一.前言
之前有学习过Selenium,撰写本篇用以回忆Selenium的一些用法以及实现几个日常需求。
二.引入
1.什么是Selenium?
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。——摘自百度

Selenium是一种便携的Web应用程序的软件测试框架。
2.相关网站
-
官网
-
Python文档
-
文档:
三.环境安装
1.Python
本篇使用Python作为开发语言,开发环境为Python 3.x
Python的安装以及环境变量的配置可以参考:
Python安装好后,使用
pip install selenium
安装selenium第三方库
2.Chrome
本次拿谷歌Chrome浏览器用作演示,也可以选用其它浏览器,比如:Firefox、Opera、Microsoft Edge。
谷歌浏览器的安装可以参考:
3.Selenium WebDriver
什么是Selenium WebDriver?
Selenium WebDriver是①一种用于web应用程序的自动化测试工具,②它提供了一套友好的API。(API:应用编程接口说明;webDriver类库内封装了非常多的方法。)③webDriver完全就是一套类库,不依赖于任何测试框架,除了必要的浏览器驱动。
Selenium Webdriver是通过各种浏览器的驱动(web driver)来驱动操作浏览器,成功后会返回一个WebDriver实例对象,通过它的方法,可以控制浏览器,通过元素定位,driver找到该元素的话,就会返回一个该元素的WebElement对象,然后再调用它的方法,就可以对其进行操作了,比如输入内容,点击按钮等。
安装WebDriver:
- 查看浏览器版本
