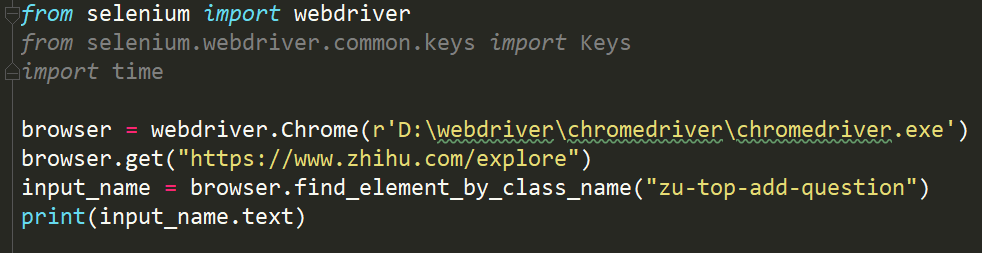
一. 介绍
Selenium是一个Web自动化测试工具,支持多种编程语言,支持跨浏览器的自动化测试工具。
Selenium在爬虫中一般应用在动态网页的内容经过加密后,并且JavaScript代码混淆,肉眼很难读取完成。这种情况下使用selenium来模拟浏览器解析Javascript, 再爬取被解析以后的内容。python版的selenium官方文档。
二 使用
1. demo演示
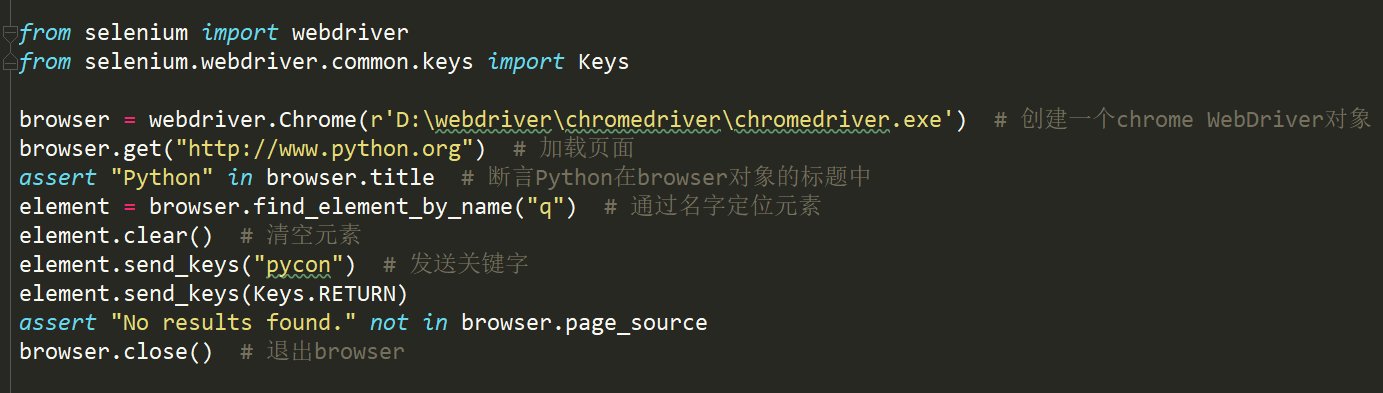
2. 访问页面

3. 查找单个元素
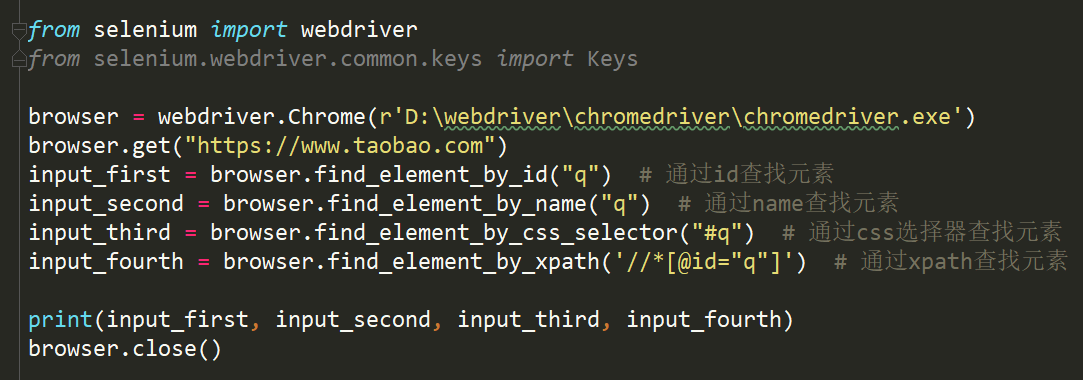
4. 查找多个元素 只需把find_element --> find_elements(多个元素会用列表呈现)
