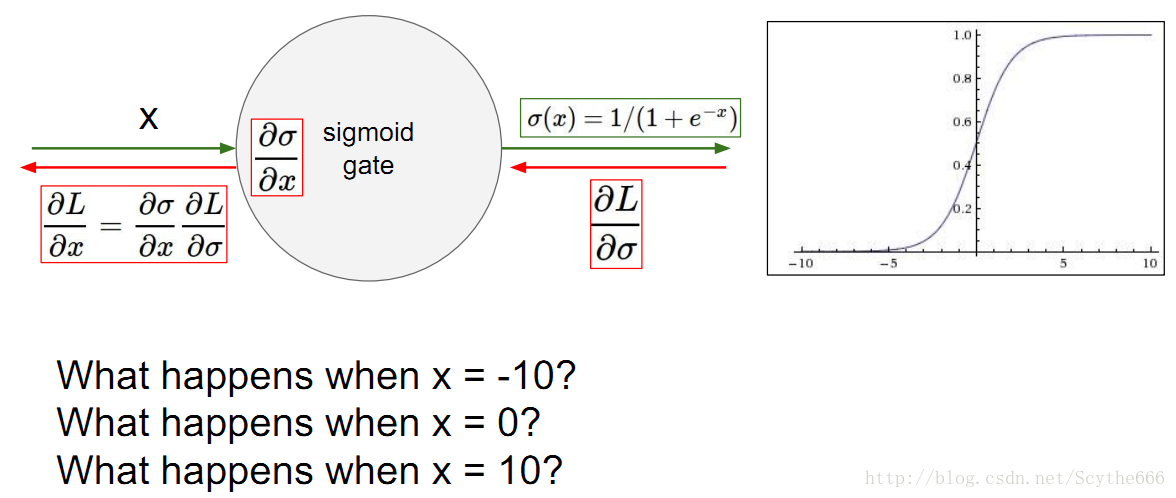
问题1:local梯度很小
只在sigmoid的激活区域才会有用
问题2:
不关于原点中心对称,输出值都在0,1之间
w的梯度要么全正要么全负,收敛速度很慢
问题3:
exp()耗时
但在rnn中用到,因为特殊原因
(2)tanh(x)

(3)ReLU

网络收敛速度快,之前的6倍
问题:不中心对称
如果ReLU从未被激活,那反向的时候就会梯度消失,不激活就不能进行反向传播(不更新权值,可以说什么都不做)
如果激活了,因为局部梯度是1,所以都是将梯度传递给前面的
如果在x为0的时候,梯度未定义,随便选一个对结果也不会有很大影响
dead relu问题:
永远不激活,也不更新
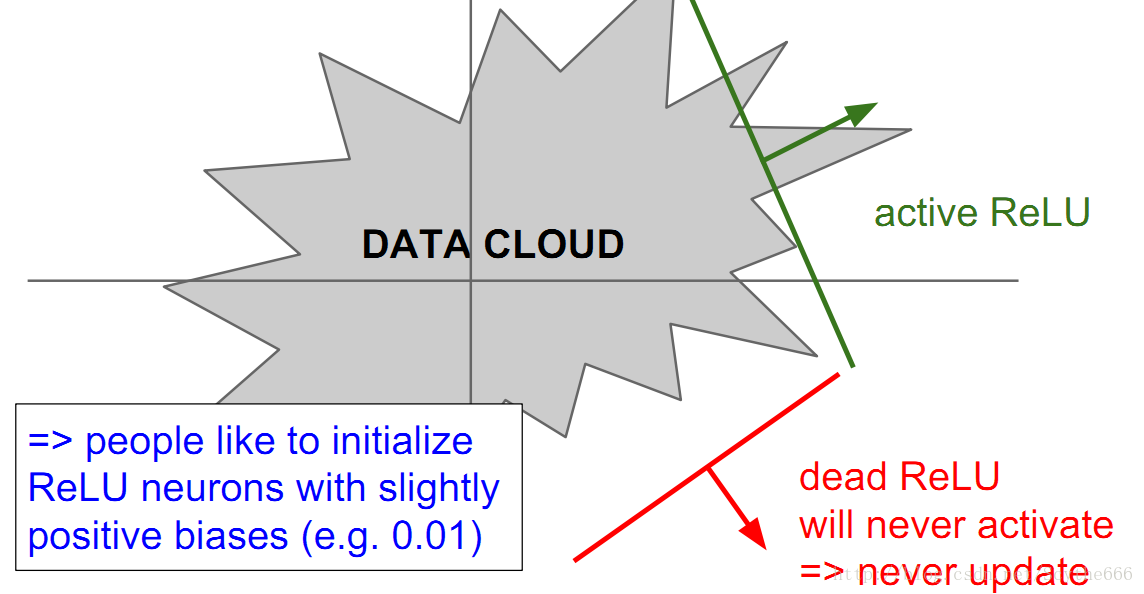
学习率过高也会出现这个问题
解决方法:可以给一个小的bias,重新激活已死的神经元,但是讲者认为这个方法没什么用
(3)Leaky ReLU

也不一定是0.01,可以是任意值,这个α可以被学习,反馈学到
计算图中的每个神经元都有α,可以通过学习学到
还是relu最常用
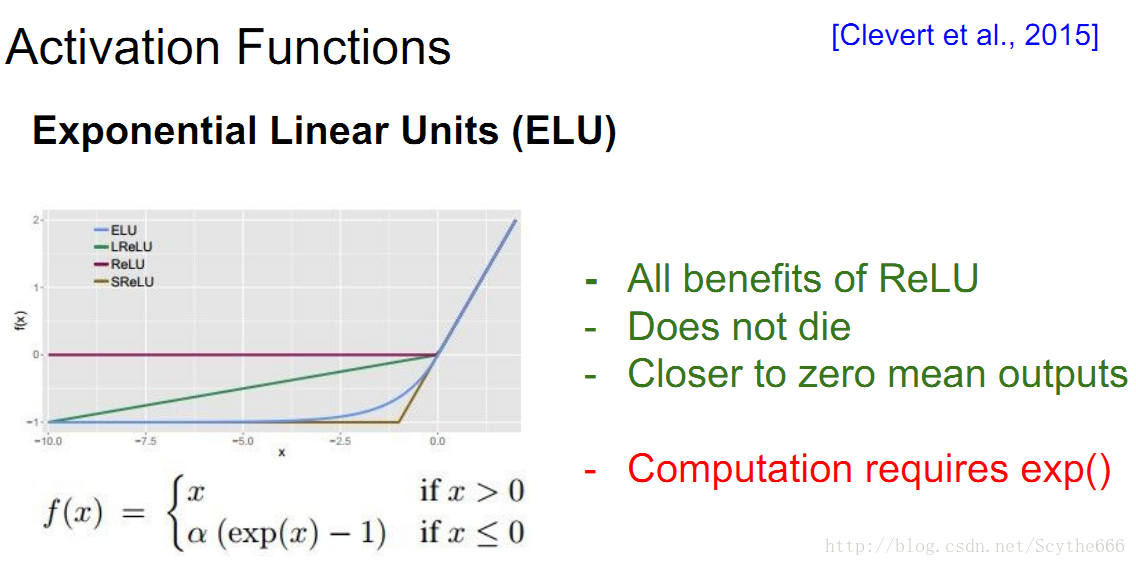
(4)ELU
(5)maxout

数据处理
PPT中介绍了很多数据处理方法,但在图像处理中归一化不常用,但0中心化应用很多,均值中心化

每个像素减去均值image或者减去per channel 均值,后者更常用
权重初始化
过去人们常用全0初始化,但是效果不好,因为所有神经元的计算完全相同,反向的时候梯度也相同。最好采用随机小值。
如果初始化不好,很可能饱和,反向不了
策略也已经有了,2010年提出的Glorot提出的Xavier初始化
但是这个用于tanh,不用于relu
但新发论文引入因数2
但这就是一个data-driven的活,不同批数据效果不同
还有方法是通过一个公式,能够将数据高斯分布化

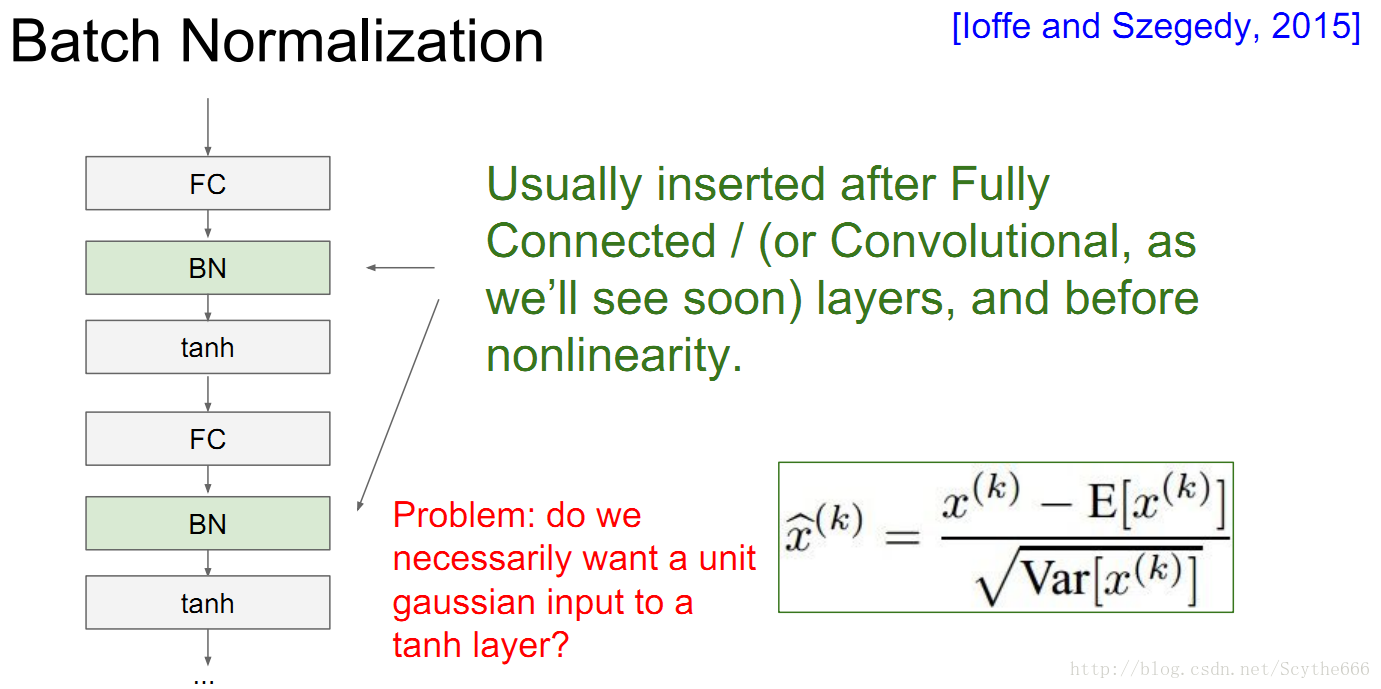
BN有很多优点,如下:

代替了一部分正则化的工作
Note: at test time BatchNorm layer
functions differently:
The mean/std are not computed
based on the batch. Instead, a single
fixed empirical mean of activations
during training is used.
(e.g. can be estimated during training
with running averages)
会稍稍延长一点时间
Babysitting the Learning Process
正确性检查,非常重要
为了确保神经网络工作正常:
step1:初始化2层神经网络,weights和bias用最简单的初始值
step2:two_layer_net那句是train这个网络,最重要的是关注要返回的loss和梯度,讲者取消了正则化,以确保损失值正确
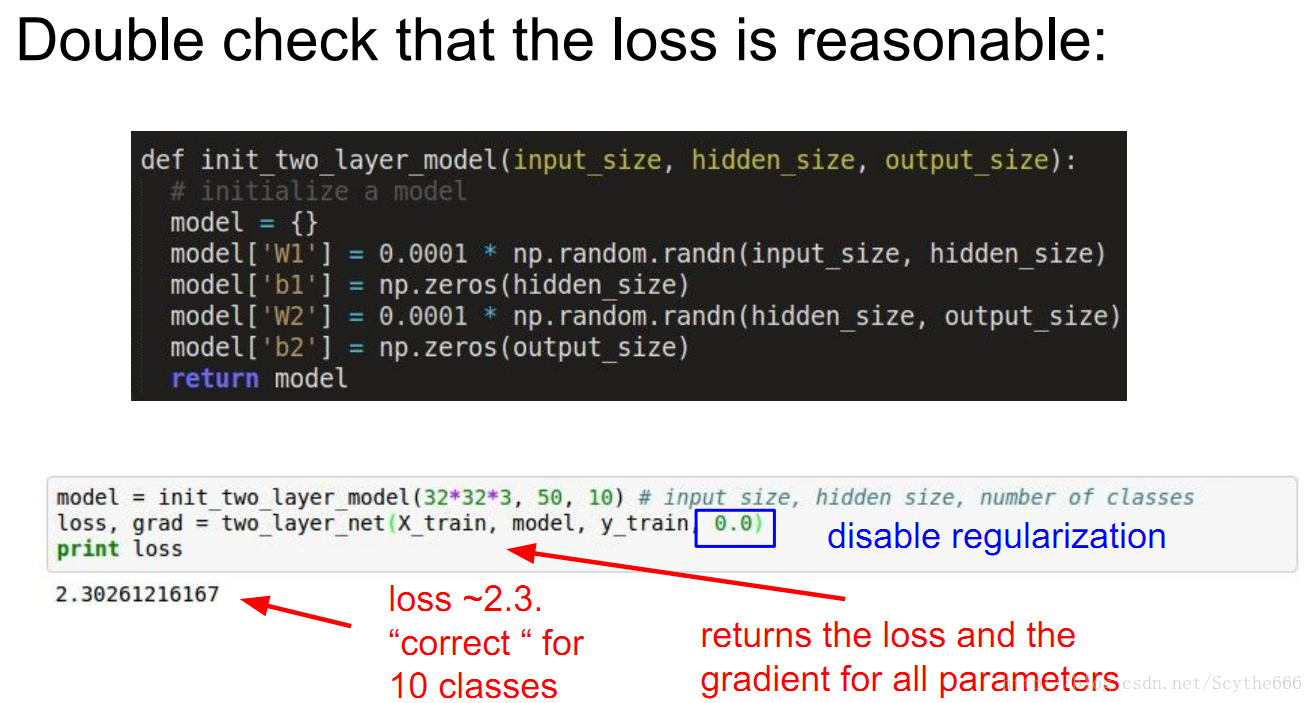
step3:估算,softmax是-log(1/10)
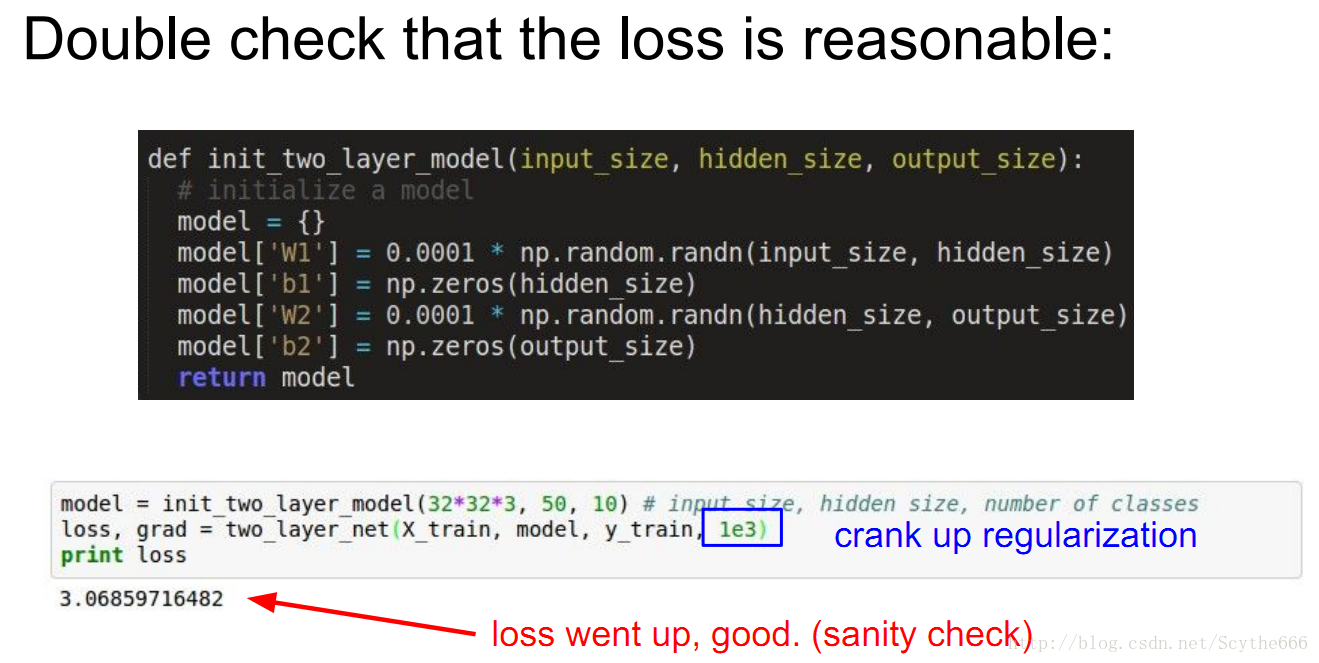
step4:对于小数据,能够达到过饱和说明具有合理性(反向传播+update+学习率OK,算法没有大问题),然后才考虑增大训练集。所以不应该扩大训练集直到完全通过测试。
step5:扩大训练集,在找到好的learning rate,从小的learning rate开始
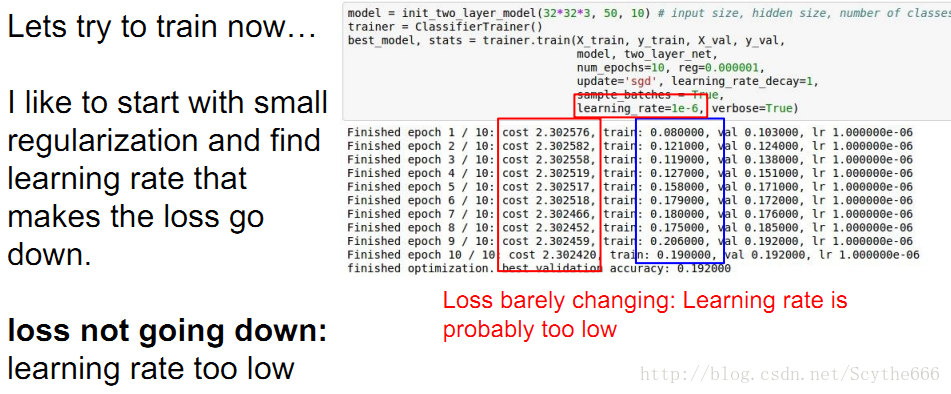
learning rate太小的情况,这种假设是要建立在完成了正确性检查之后,因为检查无误才能大胆判断
但如果rate太大,cost就爆炸了
cost: NaN almost
always means high
learning rate…
超参数优化
粗糙—>精细的过程
超参数优化要随机取样超参数,网格取比随机取差
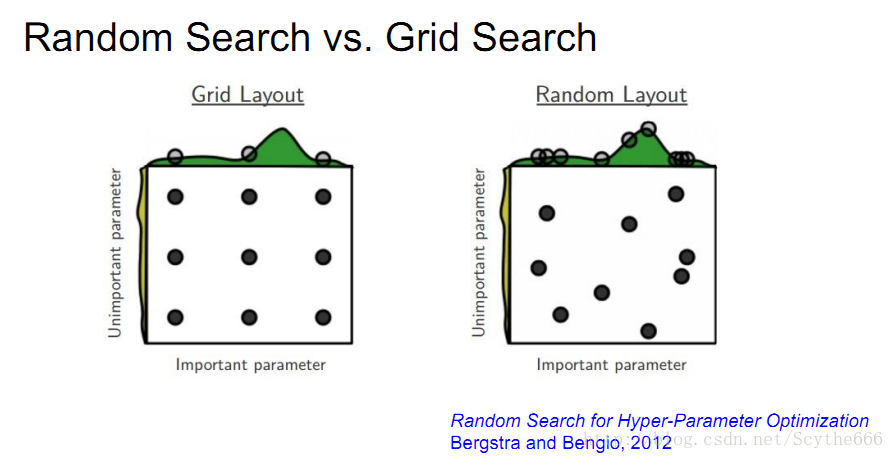
一些可优化的超参

学会解读不同的图形
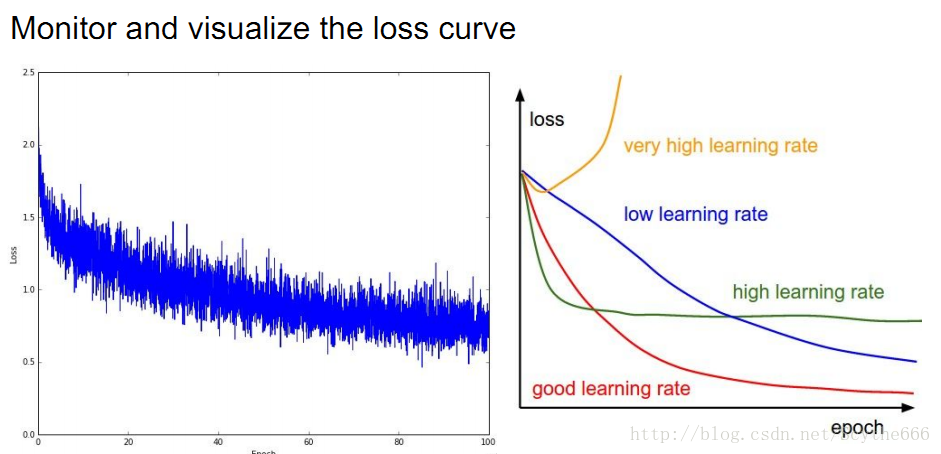
也要关注一些其他的参数,比如准确率
总结:

