运用bs4来爬取聚合数据api的所有信息https://www.juhe.cn/docs
import urllib import urllib.request import urllib.parse from bs4 import BeautifulSoup
一开始导入所需库包
定义类
class juheApi(object):
在类里面书写方法
第一个方法:获取对应url的html代码
# 简单的爬取整个网页 def getHtml(self, url): # 请求 request = urllib.request.Request(url) # 爬取结果 response = urllib.request.urlopen(request) data = response.read() # 设置解码方式 data = data.decode('utf-8') # print(type(response)) # print(response.geturl()) # print(response.info()) # print(response.getcode()) return data
第二个方法:解析获取到的html,拿到自己所需的数据
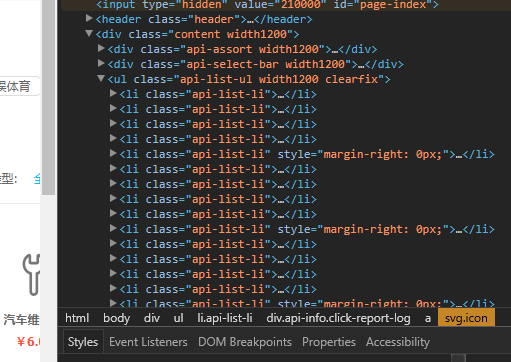
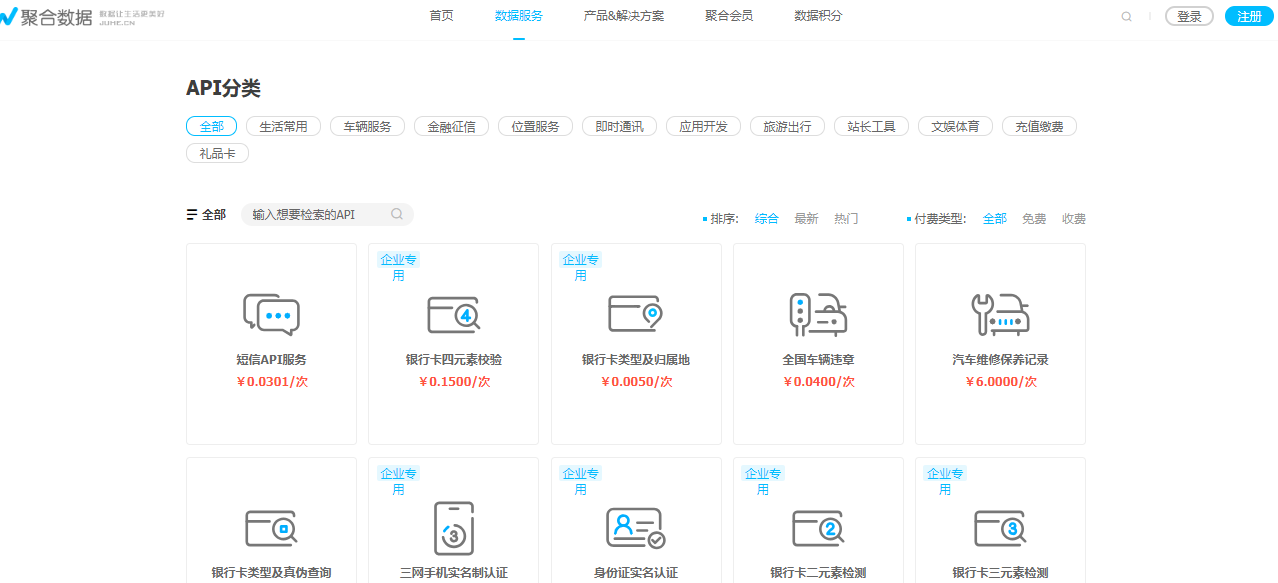
审查元素之后发现所需的数据都在标签为ul,class为api-list-li里面,所以先找到这个对象
TAB = soup.find_all("ul", attrs={"class": "api-list-ul"})
再接下去看,元素块状化,li是遍历循环出来的,所以每一个li里面包含了对应个api的信息
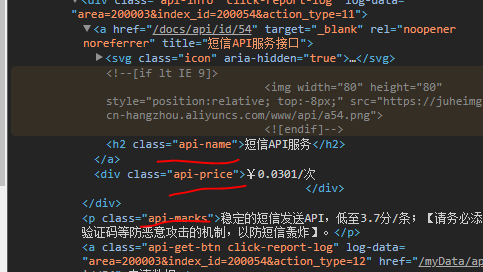
分别包含在三个标签里面,所以拿出来做处理
name = x.find_all('h2', class_="api-name") price = x.find_all('div', class_="api-price") marks = x.find_all('p', class_="api-marks")分别拿到标签里面的content,添加到一个data列表里面,循环借宿
# 根据url获取数值 def getValue(self, url): soup = BeautifulSoup(self.getHtml(url), 'html.parser') TAB = soup.find_all("ul", attrs={"class": "api-list-ul"}) data = [] for t in TAB: li_list = t.find_all("li", attrs={"class": "api-list-li"}) for x in li_list: self.num += 1 data.append("序号:" + str(self.num)) print("正在爬取第" + str(self.num) + "条数据...") name = x.find_all('h2', class_="api-name") price = x.find_all('div', class_="api-price") marks = x.find_all('p', class_="api-marks") for