5. 元素交互操作
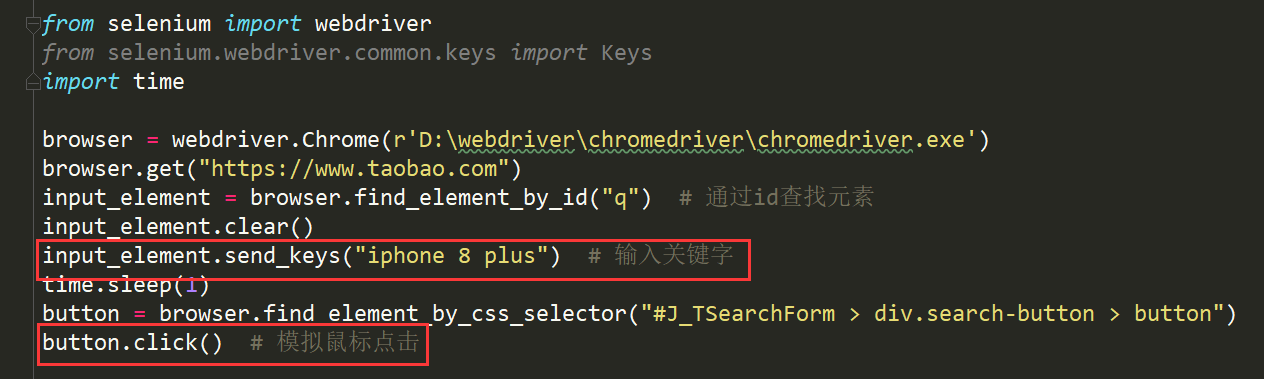
【Tips】更多的元素交互参考。
6. 获取元素信息
selenium中可以通过page_source属性可以获取网页的源代码, 通过获取的源代码,可以使用正则,BeautifulSoup、Pyquery、Xpath来提取信息。Selenium提供了选择元素的方法,返回的是WebElement类型,也有相关的方法和属性来直接提取元素信息,如属性、文本等。
获取属性: 使用get_attribute()
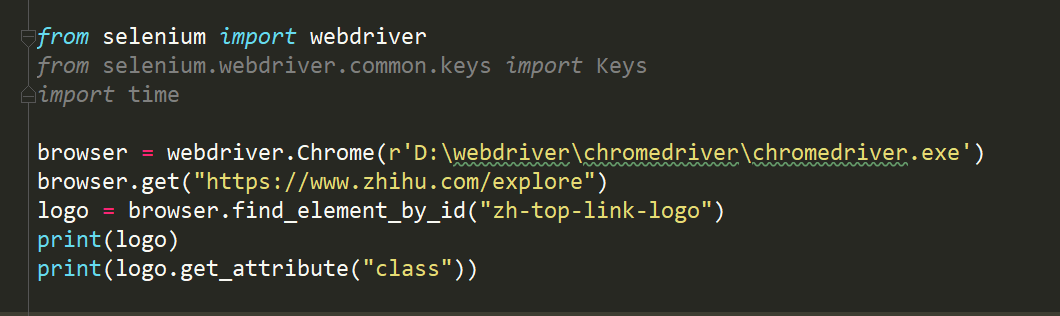
获取文本:
每个WebElement元素都有text属性,可以直接调用这个属性就可以得到元素内部的文本信息,像BeautifulSoup的get_text()方法, PyQuery的text()方法。