下节课继续:

第六讲:神经网络训练细节 part2
如何训练神经网络
为什么要用激活函数?
答:如果不用,不论多少层,如上图,也只是一个三层的三明治,还是相当于一个线性分类器,使用线性分类器记忆data
如果初始权重太小,在网络中activate,权值更新就会趋于0;如果太大,就会梯度爆炸
—>那么将会以超饱和的网络或者全0结束
–>选择一个合理的初始化范围很重要
batch normalization减轻初始化权重设定的麻烦

dx是梯度
原来只是用简单的梯度与learning rate相乘,现在要更复杂一点
对于gsd,在竖直方向上比较快,在水平方向上比较慢,所以会震荡,有一种方法就是用momentum方法

mu在0与1之间,通常取0.5~0.9
v通常初始化为0
不同参数更新方法
(1)nesterov momentum

original的方法是建立了一个actual向量,但是现在要做的是想一步超前,计算下一步的梯度,会有一点点的不同
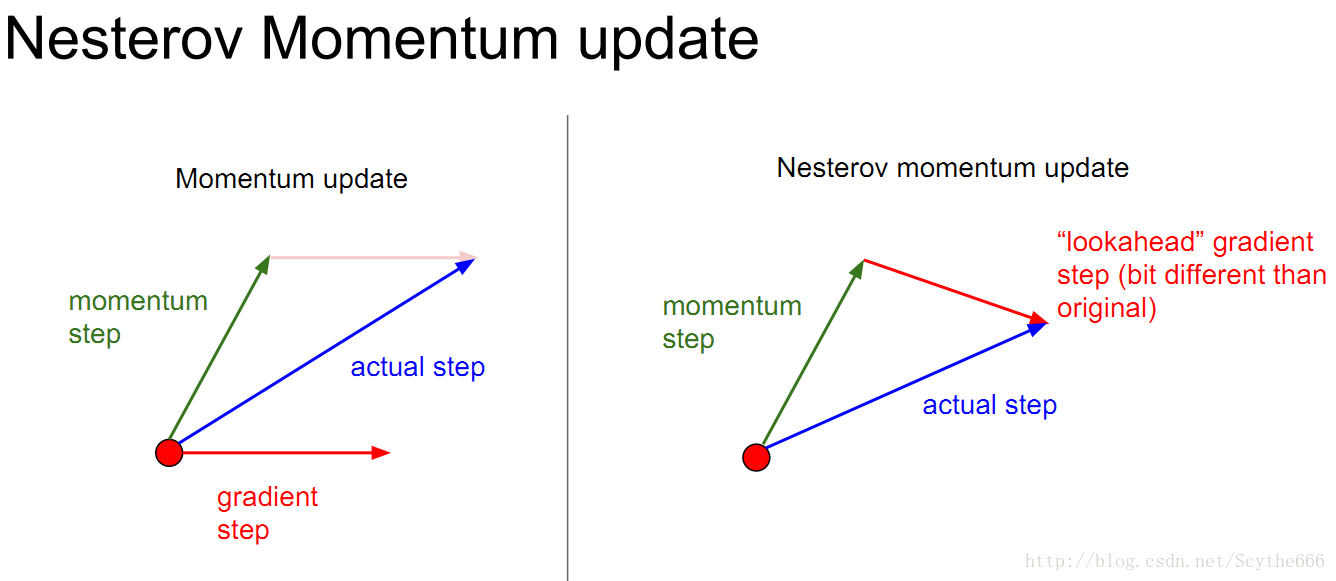
动量法的出现也不是因为有局部最小值,当网络规模越来越大的时候,局部最小值的问题不用特别关心
(2)AdaGrad update自适应梯度法

凸优化理论的成熟拿过来的
用一个cache(梯度的平方和构成,联合矢量,每个维度记录相应梯度的平方和,有时叫做 second momentum),per parameter adaptive learning rate,保存参数空间的每一维都有不同的learning rate,比如上面那张图,垂直方向的learning rate会递减,水平方向的会增大
反对有个问题:learning步长会减少,最终停止
(3)RMSProp update
Hinton做了一个小的改动,将上面的那个问题解决了,不会更新停止,而是不断带来更新
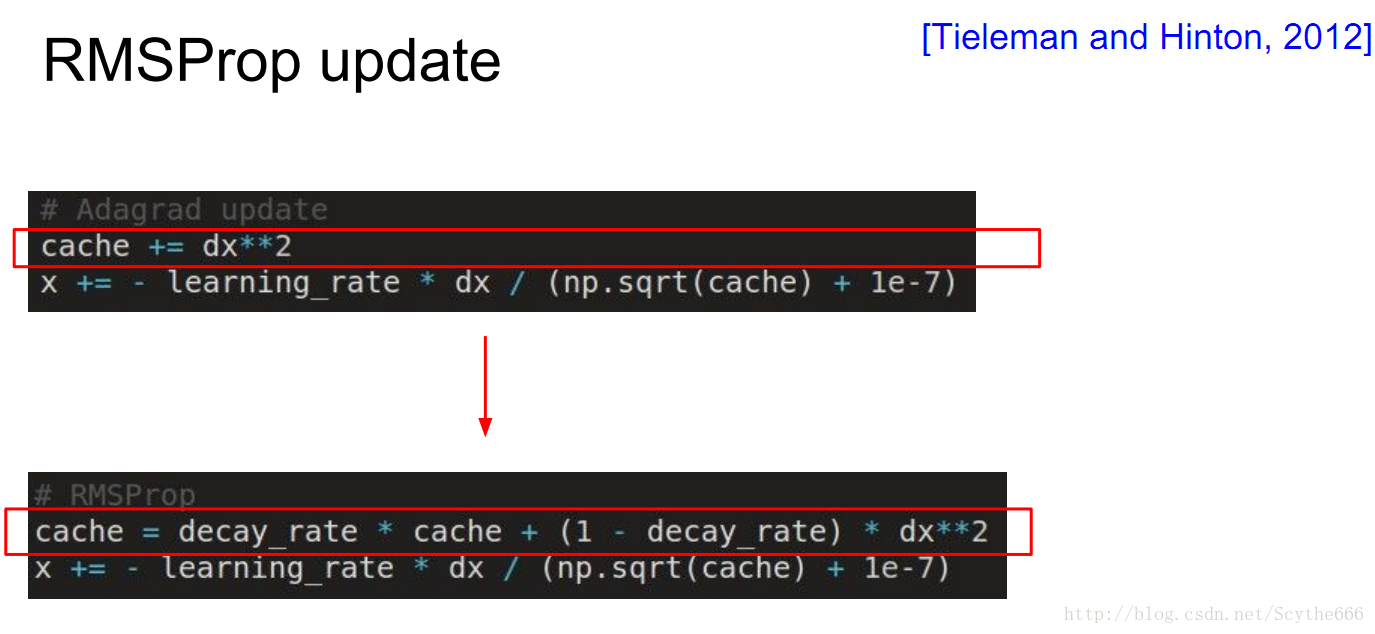

梯度大的地方减慢速度才是最好的
(4)Adam update
ada和momentum的结合
动量用于稳定梯度方向

beta1和2是超参数
beta1通常是0.9,beta2通常是0.995
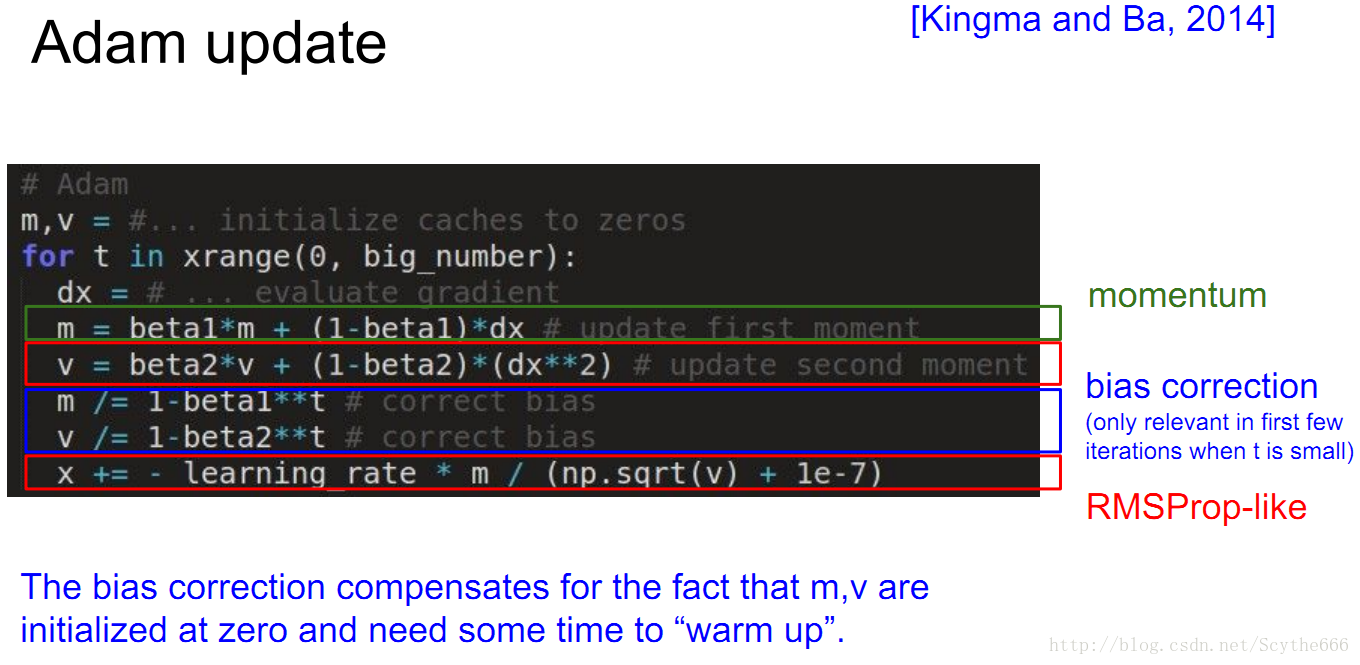
Adam很好用,通常讲者使用Adam
learning rate 怎么设置更好

其实这里很难说,开始的时候最好使用大一点的learning rate,但是到后期可以使用小一点的rate,因为系统能量太大不容易settle down
另一些凸优化方法,但是不细讲

Hessian Matrix,又译作海森矩阵、海瑟矩阵、海塞矩阵等,是一个多元函数的二阶偏导数构成的方阵,描述了函数的局部曲率。黑塞矩阵最早于19世纪由德国数学家Ludwig Otto Hesse提出,并以其名字命名。黑塞矩阵常用于牛顿法解决优化问题。


- Adam is a good default choice in most cases
- If you can afford to do full batch updates then try out
L-BFGS (and don’t forget to disable all sources of noise)
In practice
实际的大数据集不会采用 L-BFGS
adam 不会让你学习率变为0,因为他说leaky gradient;如果用adagrad就不一样了,learning rate可能降到0。
Evaluation: Model Ensembles
- Train multiple independent models
- At test time average their results
Enjoy 2% extra performance

这里x_test是对于现在参数x的一个指数衰减,使用数据集和测试集,结果总比x要好,像参数进行加权的集合(不好解释,想象碗状函数优化问题,在最低点周围不停跳动,最后做一个对这些值的,能够更接近最低点)
Regularization (dropout)
涉及small samples,在前向的时候,要随机将一些神经元置0
不仅在前向的时候,反向的时候也要用

都要乘以U1和U2,随机失活过滤器
防止过拟合,如果只用一半网络,表达能力就变弱了,偏差-方差均衡
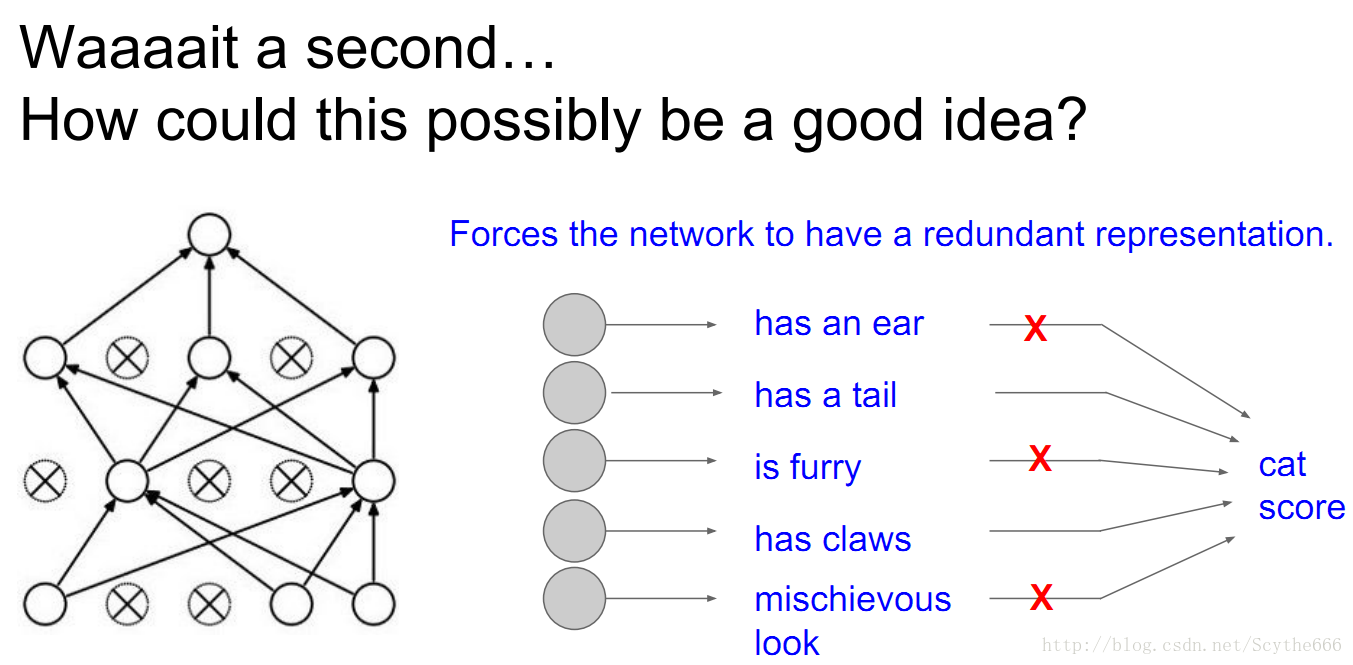
一旦dropout,没有失活的神经元参数或者说神经元梯度才会被更新,因为一旦神经元被关闭,把输出值固定为0,就不会有梯度经过他,他对应的上一层神经元的权值也不会更新,相当于是sub-sampling
因为他的值在计算损失函数中没有用到,所以他的权值也就不更新了
在多次循环中我们会用相同的数据点训练不同的共有参数的模型—>这就是随机失活
每次前向的时候,我们sample,就会得到一个子网络
每一次循环中,我们先得到一个mini-batch,然后在神经网络中取样,得到那些没有失活的神经元,形成子网,然后前向+后向,然后得到梯度,一直重复这个过程
是否可以在不同层失活不同的比例,可以的,如果想更强的正则化,就失活多一点,比如一层有很多神经元,就可以多失活一点
也可以对每一个神经元进行一定概率的失活,叫做drop connect

这里需要补足training的0.5那部分系数,需要在test时激活函数也乘上这个系数,以减小输出值


也有一种方法是在training中将激活函数输出变大

inverted dropout实际中应用很多
这里的0.5不是绝对的,是期望
CNN
进入正题了,目前有一些很有名的网络,比如:
AlexNet,VGG-Net,LeNet,GoogleNet,ConvNet
AlexNet是2012年提出,但是跟1998年提出的LeNet差不多,差别就是一个用sigmoid一个用relu,而且更大更深,用gpu计算。
ConvNet对图像分类在行
第七讲:卷积神经网络详解
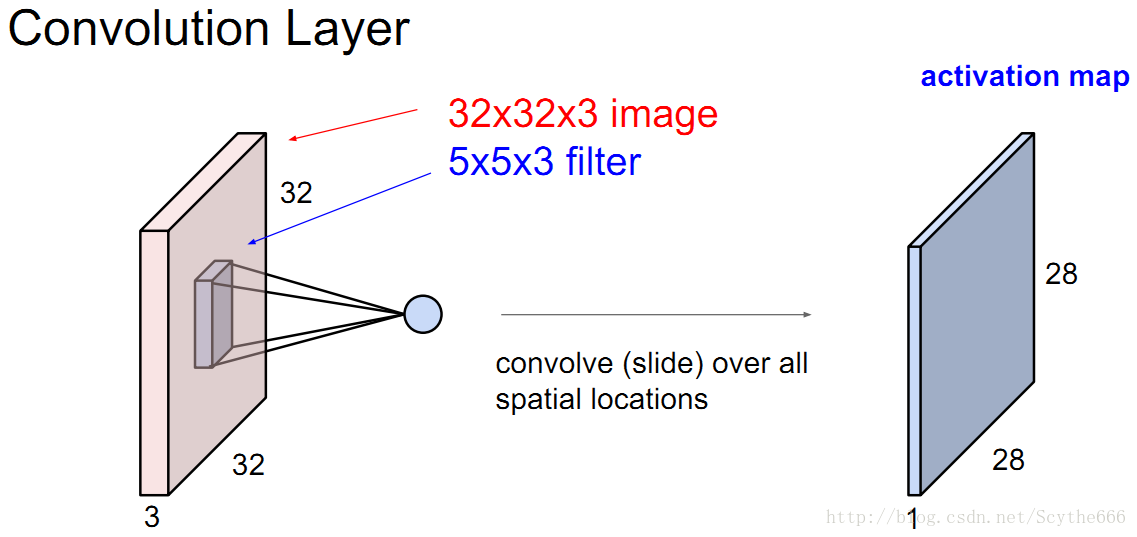
用一个5*5*3的卷积和做运算
—>得到一个28*28*3的卷积激励map
—>用不同卷积filter做运算,可以得到一个多层的卷积组,比如6个,就得到28*28*6的卷积组
—>这些会被feed到下一个卷积层
当然这个过程中要经过激励函数
通常filter都很小,一般3*3或者5*5等等
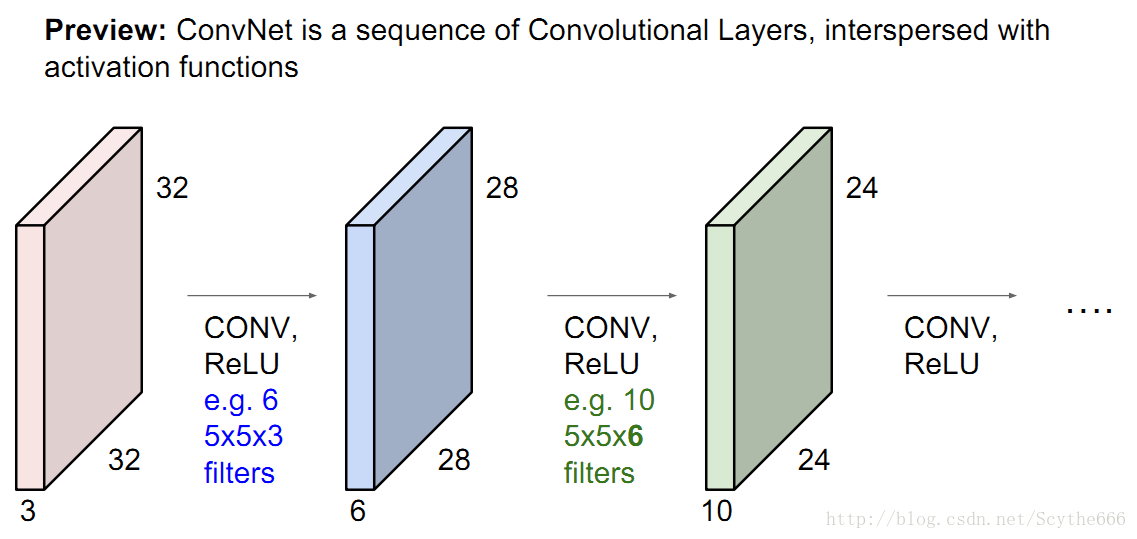
上图中,第二层卷积层的大小变成5*5*6,有10个,所以得到一个24*24*10的卷积组
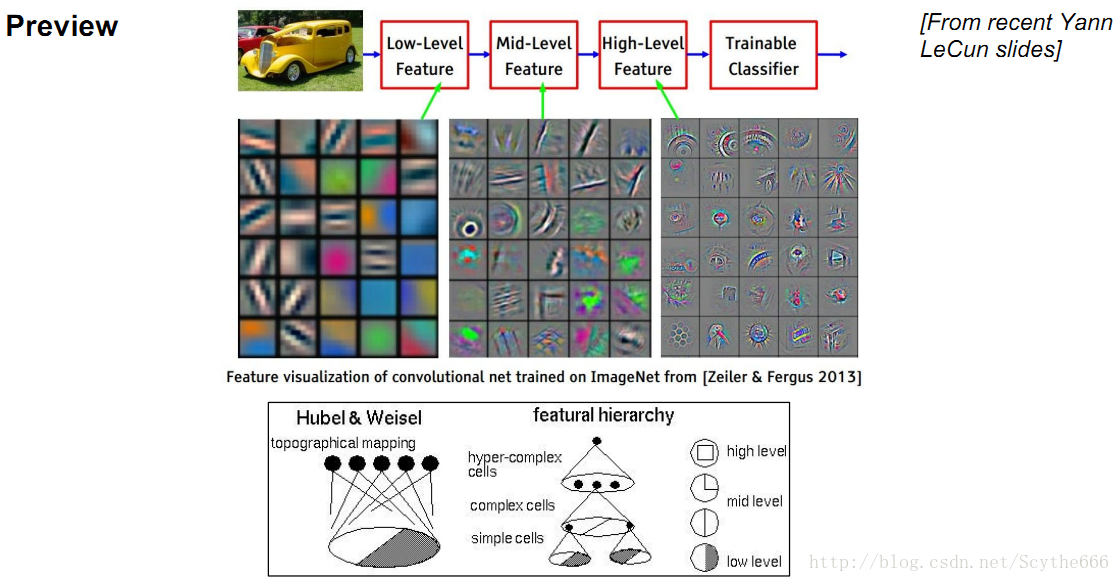
在每一层这会得到不同的特征。
就是不同层的组合