本次以谷歌浏览器为例演示Chrome的WebDriver安装
点击自定义及控制-设置-关于Chrome
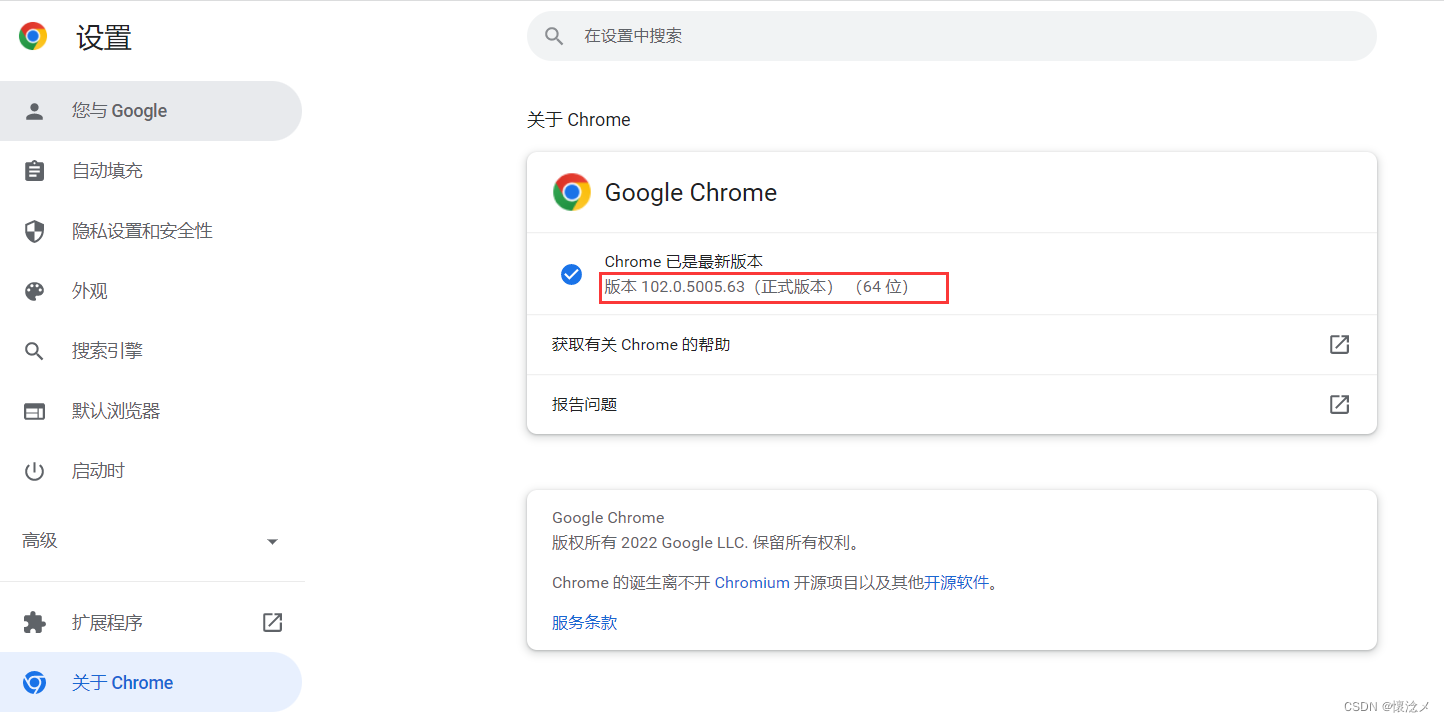
可以看到我的谷歌浏览器版本是102.0.5005.63 - 下载WebDriver
打开网站
https://registry.npmmirror.com/binary.html?path=chromedriver/
选择与自己浏览器匹配的WebDriver版本

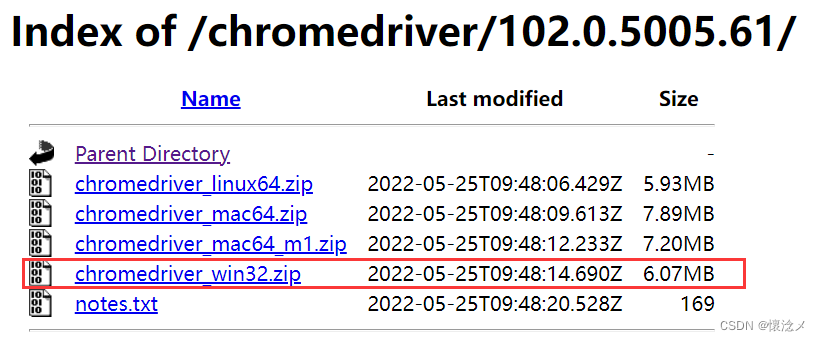
我下载的是102.0.5005.61版本的chromedriver_win32,大家根据自己的情况选择下载。
3.配置webdriver
将下载好的chromedriver.exe,放入Python安装目录下的Scripts目录即可
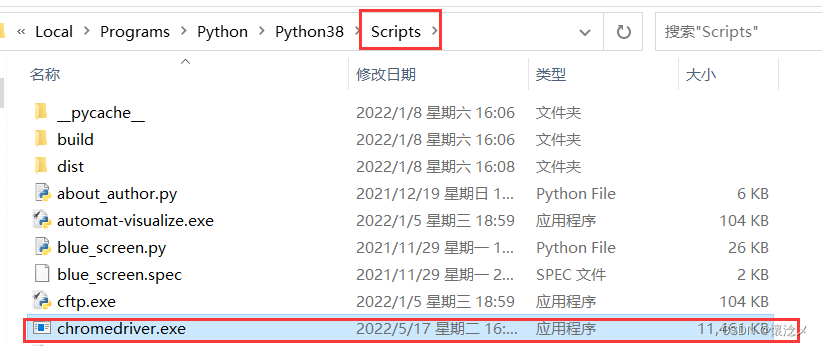
4.Python开发环境
首选PyCharm,也可以选用eclipse、VSCode、或者用Python自带的IDLE也行…
本次选用PyCharm,PyCharm的安装可以参考:
四.元素定位
1.打开浏览器
使用Selenium打开百度测试一下
from selenium import webdriver # 导入webdriver
driver = webdriver.Chrome() # 启动浏览器
driver.get("https://www.baidu.com") # 打开某个网址
能够发现,代码运行后自动打开了浏览器
2.元素定位-ID定位
元素定位主要是通过webdriver的find_element函数,定位规则是selenium.webdriver.common.by 里 By的规则
