今天,我们将用Python的pip,安装下载一个第三方库BeautifulSoup4,它可以帮助我们分析HTML网页的内容。
1.安装BeautifulSoup4模块
在Windows系统下,打开一个cmd命令提示符,输入:
pip install BeautifulSoup4
如果没有出现错误信息,则打开一个Python文件,输入:
import bs4
运行代码,没有报错就说明成功安装。
2.使用BeautifulSoup4模块
from bs4 import BeautifulSoup
以上代码导入了bs4(BeautifulSoup4以下用简写)模块的解析对象类,然后,我们请求得到一个网页源代码,这里请求的网页是笔者的博客主页:
from bs4 import BeautifulSoup as bs
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36",
"Host": "blog.csdn.net"
}
url = "https://blog.csdn.net/wangzirui32/"
r = requests.get(url, headers=headers)
# 创建解析对象
soup = bs(r.text, "html.parser")
我们为BeautifulSoup指定了别名bs,这是为了简便。它有两个参数,第一个是我们要分析的源码,第二个是我们解析的方式。
3.获取总赞数
先来到笔者的主页,打开检查功能,点击箭头,再移动鼠标到“获赞”上面的数字,如图:
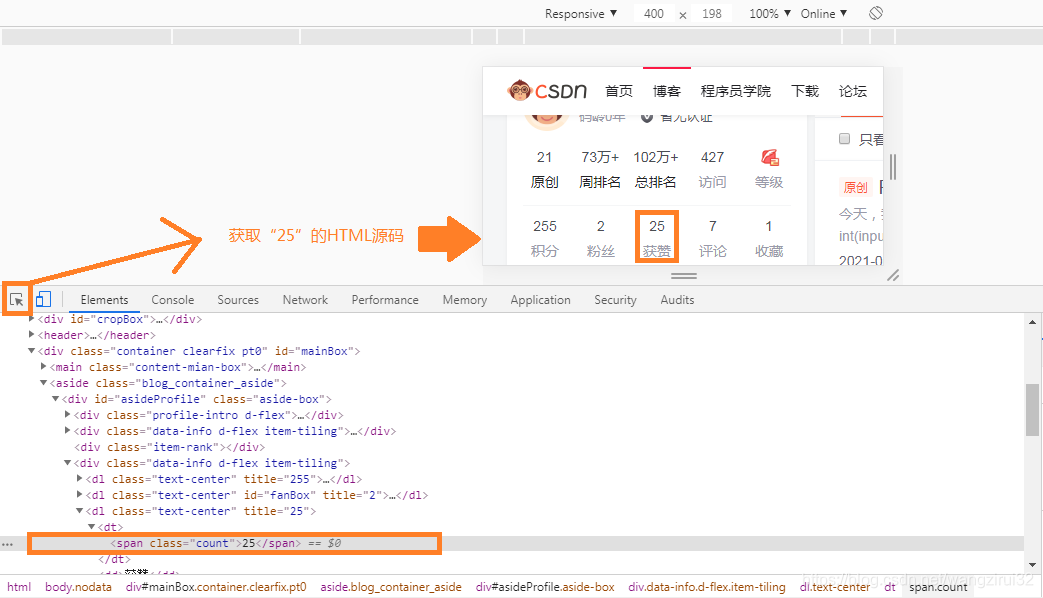
获赞的数字在一个span标签中,它有一个属性:class,class的内容为count。
根据这些信息,我们继续编写代码:
span = soup.find("span", {
"class":"count"})
like = int(span.string)
print("获赞:", like)
这里使用了find函数,第一个参数是标签名称(必选);第二个参数(可选)是它的属性内容,用字典来书写,键为属性名,值为属性内容。
string用来获取标签的内容。
输出:
21
为什么是原创文章数量呢?经过查找,发现存储原创文章数量的标签也是span,且属性相同,而find函数只返回第一个查找到的标签,怎么办呢?
这时,我们可以使用find_all函数,它的参数和find函数一样,只不过它会返回所以符合条件的标签,以列表的形式输出:
# 重新写亿下
span_list = soup.find_all("span", {
"class":"count"})
for s in span_list:
print(s)
输出:
<span class="count">21</span>
<span class="count" id="fan">2</span>
<span class="count">25</span>
<span class="count">7</span>
可以看出,赞数就在第3个列表项中,在索引2的位置,再来写亿遍:
span_list = soup.find_all("span", {
"class":"count"})
like = int(span_list[2].string)
print("获赞:", like)
输出:
获赞: 25
怎么样?学会了吗?
当然,主页还有其它公开数据可以爬取,感兴趣的读者可以自己试亿下,我就不演示了。