步长不能是任意的,3的时候不允许

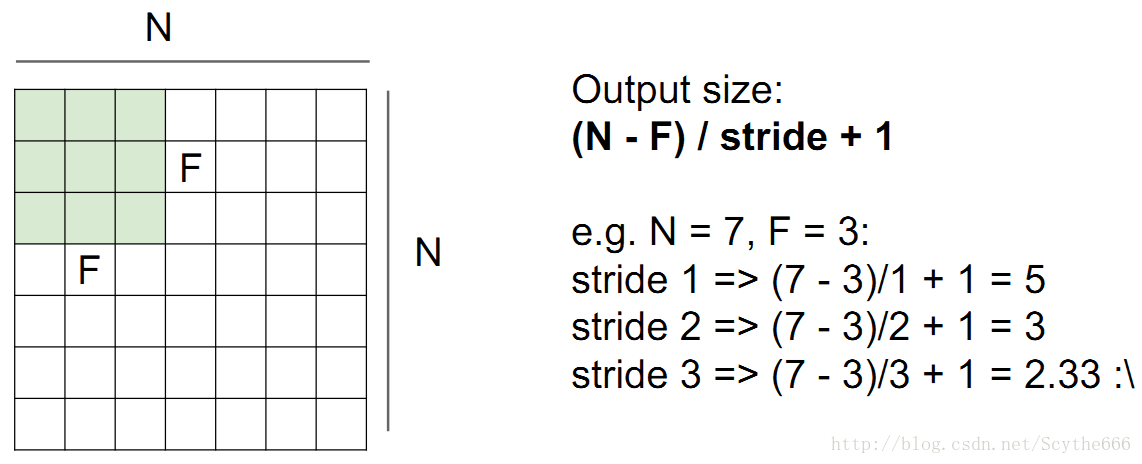
有时候会对图像做填补
作用就是,如果7*7的图像,用3*3的来filter,尺寸不会缩小

因为可能有很多层,如果缩小的太快,是不好的性质

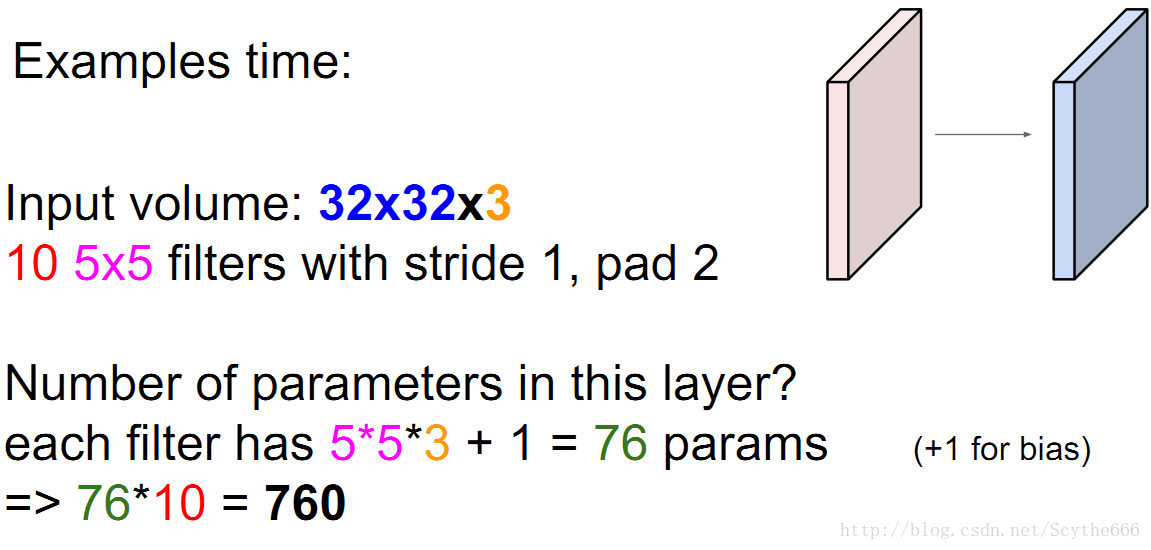
参数还要加上bias
总结一下:

K总要是2的指数,为了方便计算,有些程序对于2指数有特殊优化
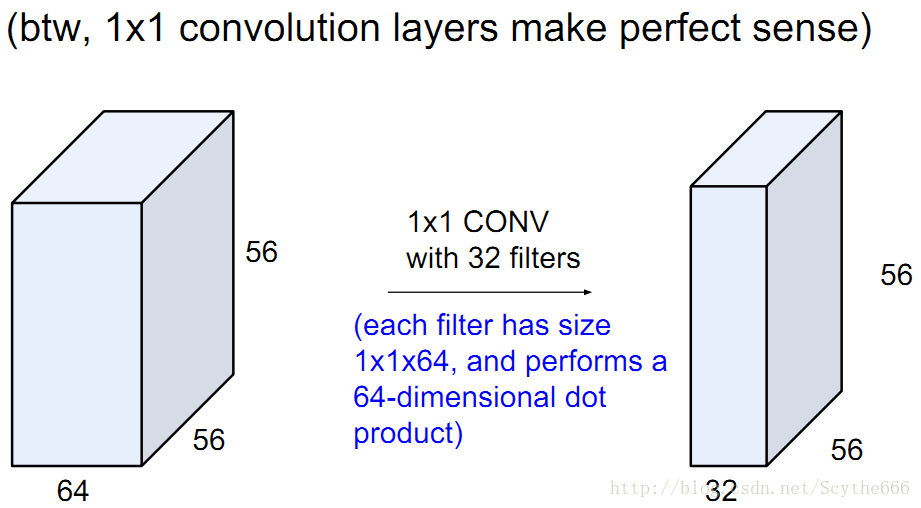
1*1的filter也是OK的,因为不仅是一个的,而是整个深度都参与卷积
filter总是偶数,奇数尺寸的滤波器有更好的表达,2*2也不是不行,但没3*3好
为什么填充的时候,只填充0,因为这样filter只会考虑输入的数据,点乘的时候,0不会对输出有贡献。即便是填充附近的数据。
每一层一般也不会用不同size的filter。
只有第一个卷积层能接触到原始数据,后面的都是接触前一个的数据
filter === kernel
在主流深度学习框架中也有体现:
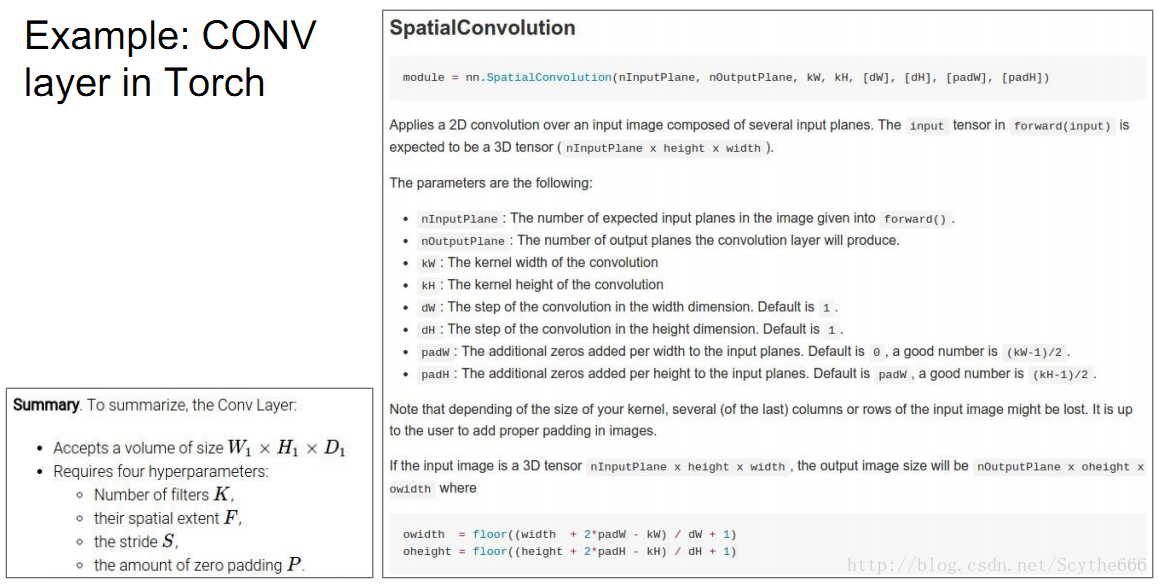

站在神经元的角度来看这个问题:
每个神经元只管自己的一小块区域(对应于一个kernel),一块板上的所有neuron在一个激活映射中都share一个weight

一块版上的neuron有两个重要特性:
共享参数+局域连接
对于多个kernel可以理解为:
所有神经元全部以一个局域模式,共享参数,并关注着同一个数据体

如上图的5个neuron都看着同一块数据
共享参数+局域连接的作用:
从视觉上控制模型的能力,神经元平面上希望计算相似的东西,例如小的边缘,这样的功能是有意义的,也是一种控制过拟合的方式
pooling就是一种下采样
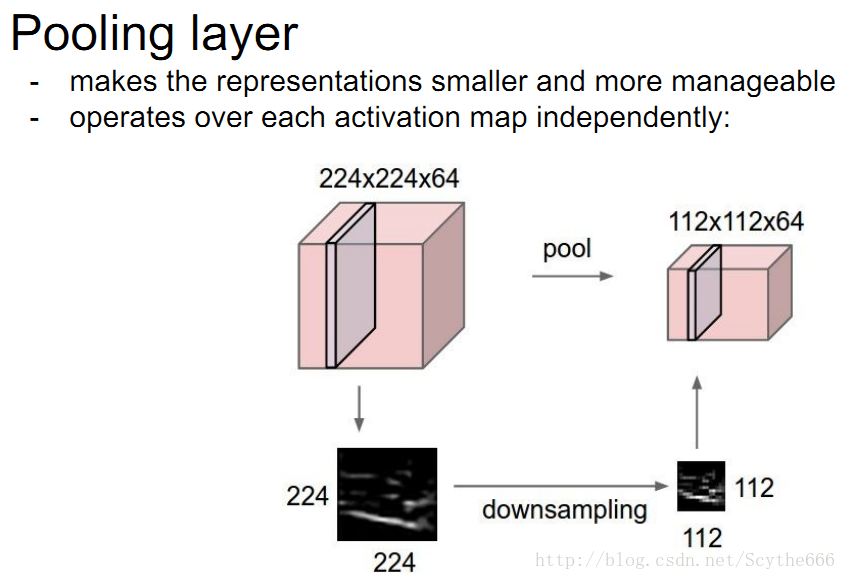
max pooling就是用几个里面的最大值代替,来进行下采样
当然也是有average pooling
这就是两种最常见的pooling技术
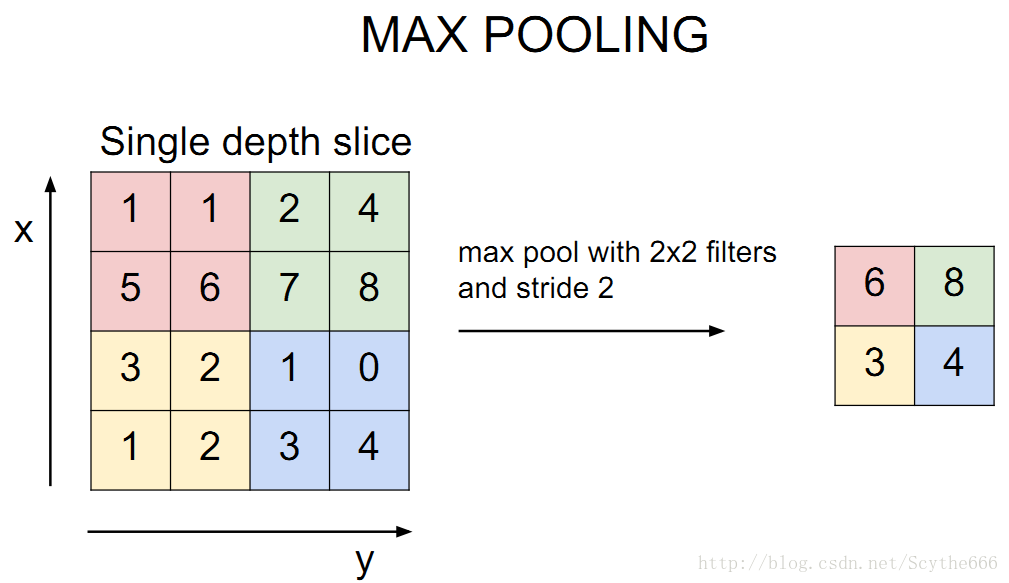
与Conv layer类似的是,pooling layer也有自己的定义,如下图

这里只有两个参数,另外有输入输出的定义
fc层就是一个neuron来计算分类得分
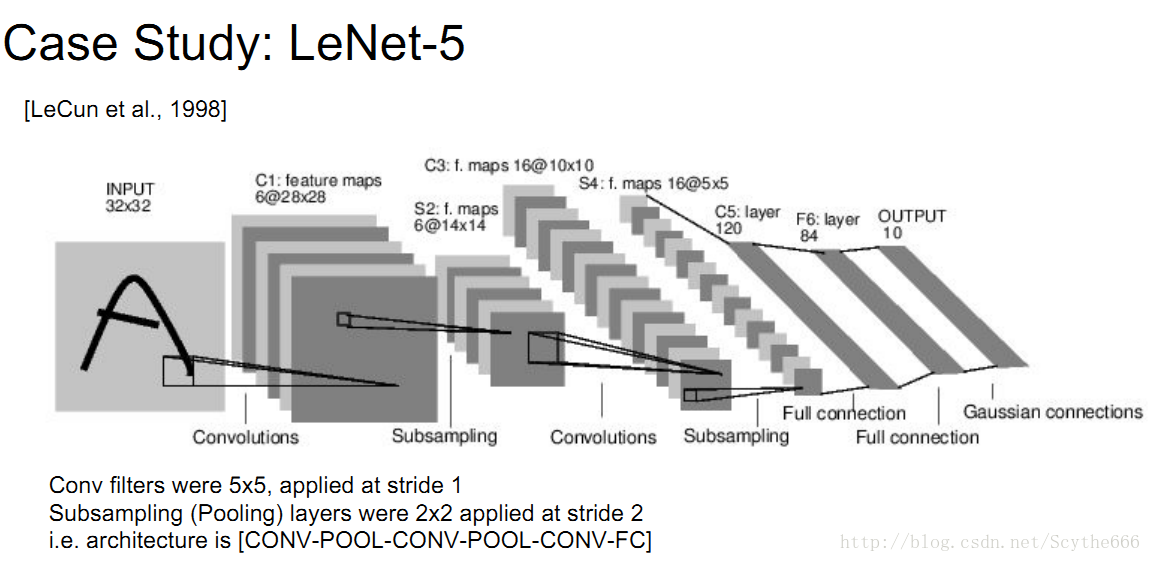
98年提出的LeNet
AlexNet,图显示不全,而且有两条路的原因是因为当时gpu发展没有那么好,就分了两个
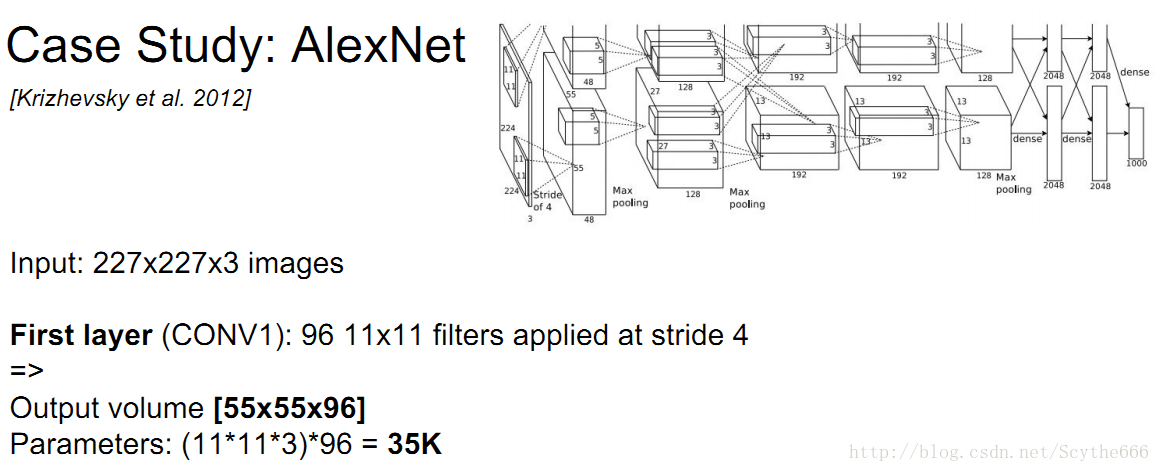
第一层应该是227,而不是224,Alex原作者说的有问题
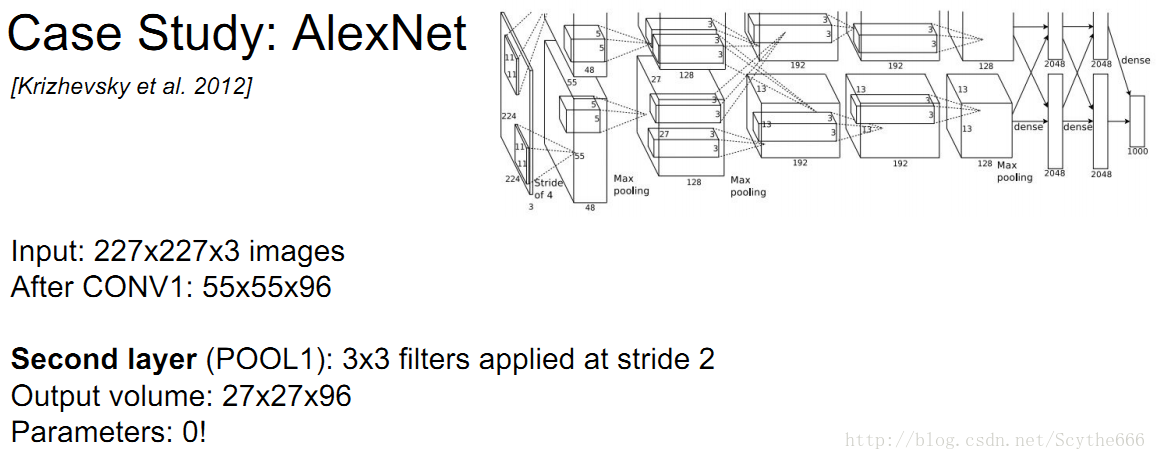
pooling layer没有参数,只有卷积层有参数
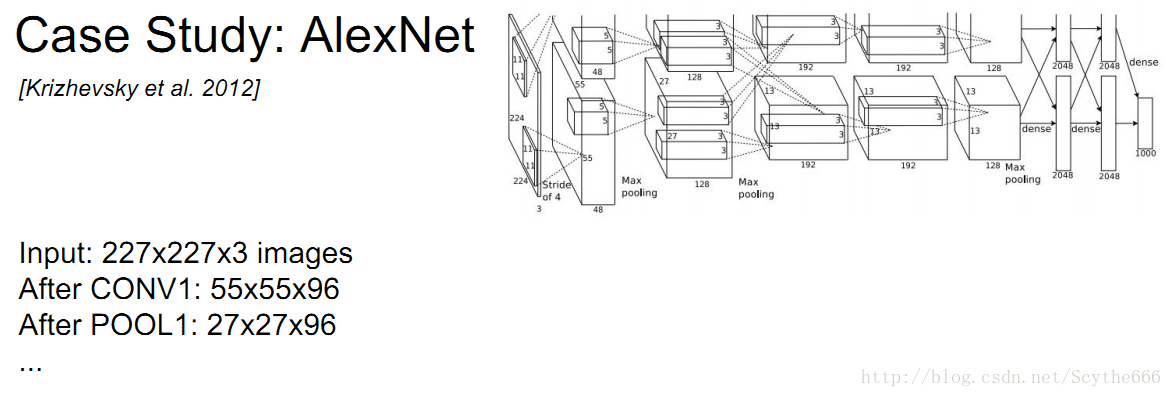
AlexNet完整的架构