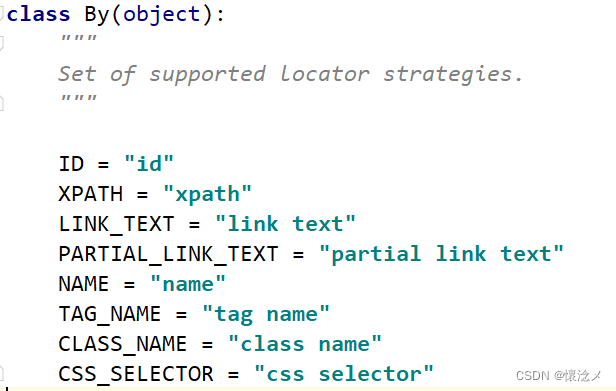
可以看到By将所有定位方法整合了起来
查找定位百度搜索框
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://www.baidu.com") # 打开百度
inputElement = driver.find_element(By.ID, "kw") # 查找输入框元素
if inputElement.is_displayed(): # 判断页面上是否展示了此元素
print("success")
else:
print("fail")
driver.quit() # 关闭浏览器
ID定位可以准确定位到元素。通过调用webdriver的find_element函数,再通过ID定位到搜索框,使用is_displayed方法判断页面上是否展示了这个元素,最后关闭浏览器实现ID定位。
2.元素定位-NAME定位
通过元素的name标签进行元素定位
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://www.baidu.com") # 打开百度
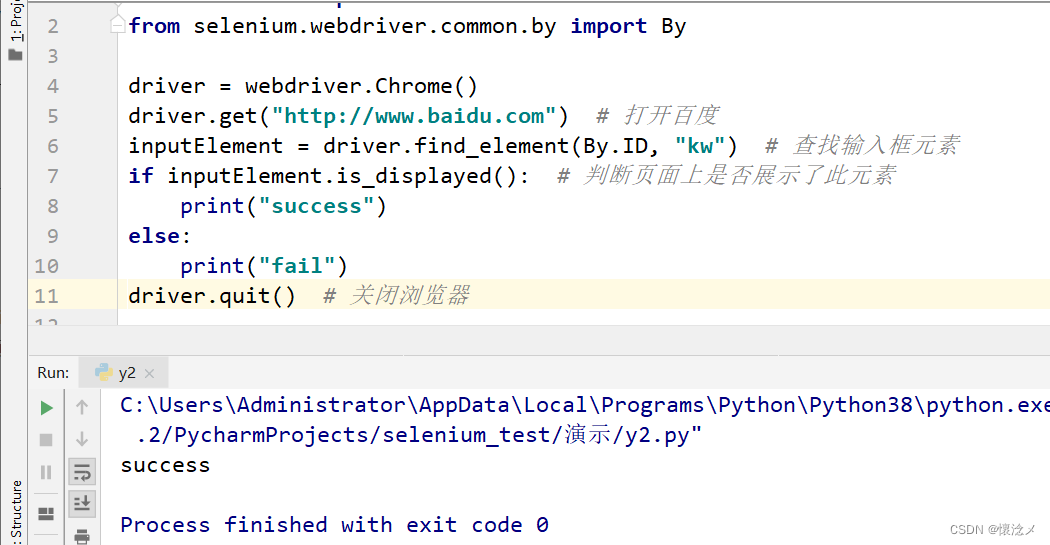
inputElement = driver.find_element(By.NAME, "wd") # 查找输入框元素
idName=inputElement.get_attribute("class")
print(idName)
driver.quit() # 关闭浏览器
运行结果
通过定位元素的name属性,再获取元素的class属性,确定了定位元素正确。
3.元素定位-CLASS_NAME定位