a in name: api_name = a.get_text(strip=True) data.append("名字:" + api_name) for b in price: api_price = b.get_text(strip=True) data.append("价钱:" + api_price) for c in marks: api_marks = c.get_text(strip=True) data.append("说明:" + api_marks) # print(api_marks) # print(data) self.toSave(data)
保存的数据格式是列表,正常write是不可行的,可以转换为字符串(str)或者循环列表一个一个写入
# 保存list格式 def toSave(self, data): save_path = 'E:\\桌面\\test.txt' f_obj = open(save_path, 'a+') for i in data: f_obj.write(i + "\n") f_obj.close()
三个函数已经可以解决爬取的问题的,但是页面还有一个分页数据的问题,分页的话我有两种思路,一个判断有无下一页的标签来进行url查询,二是获取当前页面页码的总数,根据url规律做成list循环输出获取页面数据,我选了第二种方法
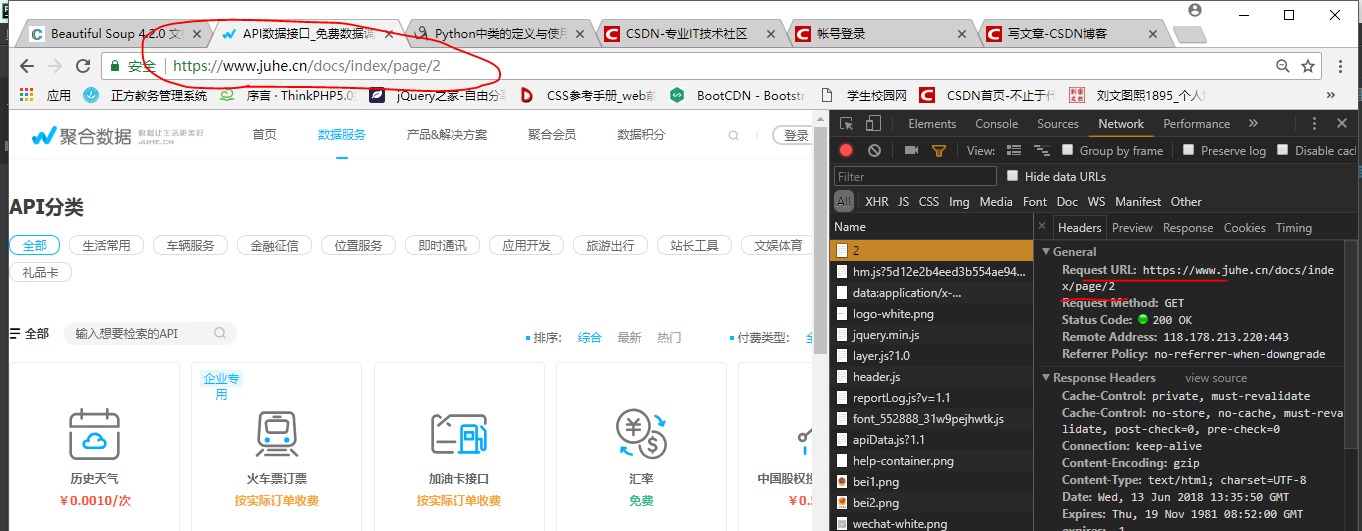
查看请求和地址栏之后,做成list
urls = ['https://www.juhe.cn/docs/index/page/{}.html'.format(str(i)) for i in range(1, 6)]
遍历urls获取数据,这种方法是简单实现了分页数据的获取
number = 0 t = juheApi() for url in urls: number += 1 print("<--------正在爬取第" + str(number) + "个页面------->") t.getValue(url) print("全部爬取完成,一共"+str(t.num)+"条数据")
爬取成功后,数据保存到了我的桌面的test.txt里面
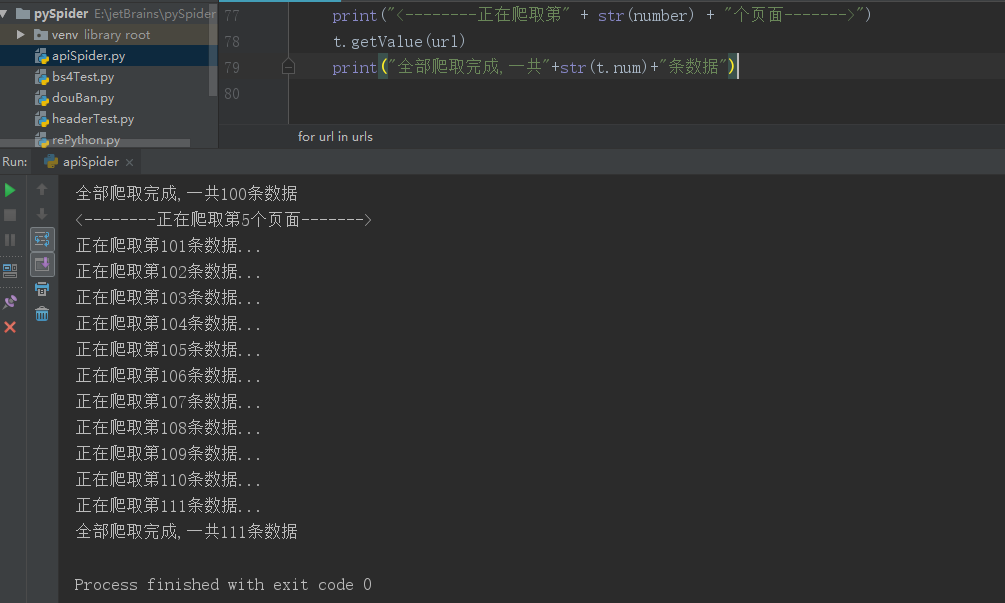

这是初次尝试使用bs4来简单爬取了网页数据啊,下次准备模拟登陆
下面完整代码贴出:
import urllib import urllib.request import urllib.parse from bs4 import BeautifulSoup class juheApi(object): def __init__(self): self.num = 0 # start_url = "https://www.juhe.cn/docs" # 简单的爬取整个网页 def getHtml(self, url): # 请求 request = urllib.request.Request(url) # 爬取结果 response = urllib.request.urlopen(request) data = response.read() # 设置解码方式 data = data.decode('utf-8') # print(type(response)) # print(response.geturl()) # print(response.info()) # print(response.getcode()) return data # 保存list格式 def toSave(self, data): save_path = 'E:\\桌面\\test.txt' f_obj = open(save_path, 'a+') for i in data: f_obj.write(i + "\n") f_obj.close() # 根据url获取数值 def getValue(self, url): soup = BeautifulSoup(self.getHtml(url), 'html.parser') TAB = soup.find_all("ul", attrs={"class": "api-list-ul"}) data = [] for t in TAB: li_list = t.find_all("li", attrs={"class": "api-list-li"}) for x in li_list: self.num += 1 data.append("序号:" + str(self.num)) print("正在爬取第" + str(self.num) + "条数据...") name = x.find_all('h2', class_="api-name") price = x.find_all('div', class_="api-price") marks = x.find_all('p', class_="api-marks") for a in name: api_name = a.get_text(strip=True) data.append("名字:" + api_name) for b in price: api_price = b.get_text(strip=True) data.append("价钱:" + api_price) for c in marks: api_marks = c.get_text(strip=True) data.append("说明:" + api_marks) # print(api_marks) # print(data) self.toSave(data) # # 检查是否有next # def checkNext(self, url): # soup = BeautifulSoup(self.getHtml(url), 'html.parser') # next = soup.find("span", attrs={"class": "nextPage"}) # if next is None: # return False # else: # return True urls = ['https://www.juhe.cn/docs/index/page/{}.html'.format(str(i)) for i in range(1, 6)] number = 0 t = juheApi() for url in urls: number += 1 print("<--------正在爬取第" + str(number) + "个页面------->") t.getValue(url) print("全部爬取完成,一共"+str(t.num)+"条数据")