依次为卷积-池化-norm,norm层是一个进行规范化的层,2012年前经常使用,现在不用了,因为对结果没有帮助
也会对整个BP
BP的时候特别注意:
因为参数共享,当用filter做卷积的时候,所有neuron共享参数,所有滤波器梯度都汇总到一个weight blob
第一次使用relu
用了data 增强,拿到图像后不是直接用,而是先预处理
用了dropout 0.5,只在最后几层用了
在监控准确率达到平台期,学习率就除以10,基本减少一两次,神经网络就收敛了
2013年冠军是ZFNet,也是在Alexnet上改进的
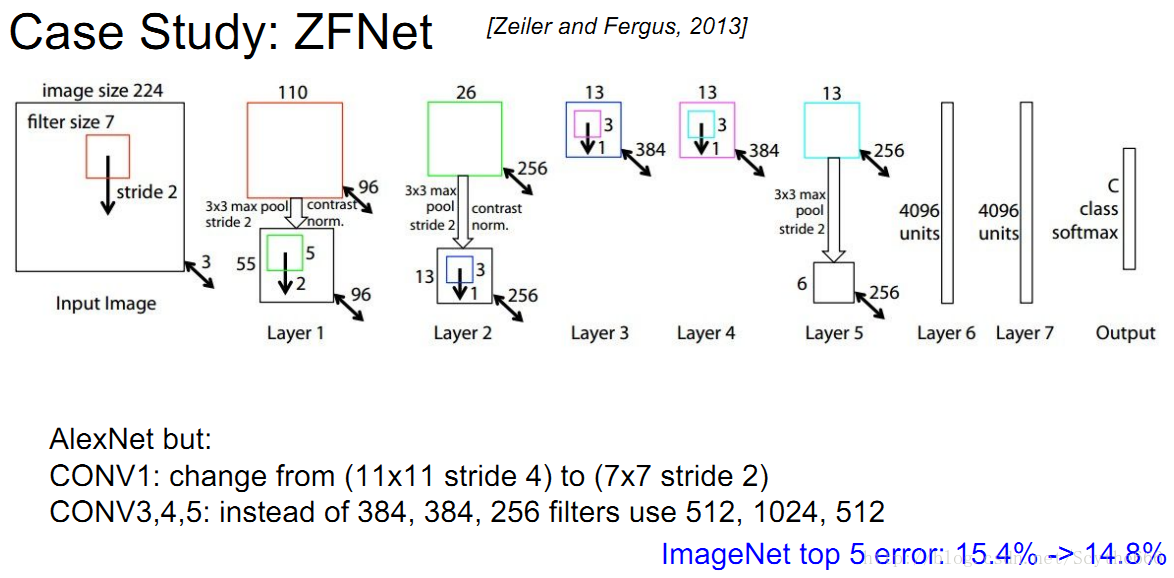
fc7已经成为一个名词:代表统计分数之前的最后一层
当然在每一个卷积层后有一个relu层
在fc层后也应该有一个relu层
2014年VGG提出,将top5 error率一下子刷到7%
全部的架构只使用 3*3 conv layer
2*2 max pooling layer
重复堆叠到16层,效果不错
架构如下图

我们注意到,过滤器在增加(更深),每个feature map在变小
224*224 —> 7*7
但是这一层深度不再是3通道,而是512个激活通道(通过512个过滤器得到)
最后是每张图片向前需要93m的内存,我们需要保存这个值,因为要做BP,回来需要update,所以要double这个值,组后是最小200m左右
内存消耗主要在前期,见下图,同时参数最多的时候在fc的时候

现在代替全链接层有—>average pooling技术
不直接全链接,而是改变他,成512个数,是通过average pooling对每个(feature map)取平均值得到512个数,效果几乎一样好,可以避免使用大量参数
GoogleNet使用这个方法
VGG有个很简单的线性结构,GoogleNet就复杂化了
其最大创新点是加入了inception module
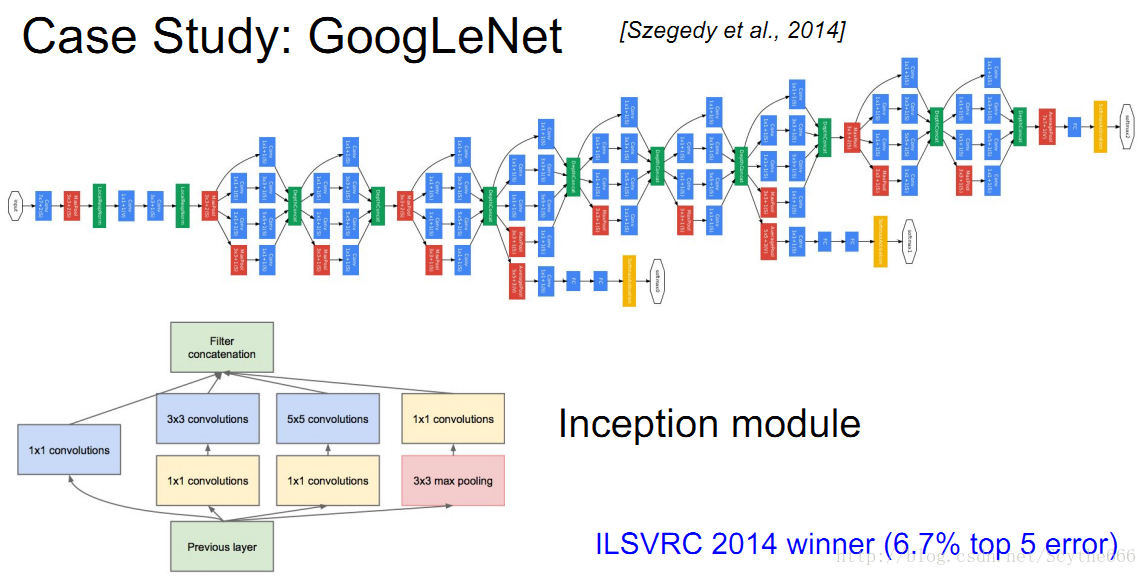
GoogleNet用inception layer取代了卷积层
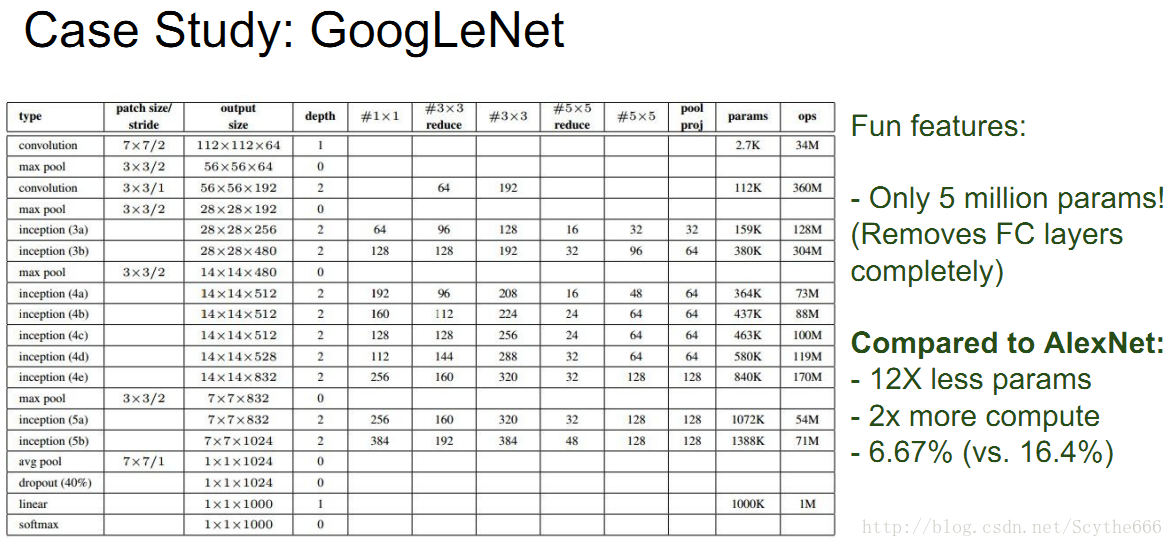
将7*7*1024降到1*1*1024
但是还是更多的人使用VGG,因为更好更统一的结构,人类的错误率差不多是5%,如果训练人可以降低到2%~3%
2015年的冠军是3.6%,来自于MSRA的residual network。
当然层数是越多越好
不过不是简单的堆叠
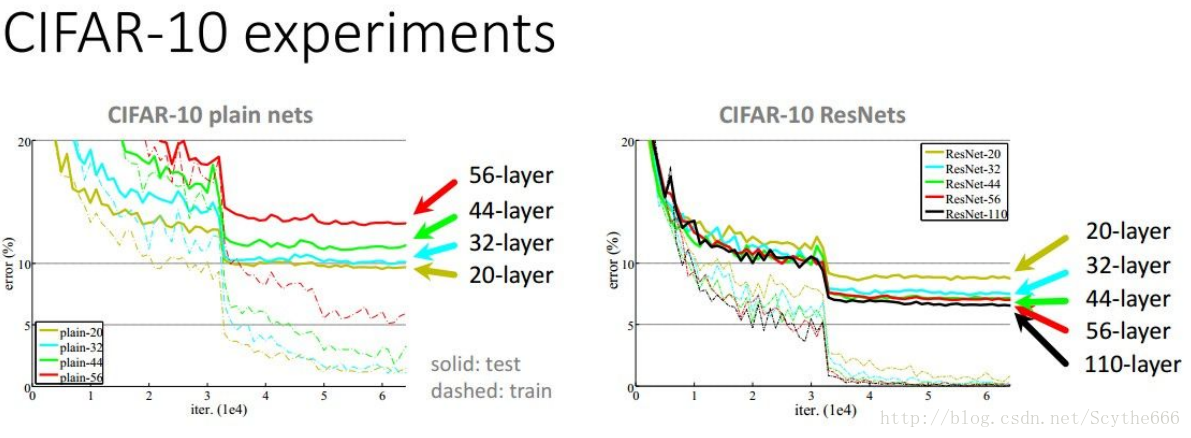
上图说明了,如果要增加层数,不要用naive方法,要用resnet方法
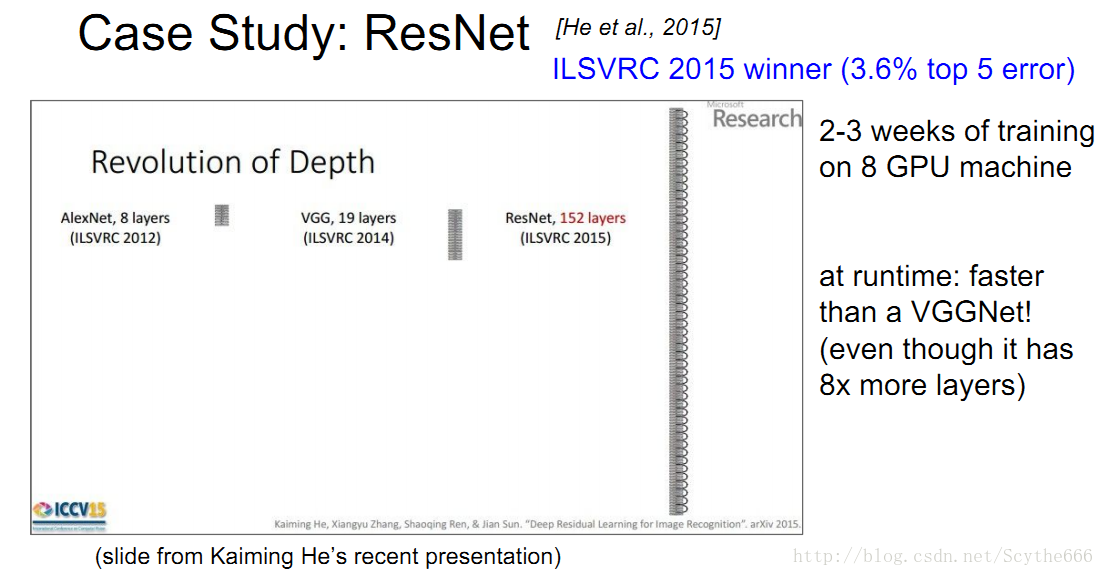
微软亚研院的resNet有152层,训练时间比较久,但是跑起来比VGGNet快
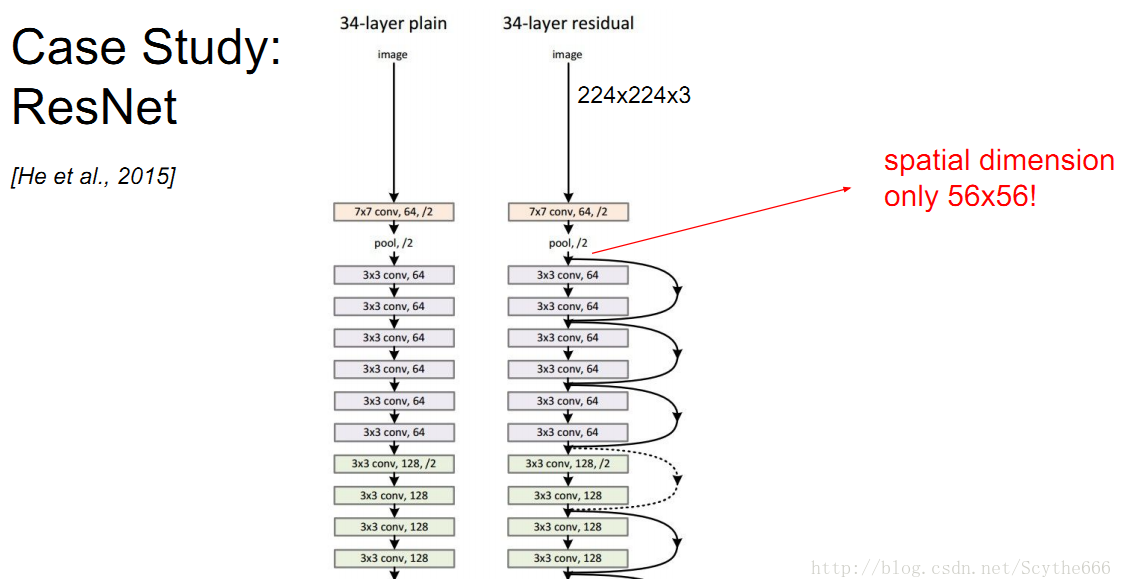
resnet,采用跳跃的连接,会通过一个大的因子压缩到一层 56*56的空间,剩下的150多层,都只作用在56*56的数组里,将很多信息打包到如此小的空间
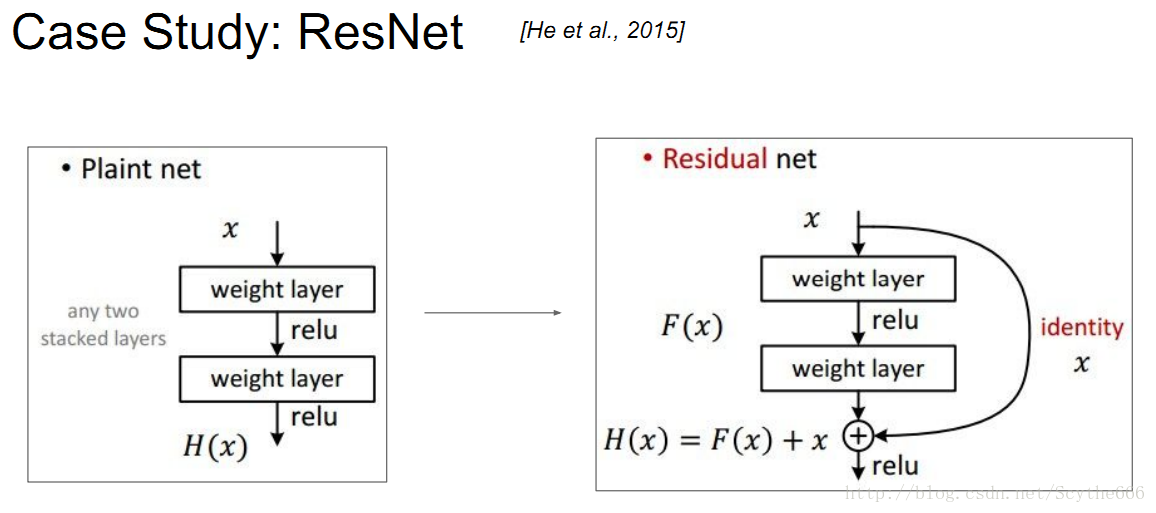
resnet的工作原理如上图,需要加上输入的残差
原因就是,加法在BP的时候,梯度是直接分发给孩子,这样跳跃的网络就可以帮助跳过很多中间层,因此可以训练一个与原图像很像的图像,中间的层可以学习如何加入信号使得更有效
如何训练一个残差网络:

Alexnet用了0.01的初始学习率,因为残差网络有batch normalization,所以可以提高一点,没有使用dropout
残差网络也不用在加上的那个部分加权,最开始可以直接对结果产生影响
第八讲:迁移学习之物体定位与检测
localization可以看作回归问题。回归就是输出一组数,而不是分类label了
选框可以用四个变量描述:左上角xy坐标+长宽
类似分类问题:也有前向传播+BP
loss可以选用标准的欧式距离loss
一个简单的定位+分类recipe(固定种类)

pre-train就是先前有训练的模型
简单来说就是分别输出框和分类结果
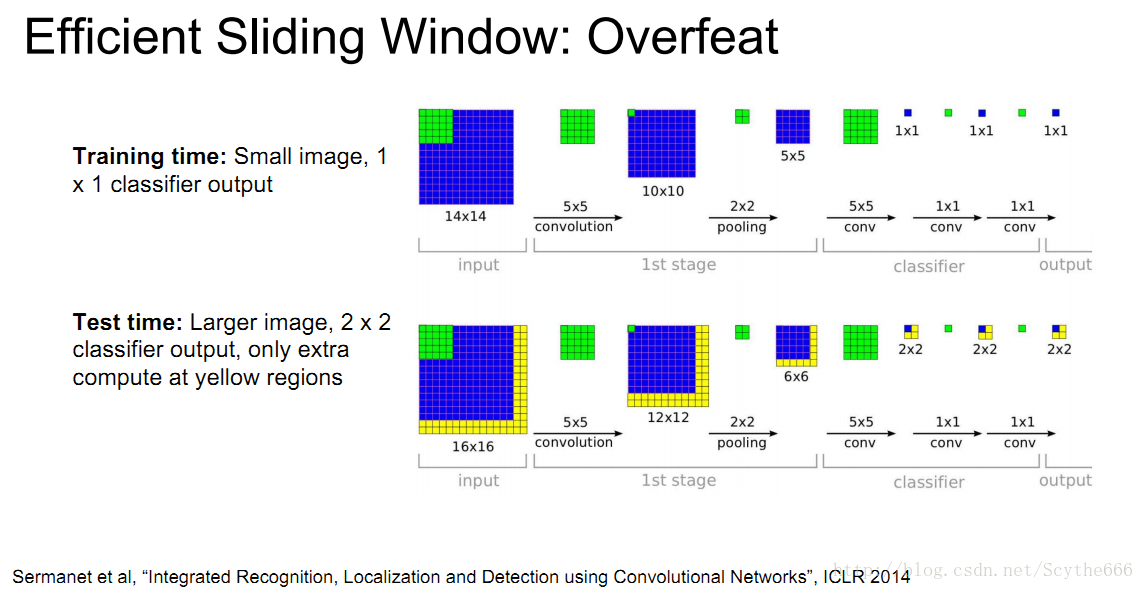
sliding window:overfeat
如果想识别图中的物体,通常还有一种做法就是尝试各种不同的框
重复上面的定位+分类操作,再将不同位置的结果进行聚合
将全连接层视为一个conv层
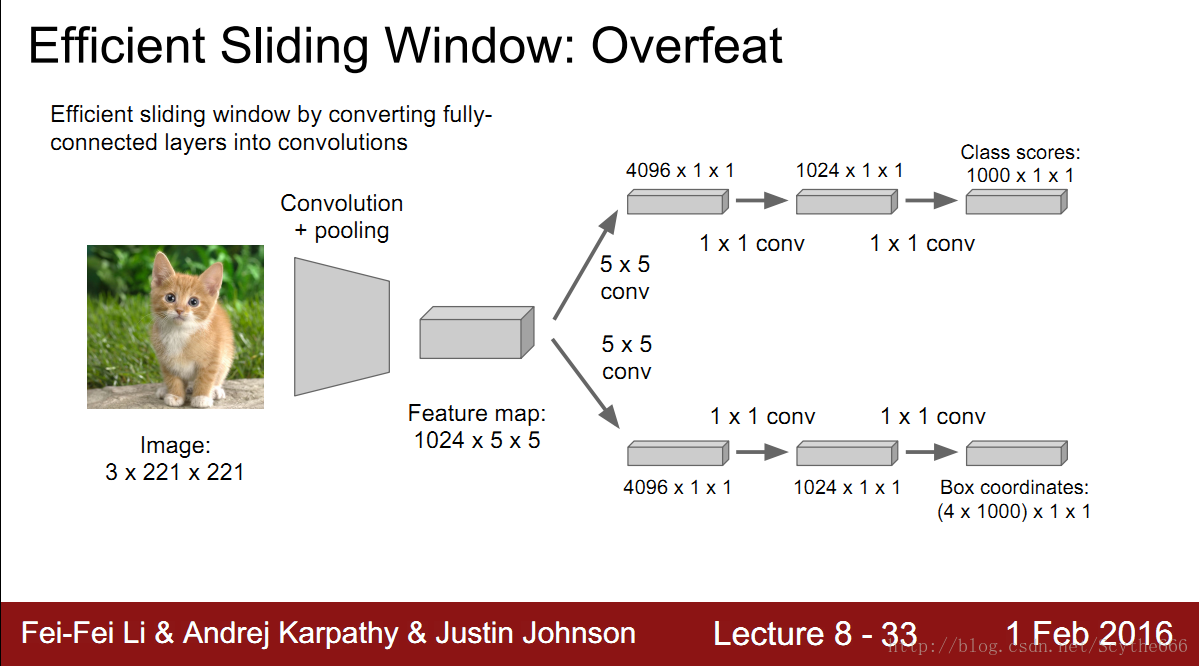
如上图的5*5*1024 —> 被个4096个5*5的核conv
这样就统一了计算,大大减少计算量
微软2015年没有靠的不只是更深层的特征,而是发明了RPN—Region Proposal Network
L2 loss 有极端值的问题,L1没有,所以可以用L1
有时有人会同时训练回归与分类;有时分开
object detection
输出的数量不定,也可以用不同的区域不停的试,试不同大小的窗口
加入两个新东西:
(1)可以加入一个背景类,代表啥都没有;
(2)多标签分类,不用softmax loss,而是用独立的回归loss,多个类可能在同一个点上
hog是用线性分类器,方向梯度直方图,DPM类似CNN
当然不可能尝试出所有的区域,所以用region proposal算法