顾名思义,根据类名定位元素
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://www.baidu.com") # 打开百度
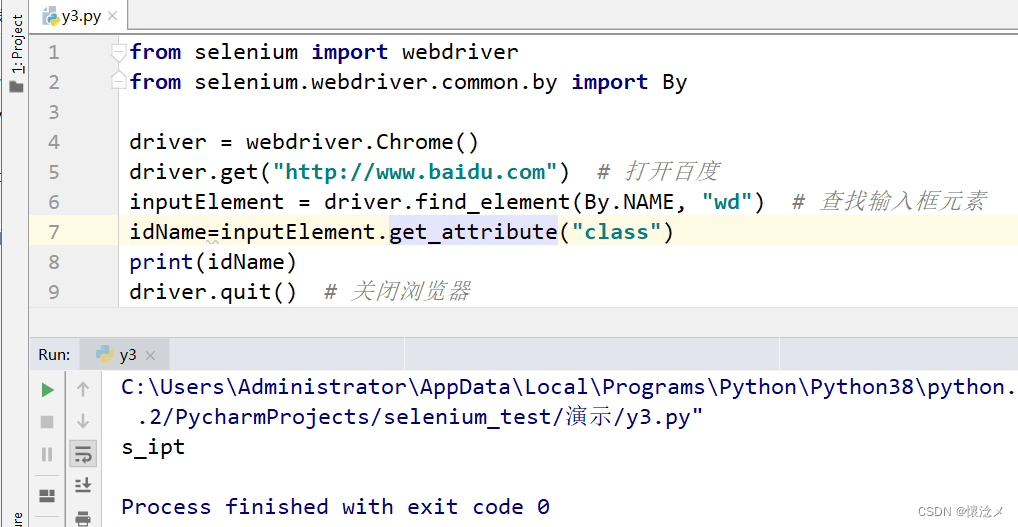
inputElement = driver.find_element(By.CLASS_NAME, "s_ipt") # 查找输入框元素
idName=inputElement.get_attribute("id")#获取元素的id值
print(idName)
driver.quit() # 关闭浏览器
由于可能有多个元素使用了相同的类名,所以使用get_attribute获取元素的id值,进行判断。
可以看到,我们查找的元素确实是输入框且id为”kw“
4.元素定位-TAG_NAME定位
根据标签名称定位到元素。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://www.baidu.com") # 打开百度
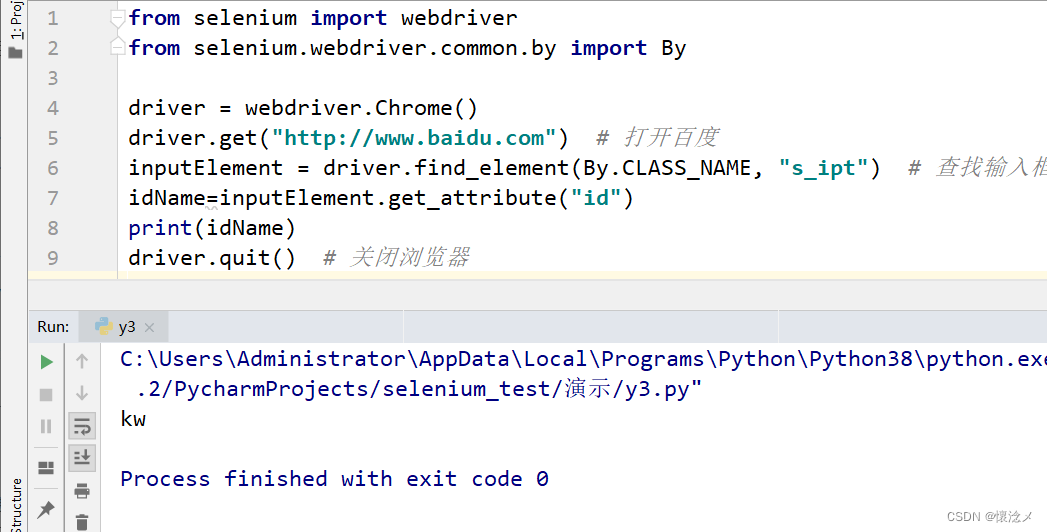
inputElement = driver.find_element(By.TAG_NAME, "span") # 根据标签名称定位元素
className = inputElement.get_attribute("class") # 获取元素所属类名
print(className)
driver.quit() # 关闭浏览器
运行结果
成功定位到了span标签,并且获取到了它的类名
5.元素定位-LINK_TEXT定位