输出可能含有物体的区域,不关心具体类别,只是告诉这个区域可能有物体,很快。在图像中找整块的区域
最著名的Region proposal算法有selective search — 将类似颜色+纹理进行融合成框,再用这些合成的框进行检测
讲者推荐edgebox
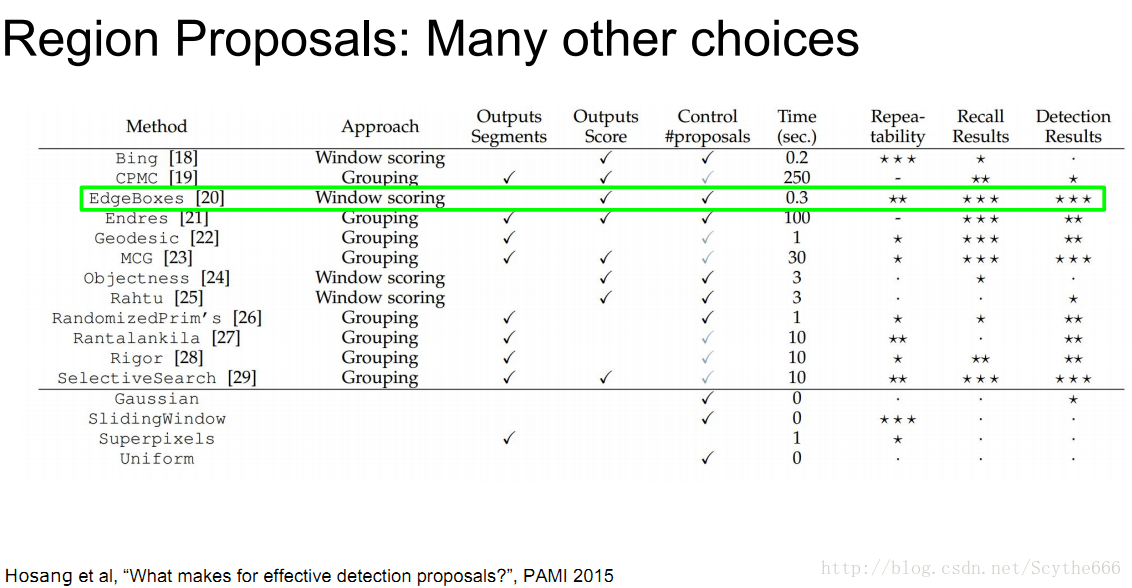
很快,1/3s一张图
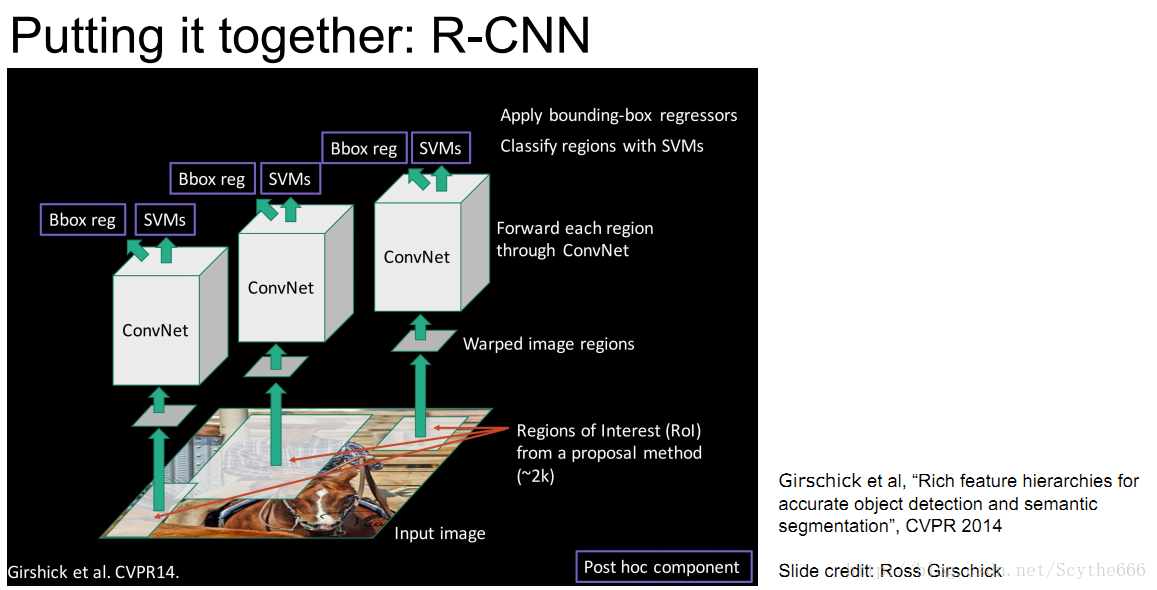
R-CNN Region based CNN
有了Region Proposal,有了CNN,就有了R-CNN
step1:运行selective search 到大噶2k个不同大小、不同位置的框
step2:每个框剪裁出来,调整到固定大小
step3:cnn分类 —> cnn网络分别连接回归端+SVM分类端,回归端可以对目标框进行纠正
R-CNN Training 过程
step1:下载一个已有的对于imageNet数据集分类的模型比如Alexnet
step2:finetune用于检测,因为原模型是用于1000类分类的,可以在后面加上几层用于分类自己的数据
step3:提取特征,存在磁盘上—对于每张图片,运行selective search 算法,送到CNN,把特征存在磁盘
step4:训练二分类SVM,回答是否包含特定物体
step5:box的回归,希望从特征推回到box,有特征+目标==训练线性回归
测试标准

缺点:训练有点麻烦,且费内存,慢,离线操作(不能update)
Fast R-CNN
swap提取出的区域再运行CNN,类似与overfeat滑动窗口
先高分辨率图像输入,卷积,得到高分辨率卷积特征
再用Region Proposal的方法, 即ROI分离区域特征
投入全连接层
用分类端+回归端
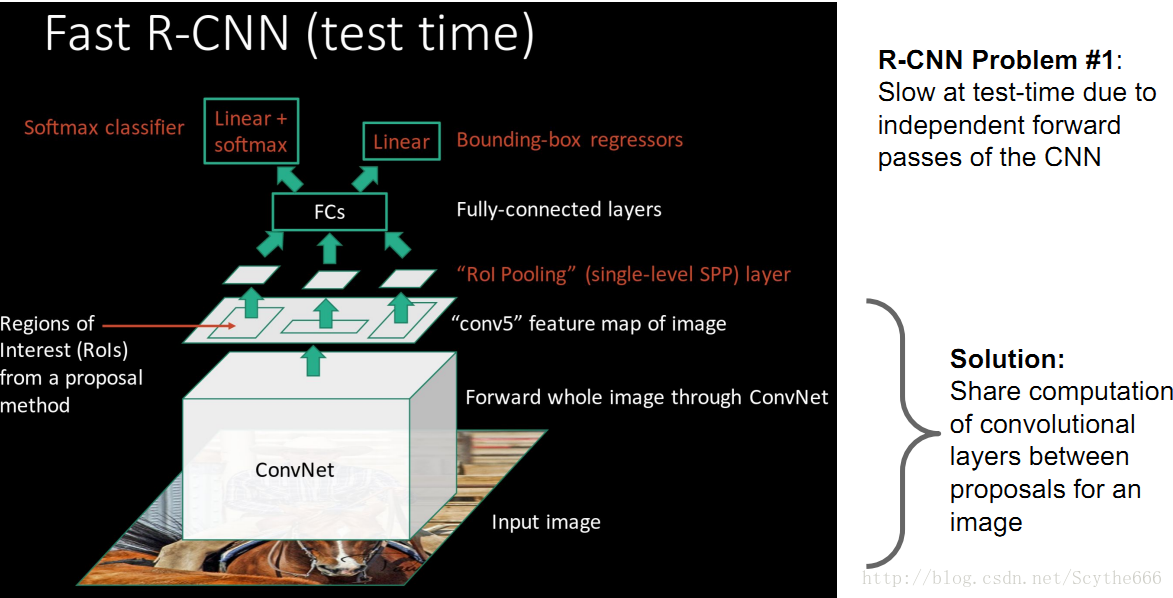
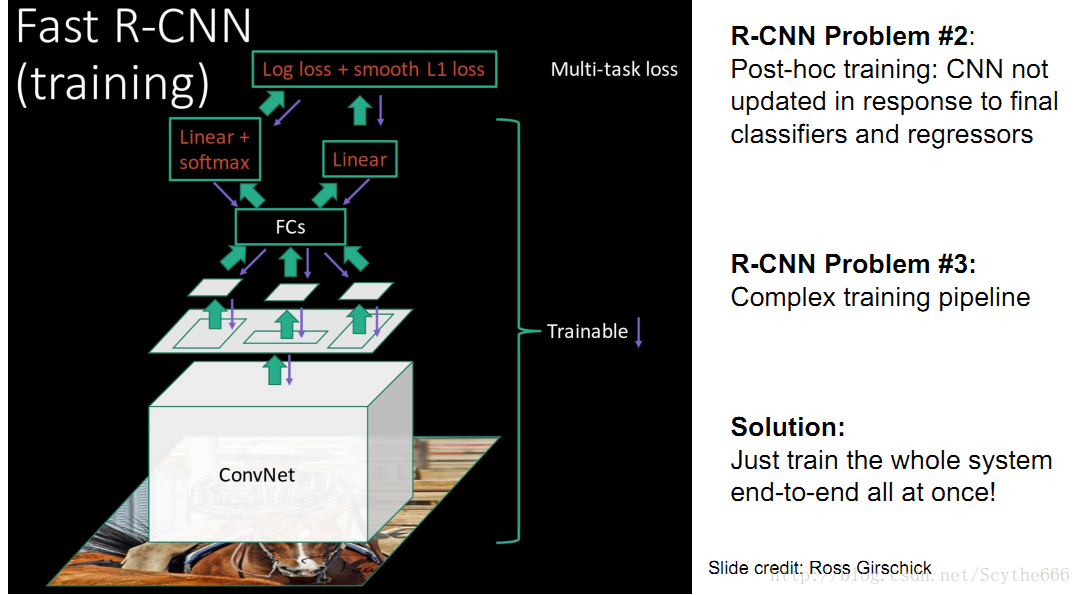
解决了R-CNN在test和train时候的问题
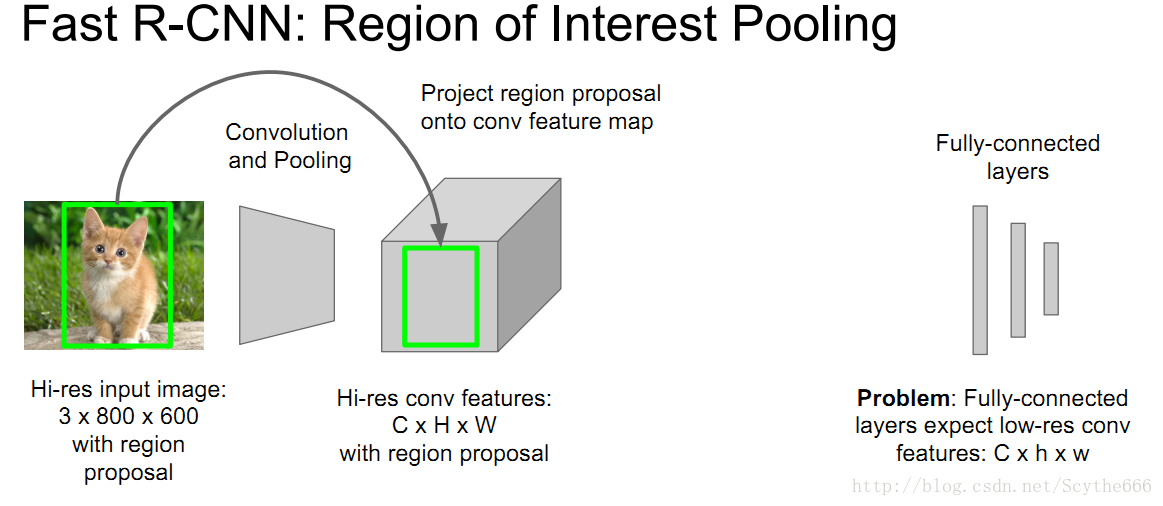
Region of Interest Pooling
给出目标框,投影到conv feature空间,将conv feature分成小块
再做max pooling,这样也是可以BP
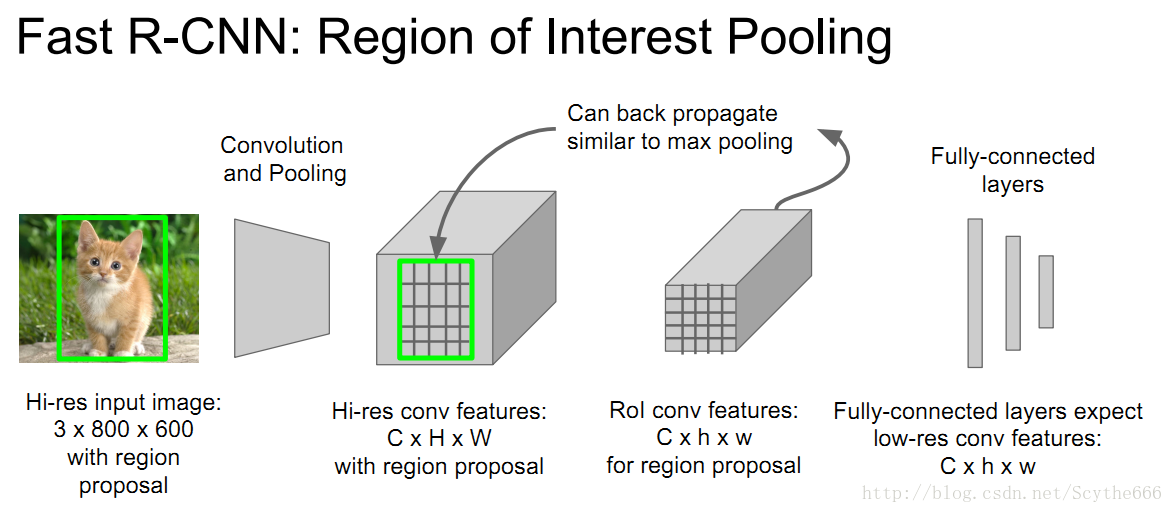
为什么不用CNN做Region Proposal呢
Faster R-CNN
不用推荐区域的卷积,而是整张图片卷积,使用RPN Region Proposal Network
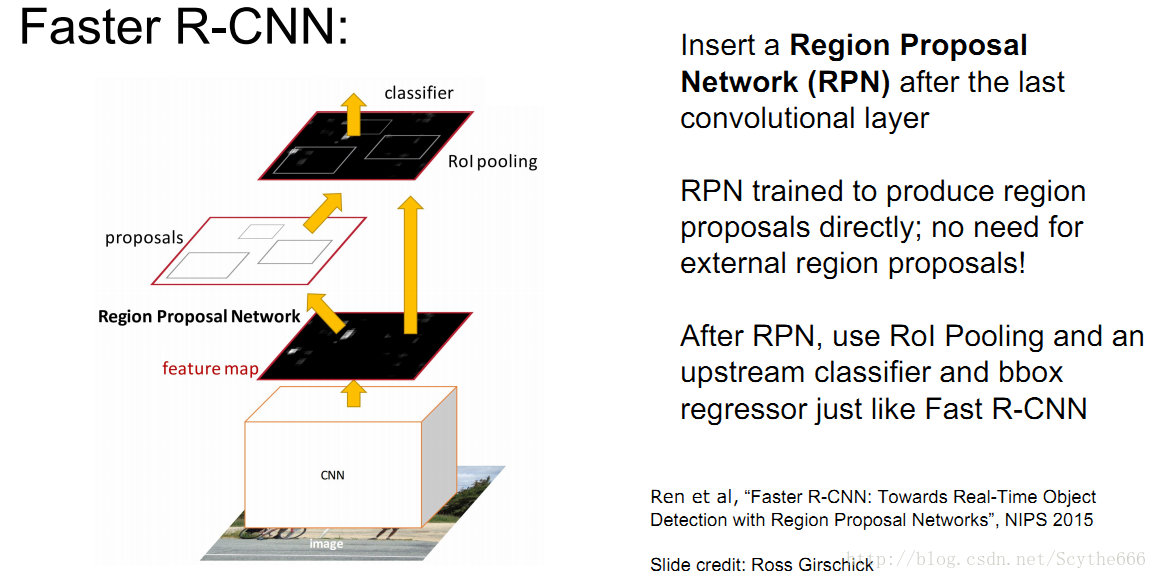


做了和fast-RCNN相反的事情,用anchor框对特征图进行滑动,映射回原图像,特征图谱上的点和原图像有关联,用这个就减少了计算量

原论文将RPN与Fast-RCNN训练重合了,这样就节省了很大的计算量
对于Faster的区域推荐只用通过一个3*3和一些1*1的卷积核,计算量很小,就基本不用花什么时间了
速度对比:

授课时(2016.1)最好的组合还是 resNet101+faster RCNN
one-stage方法
YOLO:you only look once
将检测问题直接当作回归来做
分离空间网格,他们7*7,对于网格中的每个元素,我们得到固定数目的bounding boxes,他们大部分实验用B=2个
每个grid,预测2个B bounding boxes — 也就是4个数,还要预测一个score来表示可信度
现在还有SSD做实时的
问题:模型输出数有限,速度快,但是不准,于是有fast YOLO
Object Detection 代码:
R-CNN
(Cafffe + MATLAB): https://github.com/rbgirshick/rcnn
Probably don’t use this; too slow
Fast R-CNN
(Caffe + MATLAB): https://github.com/rbgirshick/fast-rcnn
Faster R-CNN
(Caffe + MATLAB): https://github.com/ShaoqingRen/faster_rcnn
(Caffe + Python): https://github.com/rbgirshick/py-faster-rcnn
YOLO
http://pjreddie.com/darknet/yolo/
Maybe try this for projects?
第九讲:卷积神经网络的可视化与进一步理解
conv层weights(过滤器)如下
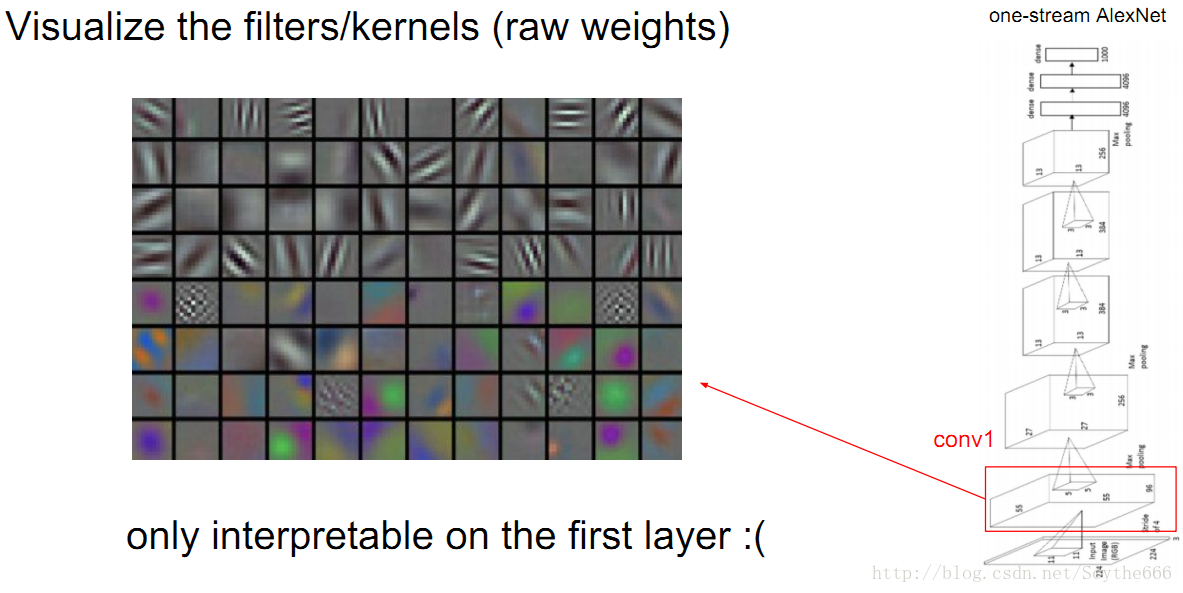
可视化只能在第一层做,跟原图有关
t-SNE对高维数据自动聚类,详见:http://bindog.github.io/blog/2016/06/04/from-sne-to-tsne-to-largevis/
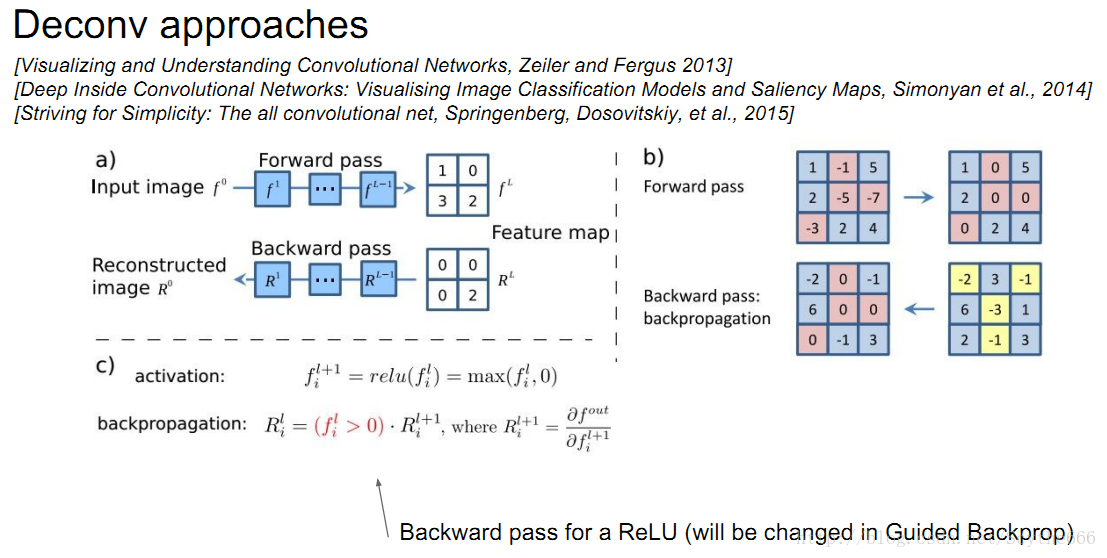
整个神经网络可微才能够计算梯度
要想计算特定神经元的梯度,将这个神经元设定梯度为1.00,然后其余的设定为0,做BP
用解析梯度法而不用数值梯度法的原因是,数值法更慢
对于一个任意的神经元,他的梯度并不是很容易看出是什么,有个deconv的方法 guided BP
relu是阻断为负数的BP
guided BP—只传递正数的梯度的部分,用relu;并且还阻断梯度为负数的
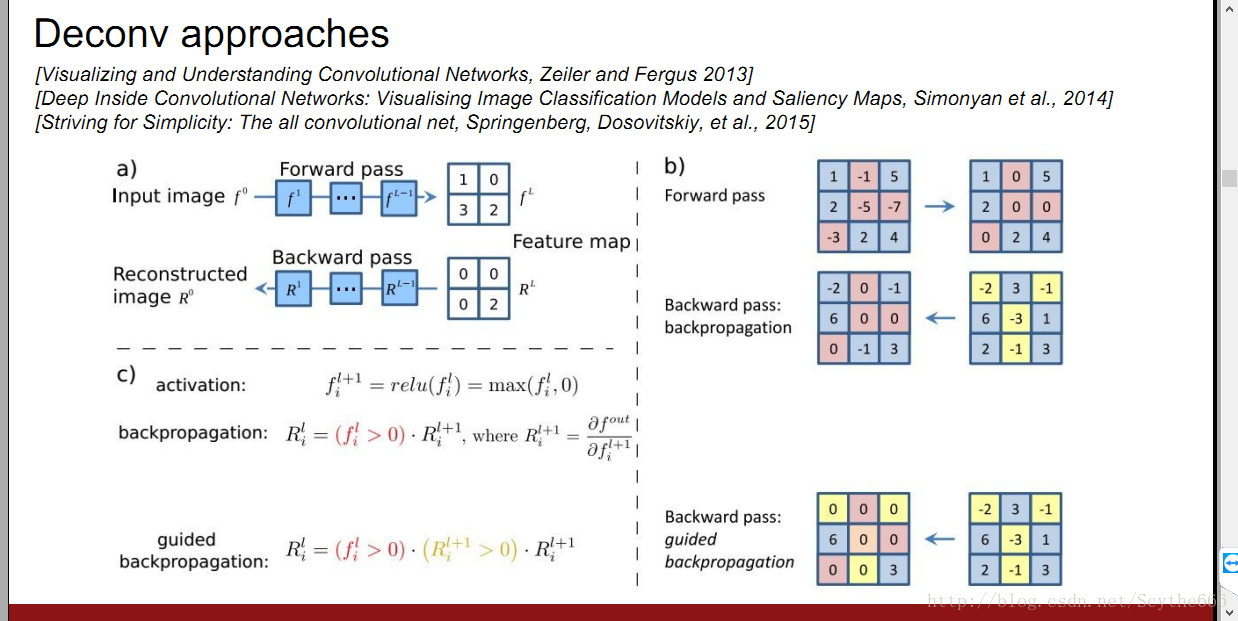
只通过有正影响的,不通过有负影响的
普通的看起来不明显的原因,是因为每个像素点到目标神经元的影响有正有负,在GBP的只通过正值,就能看到清晰的图片
Optimization to Image
另外通过优化的方法,对某一类物体尽可能高的提高得分,最大程度的激活网络中某些单元的图像

无论梯度正负,只取最大值效果,不考虑符号
暗色的地方说明:这块地方出现的东西,神经网络不care对结果的影响,但是如果改变白色部分,就会影响结果
开始的时候,kernel很小,比如3*3,但是后面层的像素对结果的影响就可以组合了,变大很多,所以在底层就是一些片段的组合,但是到高层了会成团,到高层之后一个neuron就可能是整张图片的函数了
DeepDream https://github.com/google/deepdream
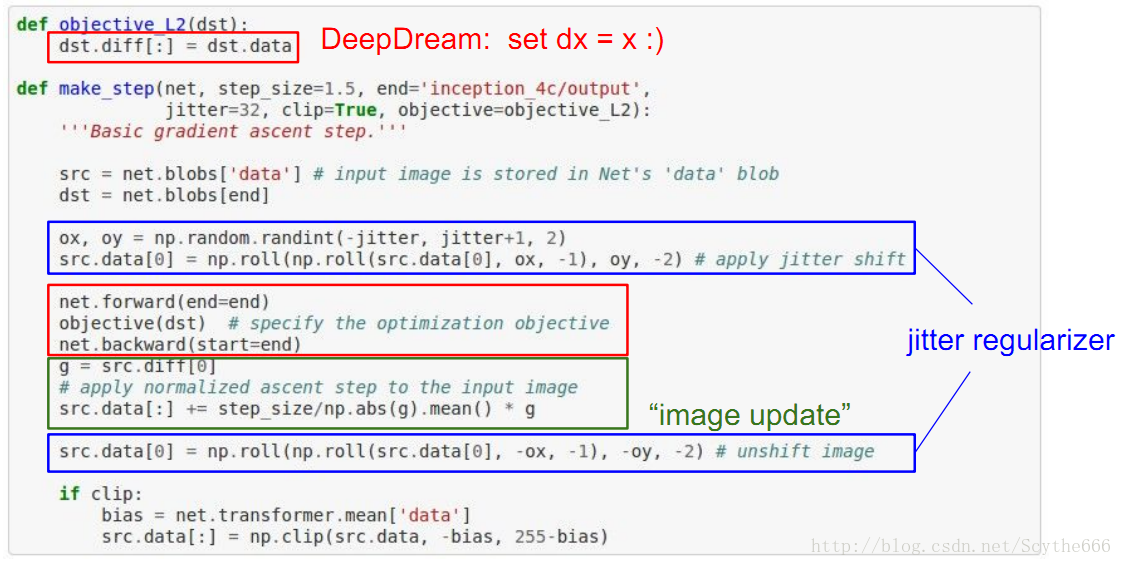
增强跟目标相似的东西,做BP增强原图
因为数据中狗很多,所以整个网络比较关注狗的特征
损失要和这里的激活匹配,比如激活和放进甘道夫的激活类似
如何去fool一个分类器
其实可以将一张图“变成”另外一张图,对于分类器来说。
在高层中将梯度设置成另一个类别,然后反向传播,得到原图像的改变

只是把像素向置信度高的方向移动一点点,对于分类器来说就成了另一张图,这是因为前向传播中的函数线性的特点,因为在网络的顶端加了一个线性分类器,对于高维空间,只需要对每个维度顺着结果递增的梯度方向做微小改变,这个分类器就会被fool。
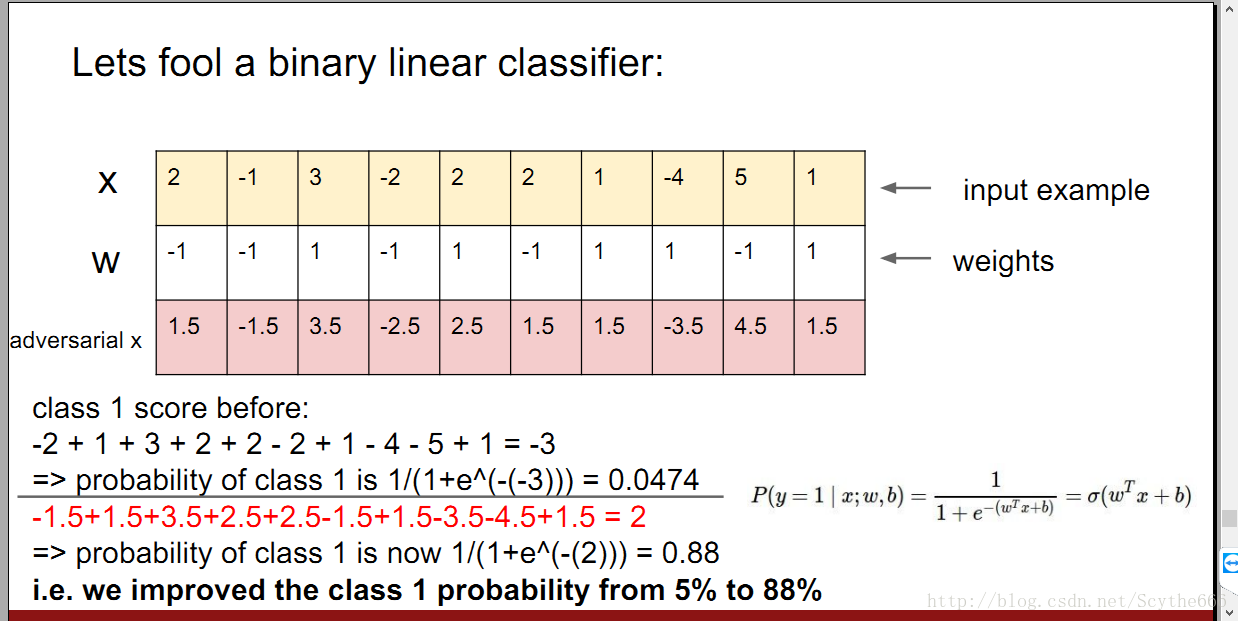

对抗样本(adversarial example)—这是一种脆弱性,这和图像也没关,任何data都可以做对抗样本,目前没有好的解决方法,是一个好的课题
如果人脸识别被做对抗样本就可以变成任意一个人
第十讲、RNN
RNN因为是不同做重复操作:
所以结果容易要么爆炸,要么消失
小技巧控制梯度爆炸:如果梯度大于5,就逐元素裁剪为5 — 梯度裁剪
- RNN有梯度弥散问题
- LSTM能很好的抑制梯度弥散,因为高速细胞只改变了加法运算,不会消失,每次都乘以相同的矩阵
第十一讲、cnn实战
data augmentation
- 翻转是最常见的augment
random crops
test的时候,10-crops
上下左右中*2(水平翻转),这十个位置得分取均值
颜色改变,如:对比度,但并不一定常见;还可以对每个像素做PCA主成分分析,遍历所有像素后得到训练集中的主要颜色有哪些,PCA给出颜色空间中3个主要颜色在哪个方向中变化最剧烈
防止过拟合,可以在forward的时候加一些随机扰动,比如augment就是一种;还可以dropout+dropconnect;还有Batch Normalization(任一张图片,因为在不同的batch中,会不同,相当于引入了随机噪声)
transfer learning
1、如果自己训练数据真的很少,可以把pre-trained的网络,当作一个特征提取器,只train最后一层
2、对于从scratch开始学的层:一般学习率较高,但也不能太高(比如原来网络的1/10);对于finetune的层:就需要更小的learning rate(比如原来的1/100)
3、一般情况下,用同类型的训练数据好,但是前几层的feature很general,几乎所有的图像数据都需要,所以不用太担心
4、finetune步骤:
step1. 把网络固定,只train后面几层
step2. 当最后几层快收敛之后,再对中间层微调

一般来说都不应该从scratch开始训练,多用finetuning,除非有很大很大dataset
5、(1)三层3*3的layer叠起来,一个neuron可以看到多大
5*5
(2)三个加起来呢?
7*7
(3)参数数量比较

(4)浮点运算量比较
更深的网络,更少的计算就有更强的非线性

6、bottleneck技巧—channel方向减半
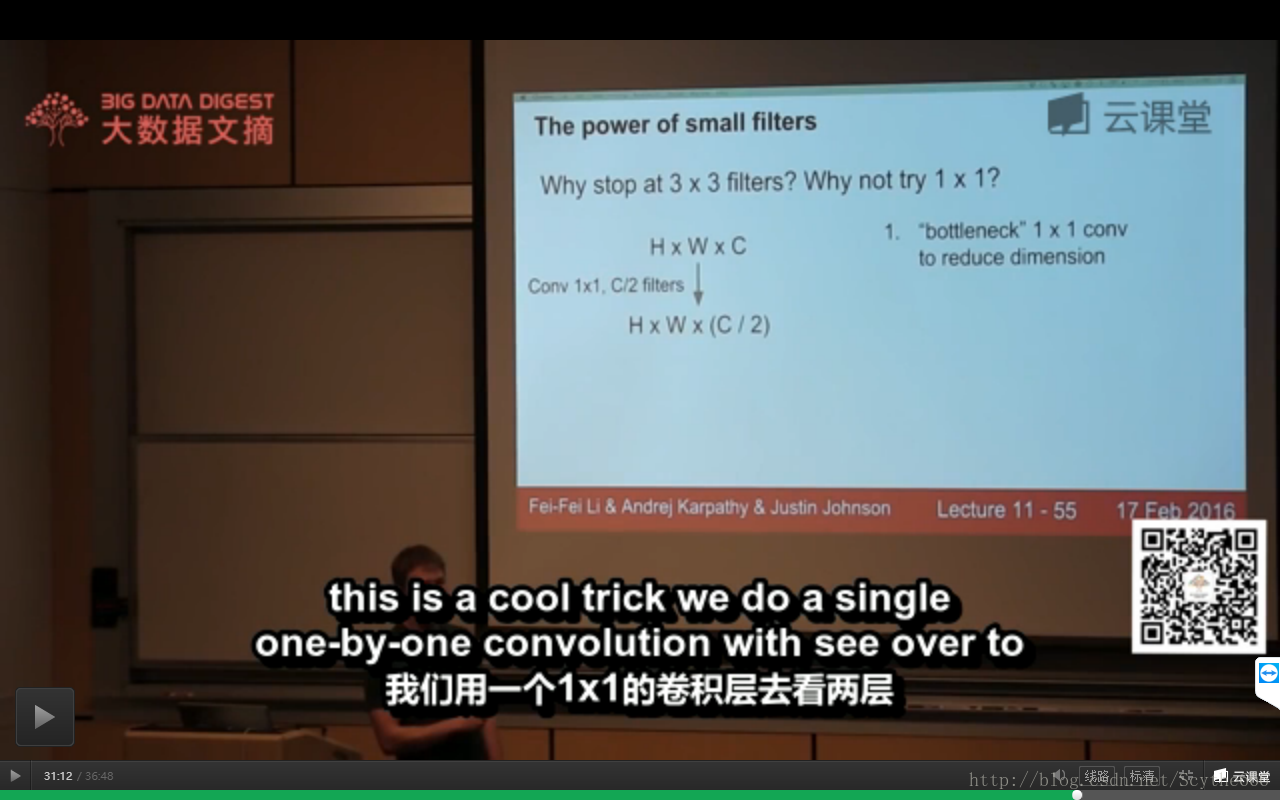
这样空间上尺寸一样,但是深度方向上特征数减半

代替全连接层

将3*3变成3*1+1*3

甚至可以将bottleneck与这种breakdown结构结合起来,Googlenet就有这么做(rethink那篇)
7、将大的核分解成小的,会更有效率
- 参数更少
- 计算量更小
- 非线性更强

如何快速计算卷积
可以拉成矩阵操作,BP也可以用矩阵操作
在计算的时候可以用FFT(快速傅里叶变换)

第十二讲、开源库简介
caffe
四种主要的类
blob
n维张量,存储网络中所有的数据(比如像素值、label)、权重、activations
内部有4个n维张量:raw data,diffs(保存梯度),上面两个各有cpu核gpu版本
layer
forward时:接受blob,bottom输入,top输出
BP时:layer实现BP,与上面相反
net
把许多层联系在一起,Net是layer的有向非循环图
描述layer的连接,不用自己去修改代码
solver
进入net,更新网络的参数
不同的更新规则,比如Adam

caffe.proto
类json,用于序列化
定义了caffe中用到的所有 proto buffer种类
可以作为说明书来读
caffe训练步骤

读入数据的方式
train_val的重要点

.caffemodel里面其实是用键值对的形式存储,但是是二进制存储(与layer名匹配),所以看不到
如果layer名匹配,就从pre-train初始化,否则从scratch
还可以在不同阶段用不同的solver来调参
caffe的优缺点

tensorflow
与theano很像
tensorboard,可以实时看到图形


讲者给的建议

第十三讲、attention
spacial transform network
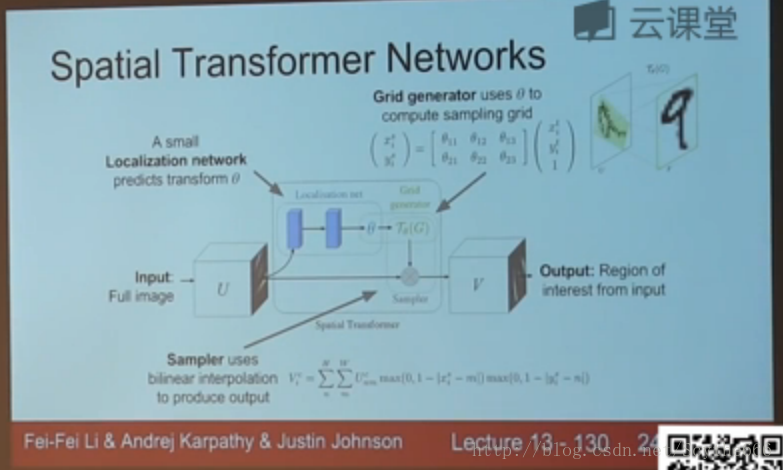
空间转换模块 — 放到其他网络中,可以attention
详见:https://www.youtube.com/watch?v=Ywv0Xi2-14Y

第十四讲、unsupervised learning
生成对抗样本—生成图片
- Autoencoders
- gan(Generative Adversarial Nets)
三、cs231n笔记
之所以将note部分单独列出来,是希望不破坏之前听课的笔记完整性,同时笔记部分有很多需要另记。
image classification notes
python介绍那章就直接skip了
Nearest Neighbor分类器
对于NN分类器有两种计算距离的方法,L1和L2
(1)L1距离,即逐个像素比较

例子如下:
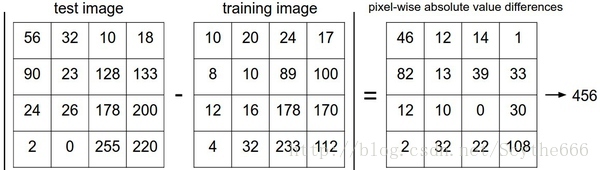
(2)L2距离,从几何学的角度,可以理解为它在计算两个向量间的欧式距离。

L1和L2比较。比较这两个度量方式是挺有意思的。在面对两个向量之间的差异时,L2比L1更加不能容忍这些差异。也就是说,相对于1个巨大的差异,L2距离更倾向于接受多个中等程度的差异。L1和L2都是在p-norm常用的特殊形式。
k-Nearest Neighbor分类器
上面两种分类器不好的原因:
为什么只用最相似的1张图片的标签来作为测试图像的标签呢?这不是很奇怪吗
KNN原理:
使用k-Nearest Neighbor分类器就能做得更好。它的思想很简单:与其只找最相近的那1个图片的标签,我们找最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。所以当k=1的时候,k-Nearest Neighbor分类器就是Nearest Neighbor分类器。从直观感受上就可以看到,更高的k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。
KNN也有一个问题,因为很容易被背景主导,而不是图片本身的语义。

CS231n课程笔记翻译:线性分类笔记
将图像看做高维度的点:既然图像被伸展成为了一个高维度的列向量,那么我们可以把图像看做这个高维度空间中的一个点(即每张图像是3072维空间中的一个点)。整个数据集就是一个点的集合,每个点都带有1个分类标签。
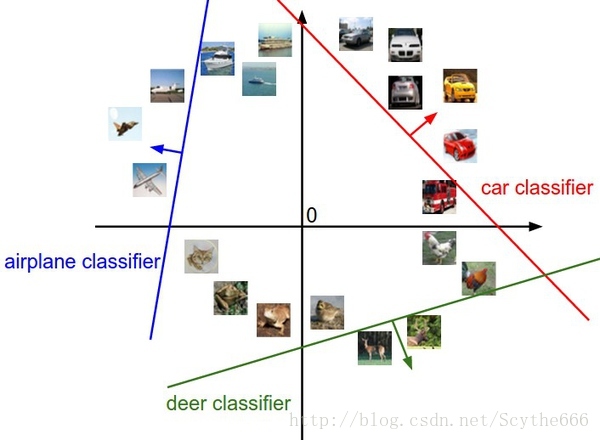
既然定义每个分类类别的分值是权重和图像的矩阵乘,那么每个分类类别的分数就是这个空间中的一个线性函数的函数值。我们没办法可视化3072维空间中的线性函数,但假设把这些维度挤压到二维,那么就可以看看这些分类器在做什么了:
这里关于3072维度要说一点,因为每张图有3072个值,每个值都是一个数,对应到3072维度的一个点,当然都是在0~255
图像空间的示意图。其中每个图像是一个点,有3个分类器。以红色的汽车分类器为例,红线表示空间中汽车分类分数为0的点的集合,红色的箭头表示分值上升的方向。所有红线右边的点的分数值均为正,且线性升高。红线左边的点分值为负,且线性降低。
W的每一行都是一个分类类别的分类器。对于这些数字的几何解释是:如果改变其中一行的数字,会看见分类器在空间中对应的直线开始向着不同方向旋转。而偏差b,则允许分类器对应的直线平移。需要注意的是,如果没有偏差,无论权重如何,在x_i=0时分类分值始终为0。这样所有分类器的线都不得不穿过原点。这当然不对了
将线性分类器看做模板匹配:关于权重W的另一个解释是它的每一行对应着一个分类的模板(有时候也叫作原型)。一张图像对应不同分类的得分,是通过使用内积(也叫点积)来比较图像和模板,然后找到和哪个模板最相似。从这个角度来看,线性分类器就是在利用学习到的模板,针对图像做模板匹配。从另一个角度来看,可以认为还是在高效地使用k-NN,不同的是我们没有使用所有的训练集的图像来比较,而是每个类别只用了一张图片(这张图片是我们学习到的,而不是训练集中的某一张),而且我们会使用(负)内积来计算向量间的距离,而不是使用L1或者L2距离。

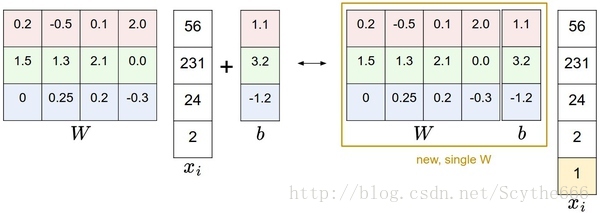
偏差和权重的合并技巧:在进一步学习前,要提一下这个经常使用的技巧。它能够将我们常用的参数W和b合二为一。回忆一下,分类评分函数定义为:
f(x_i,W,b)=Wx_i+b
分开处理这两个参数(权重参数W和偏差参数b)有点笨拙,一般常用的方法是把两个参数放到同一个矩阵中,同时x_i向量就要增加一个维度,这个维度的数值是常量1,这就是默认的偏差维度。这样新的公式就简化成下面这样:
f(x_i,W)=Wx_i
还是以CIFAR-10为例,那么x_i的大小就变成[3073x1],而不是[3072x1]了,多出了包含常量1的1个维度)。W大小就是[10x3073]了。W中多出来的这一列对应的就是偏差值b,具体见下图:
————————————————————————————————————————
偏差技巧的示意图。左边是先做矩阵乘法然后做加法,右边是将所有输入向量的维度增加1个含常量1的维度,并且在权重矩阵中增加一个偏差列,最后做一个矩阵乘法即可。左右是等价的。通过右边这样做,我们就只需要学习一个权重矩阵,而不用去学习两个分别装着权重和偏差的矩阵了。
图像数据预处理:在上面的例子中,所有图像都是使用的原始像素值(从0到255)。在机器学习中,对于输入的特征做归一化(normalization)处理是常见的套路。而在图像分类的例子中,图像上的每个像素可以看做一个特征。在实践中,对每个特征减去平均值来中心化数据是非常重要的。在这些图片的例子中,该步骤意味着根据训练集中所有的图像计算出一个平均图像值,然后每个图像都减去这个平均值,这样图像的像素值就大约分布在[-127, 127]之间了。下一个常见步骤是,让所有数值分布的区间变为[-1, 1]。零均值的中心化是很重要的,等我们理解了梯度下降后再来详细解释。
在上一节定义了从图像像素值到所属类别的评分函数(score function),该函数的参数是权重矩阵W。在函数中,数据(x_i,y_i)是给定的,不能修改。但是我们可以调整权重矩阵这个参数,使得评分函数的结果与训练数据集中图像的真实类别一致,即评分函数在正确的分类的位置应当得到最高的评分(score)。
回到之前那张猫的图像分类例子,它有针对“猫”,“狗”,“船”三个类别的分数。我们看到例子中权重值非常差,因为猫分类的得分非常低(-96.8),而狗(437.9)和船(61.95)比较高。我们将使用损失函数(Loss Function)(有时也叫代价函数Cost Function或目标函数Objective)来衡量我们对结果的不满意程度。直观地讲,当评分函数输出结果与真实结果之间差异越大,损失函数输出越大,反之越小。
多类支持向量机损失 Multiclass Support Vector Machine Loss
损失函数的具体形式多种多样。首先,介绍常用的多类支持向量机(SVM)损失函数。SVM的损失函数想要SVM在正确分类上的得分始终比不正确分类上的得分高出一个边界值\Delta。我们可以把损失函数想象成一个人,这位SVM先生(或者女士)对于结果有自己的品位,如果某个结果能使得损失值更低,那么SVM就更加喜欢它。
让我们更精确一些。回忆一下,第i个数据中包含图像x_i的像素和代表正确类别的标签y_i。评分函数输入像素数据,然后通过公式f(x_i,W)来计算不同分类类别的分值。这里我们将分值简写为s。比如,针对第j个类别的得分就是第j个元素:s_j=f(x_i,W)_j。针对第i个数据的多类
SVM的损失函数定义如下:
L_i=\sum_{j\not=y_i}max(0,s_j-s_{y_i}+\Delta)
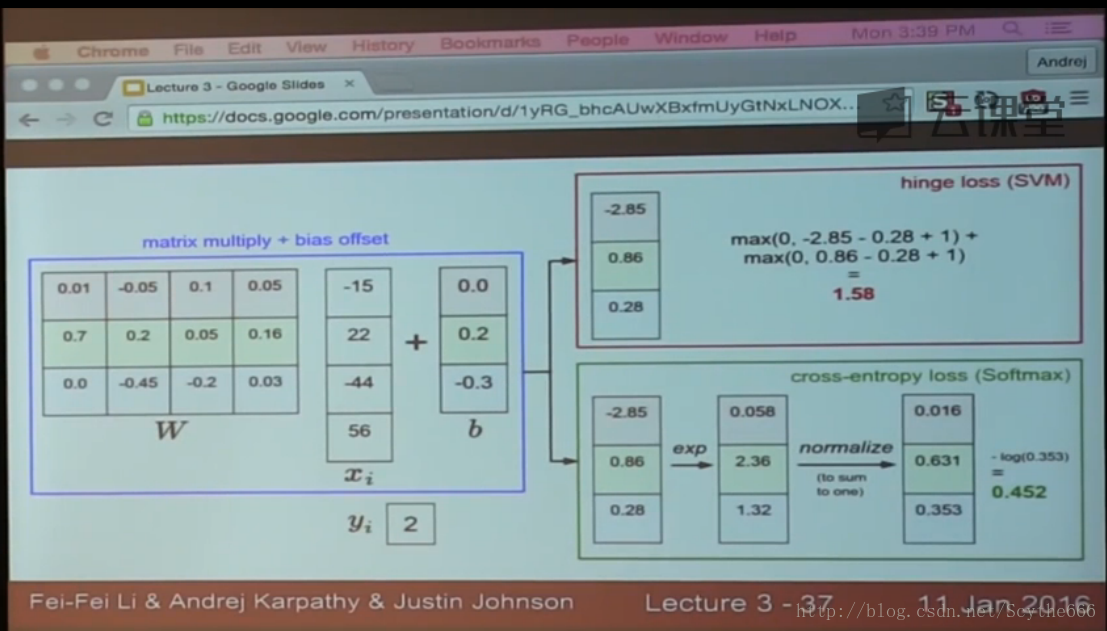
举例:用一个例子演示公式是如何计算的。假设有3个分类,并且得到了分值s=[13,-7,11]。其中第一个类别是正确类别,即y_i=0。同时假设\Delta是10(后面会详细介绍该超参数)。上面的公式是将所有不正确分类(j\not=y_i)加起来,所以我们得到两个部分:
Li=max(0,-7-13+10)+max(0,11-13+10)
可以看到第一个部分结果是0,这是因为[-7-13+10]得到的是负数,经过max(0,-)函数处理后得到0。这一对类别分数和标签的损失值是0,这是因为正确分类的得分13与错误分类的得分-7的差为20,高于边界值10。而SVM只关心差距至少要大于10,更大的差值还是算作损失值为0。第二个部分计算[11-13+10]得到8。虽然正确分类的得分比不正确分类的得分要高(13>11),但是比10的边界值还是小了,分差只有2,这就是为什么损失值等于8。简而言之,SVM的损失函数想要正确分类类别y_i的分数比不正确类别分数高,而且至少要高\Delta。如果不满足这点,就开始计算损失值。
那么在这次的模型中,我们面对的是线性评分函数(f(x_i,W)=Wx_i),所以我们可以将损失函数的公式稍微改写一下:
L_i=\sum_{j\not=y_i}max(0,w^T_jx_i-w^T_{y_i}x_i+\Delta)
其中w_j是权重W的第j行,被变形为列向量。然而,一旦开始考虑更复杂的评分函数f公式,这样做就不是必须的了。
在结束这一小节前,还必须提一下的属于是关于0的阀值:max(0,-)函数,它常被称为折叶损失(hinge loss)。有时候会听到人们使用平方折叶损失SVM(即L2-SVM),它使用的是max(0,-)^2,将更强烈(平方地而不是线性地)地惩罚过界的边界值。不使用平方是更标准的版本,但是在某些数据集中,平方折叶损失会工作得更好。可以通过交叉验证来决定到底使用哪个。
正则化(Regularization):
上面损失函数有一个问题。假设有一个数据集和一个权重集W能够正确地分类每个数据(即所有的边界都满足,对于所有的i都有L_i=0)。问题在于这个W并不唯一:可能有很多相似的W都能正确地分类所有的数据。一个简单的例子:如果W能够正确分类所有数据,即对于每个数据,损失值都是0。那么当\lambda>1时,任何数乘\lambda W都能使得损失值为0,因为这个变化将所有分值的大小都均等地扩大了,所以它们之间的绝对差值也扩大了。举个例子,如果一个正确分类的分值和举例它最近的错误分类的分值的差距是15,对W乘以2将使得差距变成30。
其中最好的性质就是对大数值权重进行惩罚,可以提升其泛化能力,因为这就意味着没有哪个维度能够独自对于整体分值有过大的影响。举个例子,假设输入向量x=[1,1,1,1],两个权重向量w_1=[1,0,0,0],w_2=[0.25,0.25,0.25,0.25]。那么w^T_1x=w^T_2=1,两个权重向量都得到同样的内积,但是w_1的L2惩罚是1.0,而w_2的L2惩罚是0.25。因此,根据L2惩罚来看,w_2更好,因为它的正则化损失更小。从直观上来看,这是因为w_2的权重值更小且更分散。既然L2惩罚倾向于更小更分散的权重向量,这就会鼓励分类器最终将所有维度上的特征都用起来,而不是强烈依赖其中少数几个维度。在后面的课程中可以看到,这一效果将会提升分类器的泛化能力,并避免过拟合。
简而言之,就是有衡量哪一种w更好的方法了
注:和权重不同,偏差没有这样的效果,因为它们并不控制输入维度上的影响强度。因此通常只对权重W正则化,而不正则化偏差b。在实际操作中,可发现这一操作的影响可忽略不计。最后,因为正则化惩罚的存在,不可能在所有的例子中得到0的损失值,这是因为只有当W=0的特殊情况下,才能得到损失值为0。
Softmax分类器
其中函数f_j(z)=\frac{e^{z_j}}{\sum_ke^{z_k}}被称作softmax 函数:其输入值是一个向量,向量中元素为任意实数的评分值(z中的),函数对其进行压缩,输出一个向量,其中每个元素值在0到1之间,且所有元素之和为1。所以,包含softmax函数的完整交叉熵损失看起唬人,实际上还是比较容易理解的。
简而言之,就是将分数进行压缩,输出相对概率 — 即归一化
让人迷惑的命名规则:
精确地说,SVM分类器使用的是折叶损失(hinge loss),有时候又被称为最大边界损失(max-margin loss)。Softmax分类器使用的是交叉熵损失(corss-entropy loss)。Softmax分类器的命名是从softmax函数那里得来的,softmax函数将原始分类评分变成正的归一化数值,所有数值和为1,这样处理后交叉熵损失才能应用。注意从技术上说“softmax损失(softmax loss)”是没有意义的,因为softmax只是一个压缩数值的函数。但是在这个说法常常被用来做简称。
SVM和Softmax的比较
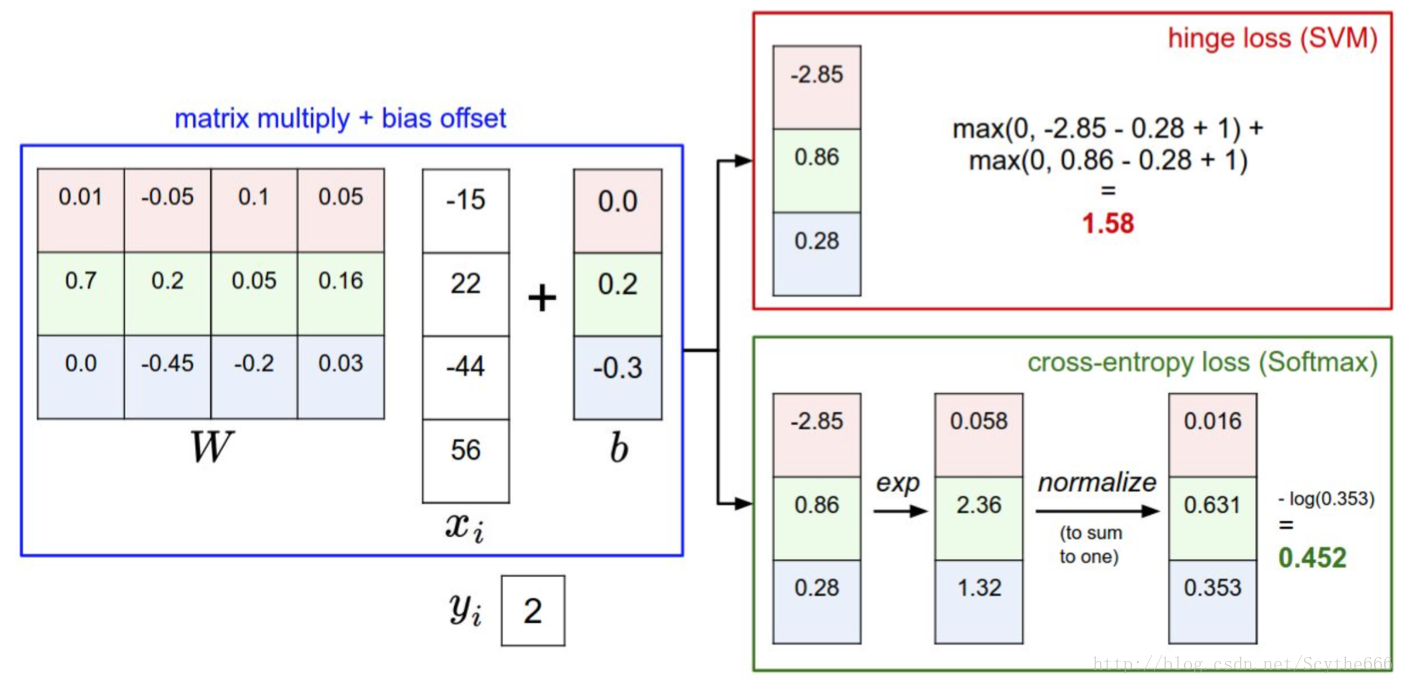
针对一个数据点,SVM和Softmax分类器的不同处理方式的例子。两个分类器都计算了同样的分值向量f(本节中是通过矩阵乘来实现)。不同之处在于对f中分值的解释:SVM分类器将它们看做是分类评分,它的损失函数鼓励正确的分类(本例中是蓝色的类别2)的分值比其他分类的分值高出至少一个边界值。Softmax分类器将这些数值看做是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。SVM的最终的损失值是1.58,Softmax的最终的损失值是0.452,但要注意这两个数值没有可比性。只在给定同样数据,在同样的分类器的损失值计算中,它们才有意义。
在实际使用中,SVM和Softmax经常是相似的:通常说来,两种分类器的表现差别很小,不同的人对于哪个分类器更好有不同的看法。相对于Softmax分类器,SVM更加“局部目标化(local objective)”,这既可以看做是一个特性,也可以看做是一个劣势。考虑一个评分是[10, -2, 3]的数据,其中第一个分类是正确的。那么一个SVM(\Delta =1)会看到正确分类相较于不正确分类,已经得到了比边界值还要高的分数,它就会认为损失值是0。SVM对于数字个体的细节是不关心的:如果分数是[10, -100, -100]或者[10, 9, 9],对于SVM来说没设么不同,只要满足超过边界值等于1,那么损失值就等于0。
对于softmax分类器,情况则不同。对于[10, 9, 9]来说,计算出的损失值就远远高于[10, -100, -100]的。换句话来说,softmax分类器对于分数是永远不会满意的:正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小。但是,SVM只要边界值被满足了就满意了,不会超过限制去细微地操作具体分数。这可以被看做是SVM的一种特性。举例说来,一个汽车的分类器应该把他的大量精力放在如何分辨小轿车和大卡车上,而不应该纠结于如何与青蛙进行区分,因为区分青蛙得到的评分已经足够低了。
策略#1:一个差劲的初始方案:随机搜索
既然确认参数集W的好坏蛮简单的,那第一个想到的(差劲)方法,就是可以随机尝试很多不同的权重,然后看其中哪个最好。
当然也可以迭代取优
策略#2:随机本地搜索
第一个策略可以看做是每走一步都尝试几个随机方向,如果某个方向是向山下的,就向该方向走一步。这次我们从一个随机W开始,然后生成一个随机的扰动\delta W ,只有当W+\delta W的损失值变低,我们才会更新。
策略#3:跟随梯度
前两个策略中,我们是尝试在权重空间中找到一个方向,沿着该方向能降低损失函数的损失值。其实不需要随机寻找方向,因为可以直接计算出最好的方向,这就是从数学上计算出最陡峭的方向。这个方向就是损失函数的梯度(gradient)。在蒙眼徒步者的比喻中,这个方法就好比是感受我们脚下山体的倾斜程度,然后向着最陡峭的下降方向下山。
在一维函数中,斜率是函数在某一点的瞬时变化率。梯度是函数的斜率的一般化表达,它不是一个值,而是一个向量。在输入空间中,梯度是各个维度的斜率组成的向量(或者称为导数derivatives)。对一维函数的求导公式如下:
frac{df(x)}{dx}=\lim_{h\to 0}\frac{f(x+h)-f(x)}{h}
当函数有多个参数的时候,我们称导数为偏导数。而梯度就是在每个维度上偏导数所形成的向量。
步长的影响:
梯度指明了函数在哪个方向是变化率最大的,但是没有指明在这个方向上应该走多远。在后续的课程中可以看到,选择步长(也叫作学习率)将会是神经网络训练中最重要(也是最头痛)的超参数设定之一。还是用蒙眼徒步者下山的比喻,这就好比我们可以感觉到脚朝向的不同方向上,地形的倾斜程度不同。但是该跨出多长的步长呢?不确定。如果谨慎地小步走,情况可能比较稳定但是进展较慢(这就是步长较小的情况)。相反,如果想尽快下山,那就大步走吧,但结果也不一定尽如人意。在上面的代码中就能看见反例,在某些点如果步长过大,反而可能越过最低点导致更高的损失值。
效率问题:你可能已经注意到,计算数值梯度的复杂性和参数的量线性相关。在本例中有30730个参数,所以损失函数每走一步就需要计算30731次损失函数的梯度。现代神经网络很容易就有上千万的参数,因此这个问题只会越发严峻。显然这个策略不适合大规模数据,我们需要更好的策略。
微分分析计算梯度
使用有限差值近似计算梯度比较简单,但缺点在于终究只是近似(因为我们对于h值是选取了一个很小的数值,但真正的梯度定义中h趋向0的极限),且耗费计算资源太多。第二个梯度计算方法是利用微分来分析,能得到计算梯度的公式(不是近似),用公式计算梯度速度很快,唯一不好的就是实现的时候容易出错。为了解决这个问题,在实际操作时常常将分析梯度法的结果和数值梯度法的结果作比较,以此来检查其实现的正确性,这个步骤叫做梯度检查。
梯度下降
现在可以计算损失函数的梯度了,程序重复地计算梯度然后对参数进行更新,这一过程称为梯度下降,他的普通版本是这样的:
普通的梯度下降
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # 进行梯度更新这个简单的循环在所有的神经网络核心库中都有。虽然也有其他实现最优化的方法(比如LBFGS),但是到目前为止,梯度下降是对神经网络的损失函数最优化中最常用的方法。课程中,我们会在它的循环细节增加一些新的东西(比如更新的具体公式),但是核心思想不变,那就是我们一直跟着梯度走,直到结果不再变化。
小批量数据梯度下降(Mini-batch gradient descent):在大规模的应用中(比如ILSVRC挑战赛),训练数据可以达到百万级量级。如果像这样计算整个训练集,来获得仅仅一个参数的更新就太浪费了。一个常用的方法是计算训练集中的小批量(batches)数据。例如,在目前最高水平的卷积神经网络中,一个典型的小批量包含256个例子,而整个训练集是多少呢?一百二十万个。这个小批量数据就用来实现一个参数更新:
# 普通的小批量数据梯度下降
while True:
data_batch = sample_training_data(data, 256) # 256个数据
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad # 参数更新这个方法之所以效果不错,是因为训练集中的数据都是相关的。要理解这一点,可以想象一个极端情况:在ILSVRC中的120万个图像是1000张不同图片的复制(每个类别1张图片,每张图片有1200张复制)。那么显然计算这1200张复制图像的梯度就应该是一样的。对比120万张图片的数据损失的均值与只计算1000张的子集的数据损失均值时,结果应该是一样的。实际情况中,数据集肯定不会包含重复图像,那么小批量数据的梯度就是对整个数据集梯度的一个近似。因此,在实践中通过计算小批量数据的梯度可以实现更快速地收敛,并以此来进行更频繁的参数更新。
小批量数据策略有个极端情况,那就是每个批量中只有1个数据样本,这种策略被称为随机梯度下降(Stochastic Gradient Descent 简称SGD),有时候也被称为在线梯度下降。这种策略在实际情况中相对少见,因为向量化操作的代码一次计算100个数据 比100次计算1个数据要高效很多。即使SGD在技术上是指每次使用1个数据来计算梯度,你还是会听到人们使用SGD来指代小批量数据梯度下降(或者用MGD来指代小批量数据梯度下降,而BGD来指代则相对少见)。小批量数据的大小是一个超参数,但是一般并不需要通过交叉验证来调参。它一般由存储器的限制来决定的,或者干脆设置为同样大小,比如32,64,128等。之所以使用2的指数,是因为在实际中许多向量化操作实现的时候,如果输入数据量是2的倍数,那么运算更快。
卷积神经网络(CNNs / ConvNets)
普通的神经网络,如果用全连接,在CIFAR-10中,图像的尺寸是32x32x3,对应的的常规神经网络的第一个隐层中,每一个单独的全连接神经元就有32x32x3=3072个权重,这太多,而且更大的图像还会更多
而网络中肯定不止一个神经元,那么参数的量就会快速增加!显而易见,这种全连接方式效率低下,大量的参数也很快会导致网络过拟合。
CNN层中的神经元将只与前一层中的一小块区域连接,而不是采取全连接方式。
对于用来分类CIFAR-10中的图像的卷积网络,其最后的输出层的维度是1x1x10,因为在卷积神经网络结构的最后部分将会把全尺寸的图像压缩为包含分类评分的一个向量,向量是在深度方向排列的。下面是例子:
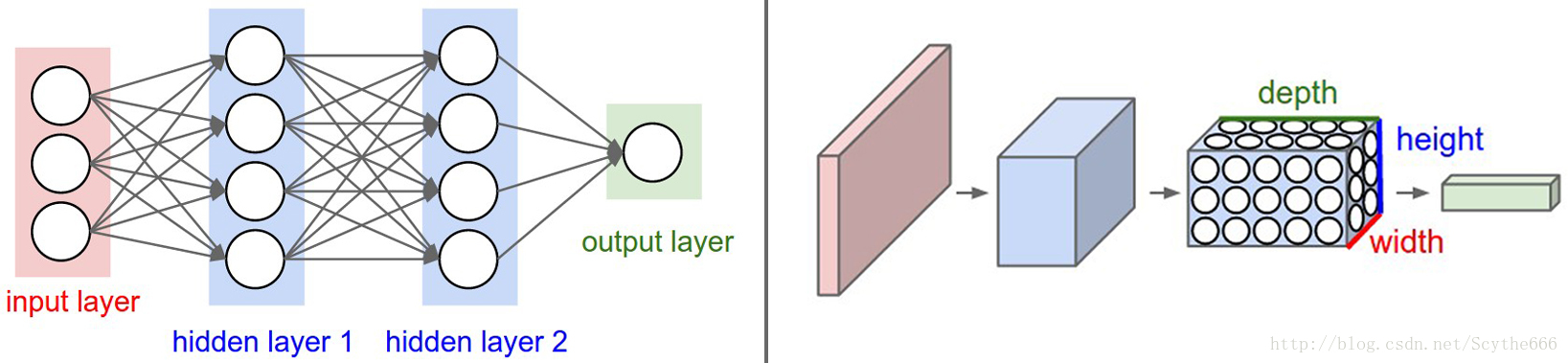
左边是一个3层的神经网络。右边是一个卷积神经网络,图例中网络将它的神经元都排列成3个维度(宽、高和深度)。卷积神经网络的每一层都将3D的输入数据变化为神经元3D的激活数据并输出。在这个例子中,红色的输入层装的是图像,所以它的宽度和高度就是图像的宽度和高度,它的深度是3(代表了红、绿、蓝3种颜色通道)。
用来构建卷积网络的各种层
一个简单的卷积神经网络是由各种层按照顺序排列组成,网络中的每个层使用一个可以微分的函数将激活数据从一个层传递到另一个层。卷积神经网络主要由三种类型的层构成:卷积层,汇聚(Pooling)层和全连接层(全连接层和常规神经网络中的一样)。
网络结构例子:这仅仅是个概述,下面会更详解的介绍细节。一个用于CIFAR-10图像数据分类的卷积神经网络的结构可以是[输入层-卷积层-ReLU层-汇聚层-全连接层]。细节如下:
输入[32x32x3]存有图像的原始像素值,本例中图像宽高均为32,有3个颜色通道。
卷积层中,神经元与输入层中的一个局部区域相连,每个神经元都计算自己与输入层相连的小区域与自己权重的内积。卷积层会计算所有神经元的输出。如果我们使用12个滤波器(也叫作核),得到的输出数据体的维度就是[32x32x12]。
ReLU层将会逐个元素地进行激活函数操作,比如使用以0为阈值的max(0,x)作为激活函数。该层对数据尺寸没有改变,还是[32x32x12]。
汇聚层在在空间维度(宽度和高度)上进行降采样(downsampling)操作,数据尺寸变为[16x16x12]。
全连接层将会计算分类评分,数据尺寸变为[1x1x10],其中10个数字对应的就是CIFAR-10中10个类别的分类评分值。正如其名,全连接层与常规神经网络一样,其中每个神经元都与前一层中所有神经元相连接。
卷积神经网络一层一层地将图像从原始像素值变换成最终的分类评分值。其中有的层含有参数,有的没有。具体说来,卷积层和全连接层(CONV/FC)对输入执行变换操作的时候,不仅会用到激活函数,还会用到很多参数(神经元的突触权值和偏差)。而ReLU层和汇聚层则是进行一个固定不变的函数操作。卷积层和全连接层中的参数会随着梯度下降被训练,这样卷积神经网络计算出的分类评分就能和训练集中的每个图像的标签吻合了。
简单案例中卷积神经网络的结构,就是一系列的层将输入数据变换为输出数据(比如分类评分)。
卷积神经网络结构中有几种不同类型的层(目前最流行的有卷积层、全连接层、ReLU层和汇聚层)。
每个层的输入是3D数据,然后使用一个可导的函数将其变换为3D的输出数据。
有的层有参数,有的没有(卷积层和全连接层有,ReLU层和汇聚层没有)。
有的层有额外的超参数,有的没有(卷积层、全连接层和汇聚层有,ReLU层没有)。
卷积层
卷积层的参数是有一些可学习的滤波器集合构成的。每个滤波器在空间上(宽度和高度)都比较小,但是深度和输入数据一致。举例来说,卷积神经网络第一层的一个典型的滤波器的尺寸可以是5x5x3(宽高都是5像素,深度是3是因为图像应为颜色通道,所以有3的深度)。
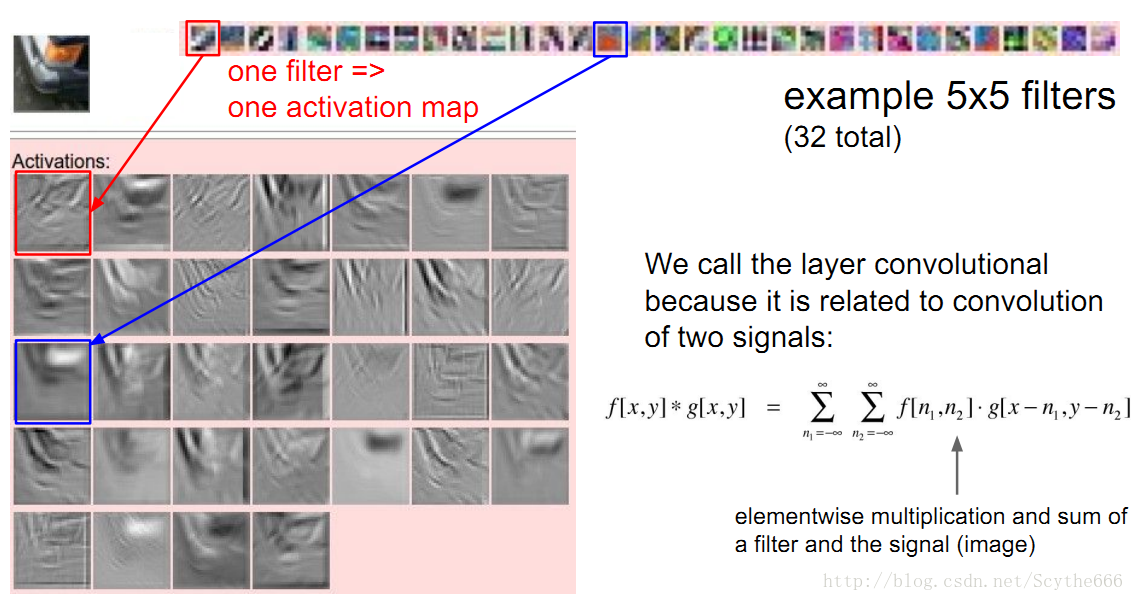
在前向传播的时候,让每个滤波器都在输入数据的宽度和高度上滑动(更精确地说是卷积),然后计算整个滤波器和输入数据任一处的内积。
当滤波器沿着输入数据的宽度和高度滑过后,会生成一个2维的激活图(activation map),激活图给出了在每个空间位置处滤波器的反应。
直观地来说,网络会让滤波器学习到当它看到某些类型的视觉特征时就激活,具体的视觉特征可能是某些方位上的边界,或者在第一层上某些颜色的斑点,甚至可以是网络更高层上的蜂巢状或者车轮状图案。
在每个卷积层上,我们会有一整个集合的滤波器(比如12个),每个都会生成一个不同的二维激活图。将这些激活映射在深度方向上层叠起来就生成了输出数据。
共享参数(以大脑做比喻):如果你喜欢用大脑和生物神经元来做比喻,那么输出的3D数据中的每个数据项可以被看做是神经元的一个输出,而该神经元只观察输入数据中的一小部分,并且和空间上左右两边的所有神经元共享参数(因为这些数字都是使用同一个滤波器得到的结果)。现在开始讨论神经元的连接,它们在空间中的排列,以及它们参数共享的模式。
局部连接:在处理图像这样的高维度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的。相反,我们让每个神经元只与输入数据的一个局部区域连接。该连接的空间大小叫做神经元的感受野(receptive field),它的尺寸是一个超参数(其实就是滤波器的空间尺寸)。在深度方向上,这个连接的大小总是和输入量的深度相等。需要再次强调的是,我们对待空间维度(宽和高)与深度维度是不同的:连接在空间(宽高)上是局部的,但是在深度上总是和输入数据的深度一致。