LINK_TEXT定位,为文本定位,当目标文本和元素文本完全相同时能够定位到元素。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://www.baidu.com") # 打开百度
inputElement = driver.find_element(By.LINK_TEXT, "新闻") # 文本定位到“新闻”所属标签
idName = inputElement.get_attribute("href") # 获取元素所属标签名称
print(idName)
driver.quit() # 关闭浏览器
运行结果
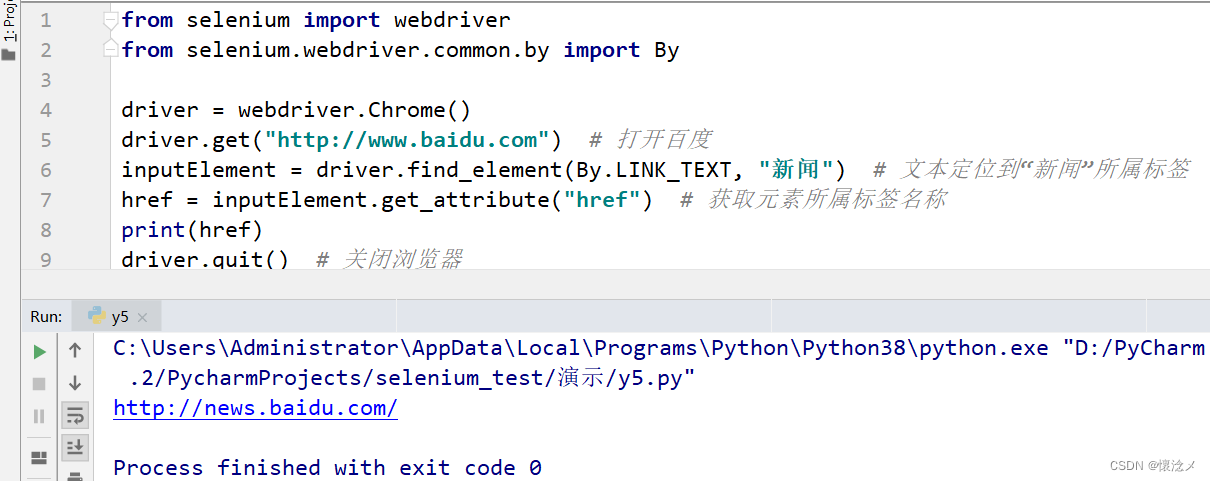
定位到了新闻所属的标签,并且获取到了该标签中的链接地址。
6.元素定位-PARTIAL_LINK_TEXT定位
PARTIAL_LINK_TEXT,通过部分链接文本进行定位,对于有些很长的文本,定位其中的部分文本即可定位到该标签。
比如,定位百度主页下面的京公网安备11000002000001号,这么长的文本,仅需要输入部分文本,即部分文本为目标文本的子字符串。

from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://www.baidu.com") # 打开百度
inputElement = driver.find_element(By.PARTIAL_LINK_TEXT, "京公网安备") # 选择文本包含‘京公网安备"的元素
idName = inputElement.tag_name # 获取元素所属标签名称
print(idName)
driver.quit() # 关闭浏览器
运行结果
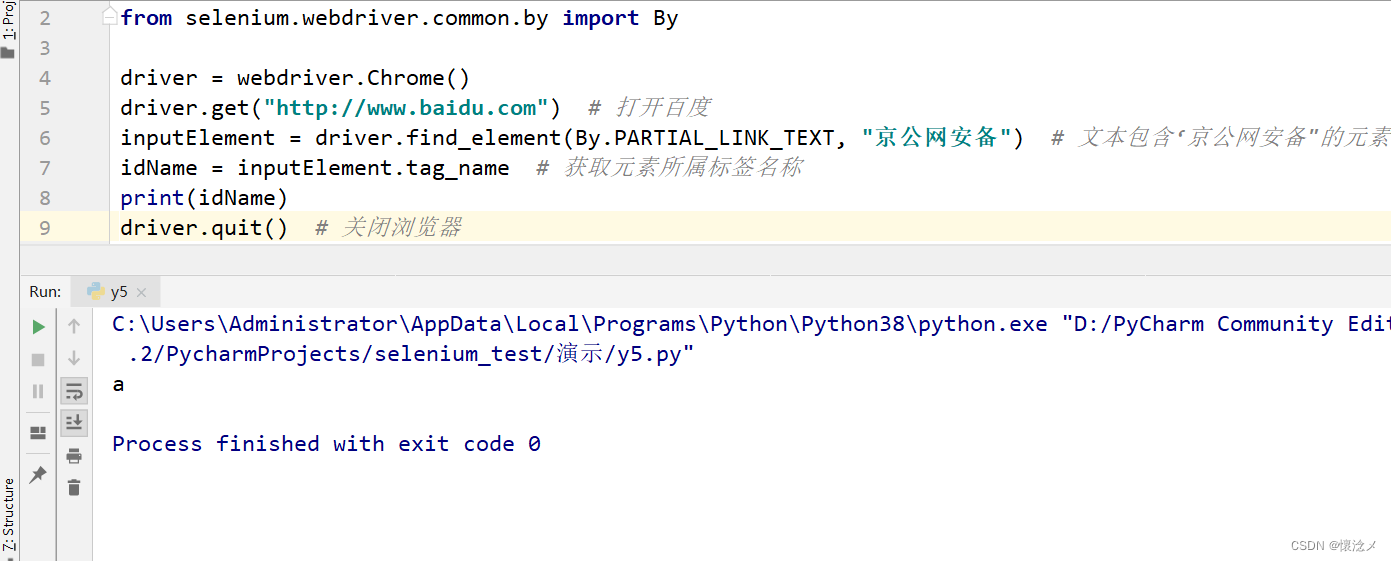