左边:红色的是输入数据体(比如CIFAR-10中的图像),蓝色的部分是第一个卷积层中的神经元。卷积层中的每个神经元都只是与输入数据体的一个局部在空间上相连,但是与输入数据体的所有深度维度全部相连(所有颜色通道)。在深度方向上有多个神经元(本例中5个),它们都接受输入数据的同一块区域(感受野相同)。至于深度列的讨论在下文中有。
右边:神经网络章节中介绍的神经元保持不变,它们还是计算权重和输入的内积,然后进行激活函数运算,只是它们的连接被限制在一个局部空间。
空间排列:
上文讲解了卷积层中每个神经元与输入数据体之间的连接方式,但是尚未讨论输出数据体中神经元的数量,以及它们的排列方式。3个超参数控制着输出数据体的尺寸:深度(depth),步长(stride)和零填充(zero-padding)。下面是对它们的讨论:
首先,输出数据体的深度是一个超参数:它和使用的滤波器的数量一致,而每个滤波器在输入数据中寻找一些不同的东西。举例来说,如果第一个卷积层的输入是原始图像,那么在深度维度上的不同神经元将可能被不同方向的边界,或者是颜色斑点激活。我们将这些沿着深度方向排列、感受野相同的神经元集合称为深度列(depth column),也有人使用纤维(fibre)来称呼它们。
其次,在滑动滤波器的时候,必须指定步长。当步长为1,滤波器每次移动1个像素。当步长为2(或者不常用的3,或者更多,这些在实际中很少使用),滤波器滑动时每次移动2个像素。这个操作会让输出数据体在空间上变小。
在下文可以看到,有时候将输入数据体用0在边缘处进行填充是很方便的。这个零填充(zero-padding)的尺寸是一个超参数。零填充有一个良好性质,即可以控制输出数据体的空间尺寸(最常用的是用来保持输入数据体在空间上的尺寸,这样输入和输出的宽高都相等)。
为什么要用参数共享
注意参数共享的假设是有道理的:如果在图像某些地方探测到一个水平的边界是很重要的,那么在其他一些地方也会同样是有用的,这是因为图像结构具有平移不变性。所以在卷积层的输出数据体的55x55个不同位置中,就没有必要重新学习去探测一个水平边界了。
注意有时候参数共享假设可能没有意义,特别是当卷积神经网络的输入图像是一些明确的中心结构时候。这时候我们就应该期望在图片的不同位置学习到完全不同的特征。一个具体的例子就是输入图像是人脸,人脸一般都处于图片中心。你可能期望不同的特征,比如眼睛特征或者头发特征可能(也应该)会在图片的不同位置被学习。在这个例子中,通常就放松参数共享的限制,将层称为局部连接层(Locally-Connected Layer)。
把全连接层转化成卷积层
全连接层和卷积层之间唯一的不同就是卷积层中的神经元只与输入数据中的一个局部区域连接,并且在卷积列中的神经元共享参数。然而在两类层中,神经元都是计算点积,所以它们的函数形式是一样的。因此,将此两者相互转化是可能的:
对于任一个卷积层,都存在一个能实现和它一样的前向传播函数的全连接层。权重矩阵是一个巨大的矩阵,除了某些特定块(这是因为有局部连接),其余部分都是零。而在其中大部分块中,元素都是相等的(因为参数共享)。
相反,任何全连接层都可以被转化为卷积层。比如,一个K=4096的全连接层,输入数据体的尺寸是7\times 7\times 512,这个全连接层可以被等效地看做一个F=7,P=0,S=1,K=4096的卷积层。换句话说,就是将滤波器的尺寸设置为和输入数据体的尺寸一致了。因为只有一个单独的深度列覆盖并滑过输入数据体,所以输出将变成1\times 1\times 4096,这个结果就和使用初始的那个全连接层一样了。
卷积神经网络的结构
卷积神经网络通常是由三种层构成:卷积层,汇聚层(除非特别说明,一般就是最大值汇聚)和全连接层(简称FC)。ReLU激活函数也应该算是是一层,它逐元素地进行激活函数操作。在本节中将讨论在卷积神经网络中这些层通常是如何组合在一起的。
层的排列规律
卷积神经网络最常见的形式就是将一些卷积层和ReLU层放在一起,其后紧跟汇聚层,然后重复如此直到图像在空间上被缩小到一个足够小的尺寸,在某个地方过渡成成全连接层也较为常见。最后的全连接层得到输出,比如分类评分等。换句话说,最常见的卷积神经网络结构如下:
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
其中*指的是重复次数,POOL?指的是一个可选的汇聚层。其中N >=0,通常N<=3,M>=0,K>=0,通常K<3。例如,下面是一些常见的网络结构规律:
INPUT -> FC,实现一个线性分类器,此处N = M = K = 0。
INPUT -> CONV -> RELU -> FC
INPUT -> [CONV -> RELU -> POOL]*2 -> FC -> RELU -> FC。此处在每个汇聚层之间有一个卷积层。
INPUT -> [CONV -> RELU -> CONV -> RELU -> POOL]*3 -> [FC -> RELU]*2 -> FC。此处每个汇聚层前有两个卷积层,这个思路适用于更大更深的网络,因为在执行具有破坏性的汇聚操作前,多重的卷积层可以从输入数据中学习到更多的复杂特征。
几个小滤波器卷积层的组合比一个大滤波器卷积层好:假设你一层一层地重叠了3个3x3的卷积层(层与层之间有非线性激活函数)。在这个排列下,第一个卷积层中的每个神经元都对输入数据体有一个3x3的视野。第二个卷积层上的神经元对第一个卷积层有一个3x3的视野,也就是对输入数据体有5x5的视野。同样,在第三个卷积层上的神经元对第二个卷积层有3x3的视野,也就是对输入数据体有7x7的视野。假设不采用这3个3x3的卷积层,二是使用一个单独的有7x7的感受野的卷积层,那么所有神经元的感受野也是7x7,但是就有一些缺点。首先,多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好的特征。其次,假设所有的数据有C个通道,那么单独的7x7卷积层将会包含C\times (7\times 7\times C)=49C^2个参数,而3个3x3的卷积层的组合仅有3\times (C\times (3\times 3\times C))=27C^2个参数。直观说来,最好选择带有小滤波器的卷积层组合,而不是用一个带有大的滤波器的卷积层。前者可以表达出输入数据中更多个强力特征,使用的参数也更少。唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
层的尺寸设置规律
到现在为止,我们都没有提及卷积神经网络中每层的超参数的使用。现在先介绍设置结构尺寸的一般性规则,然后根据这些规则进行讨论:
输入层(包含图像的)应该能被2整除很多次。常用数字包括32(比如CIFAR-10),64,96(比如STL-10)或224(比如ImageNet卷积神经网络),384和512。
卷积层应该使用小尺寸滤波器(比如3x3或最多5x5),使用步长S=1。还有一点非常重要,就是对输入数据进行零填充,这样卷积层就不会改变输入数据在空间维度上的尺寸。比如,当F=3,那就使用P=1来保持输入尺寸。当F=5,P=2,一般对于任意F,当P=(F-1)/2的时候能保持输入尺寸。如果必须使用更大的滤波器尺寸(比如7x7之类),通常只用在第一个面对原始图像的卷积层上。
汇聚层负责对输入数据的空间维度进行降采样。最常用的设置是用用2x2感受野(即F=2)的最大值汇聚,步长为2(S=2)。注意这一操作将会把输入数据中75%的激活数据丢弃(因为对宽度和高度都进行了2的降采样)。另一个不那么常用的设置是使用3x3的感受野,步长为2。最大值汇聚的感受野尺寸很少有超过3的,因为汇聚操作过于激烈,易造成数据信息丢失,这通常会导致算法性能变差。
减少尺寸设置的问题:上文中展示的两种设置是很好的,因为所有的卷积层都能保持其输入数据的空间尺寸,汇聚层只负责对数据体从空间维度进行降采样。如果使用的步长大于1并且不对卷积层的输入数据使用零填充,那么就必须非常仔细地监督输入数据体通过整个卷积神经网络结构的过程,确认所有的步长和滤波器都尺寸互相吻合,卷积神经网络的结构美妙对称地联系在一起。
为什么在卷积层使用1的步长?在实际应用中,更小的步长效果更好。上文也已经提过,步长为1可以让空间维度的降采样全部由汇聚层负责,卷积层只负责对输入数据体的深度进行变换。
为何使用零填充?使用零填充除了前面提到的可以让卷积层的输出数据保持和输入数据在空间维度的不变,还可以提高算法性能。如果卷积层值进行卷积而不进行零填充,那么数据体的尺寸就会略微减小,那么图像边缘的信息就会过快地损失掉。
因为内存限制所做的妥协:在某些案例(尤其是早期的卷积神经网络结构)中,基于前面的各种规则,内存的使用量迅速飙升。例如,使用64个尺寸为3x3的滤波器对224x224x3的图像进行卷积,零填充为1,得到的激活数据体尺寸是[224x224x64]。这个数量就是一千万的激活数据,或者就是72MB的内存(每张图就是这么多,激活函数和梯度都是)。因为GPU通常因为内存导致性能瓶颈,所以做出一些妥协是必须的。在实践中,人们倾向于在网络的第一个卷积层做出妥协。例如,可以妥协可能是在第一个卷积层使用步长为2,尺寸为7x7的滤波器(比如在ZFnet中)。在AlexNet中,滤波器的尺寸的11x11,步长为4。
计算上的考量
在构建卷积神经网络结构时,最大的瓶颈是内存瓶颈。大部分现代GPU的内存是3/4/6GB,最好的GPU大约有12GB的内存。要注意三种内存占用来源:
来自中间数据体尺寸:卷积神经网络中的每一层中都有激活数据体的原始数值,以及损失函数对它们的梯度(和激活数据体尺寸一致)。通常,大部分激活数据都是在网络中靠前的层中(比如第一个卷积层)。在训练时,这些数据需要放在内存中,因为反向传播的时候还会用到。但是在测试时可以聪明点:让网络在测试运行时候每层都只存储当前的激活数据,然后丢弃前面层的激活数据,这样就能减少巨大的激活数据量。
来自参数尺寸:即整个网络的参数的数量,在反向传播时它们的梯度值,以及使用momentum、Adagrad或RMSProp等方法进行最优化时的每一步计算缓存。因此,存储参数向量的内存通常需要在参数向量的容量基础上乘以3或者更多。
卷积神经网络实现还有各种零散的内存占用,比如成批的训练数据,扩充的数据等等。一旦对于所有这些数值的数量有了一个大略估计(包含激活数据,梯度和各种杂项),数量应该转化为以GB为计量单位。把这个值乘以4,得到原始的字节数(因为每个浮点数占用4个字节,如果是双精度浮点数那就是占用8个字节),然后多次除以1024分别得到占用内存的KB,MB,最后是GB计量。如果你的网络工作得不好,一个常用的方法是降低批尺寸(batch size),因为绝大多数的内存都是被激活数据消耗掉了。