这样就通过部分文本定位到了元素,并且获取到了此元素标签为a标签。
7.元素定位-CSS_SELECTOR定位
CSS使用选择器来为页面元素绑定属性,它可以较为灵活的选择控件的任意属性。
我们仍然选择百度输入框,本次使用css选择器。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://www.baidu.com") # 打开百度
inputElement = driver.find_element(By.LINK_TEXT, "新闻") # 文本定位到“新闻”所属标签
href = inputElement.get_attribute("href") # 获取元素所属标签名称
print(href)
driver.quit() # 关闭浏览器
运行结果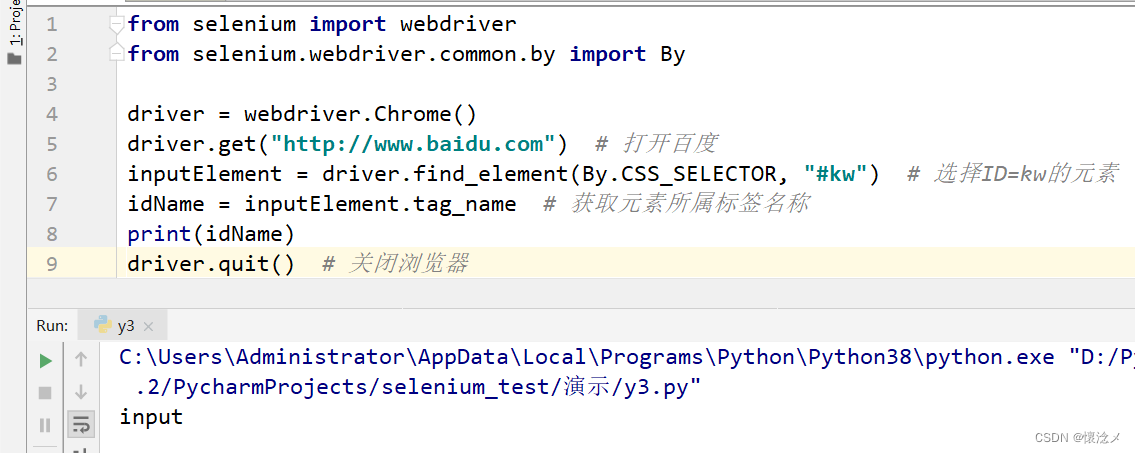
我们先选取了id="kw"的元素,然后通过tag_name 获取该元素的标签名称,确认了定位的标签。
8.元素定位-XPATH定位
Xpath是一种在 XML 文档中定位元素的语言,比较常用。
比如,定位我的博客昵称
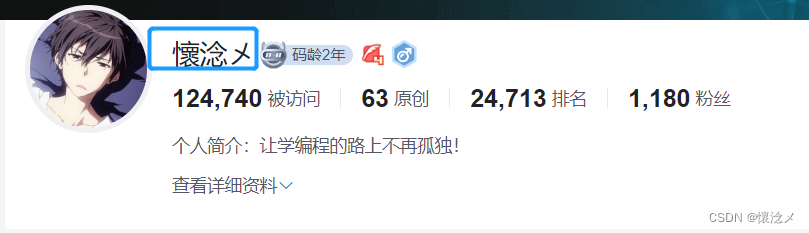
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/a1397852386") # 打开博客主页
inputElement = driver.find_element(By.XPATH, '//div[@class="user-profile-head-info-r-t"]/div[1]/div') # 获取博主昵称
name = inputElement.text # 获取元素的文本内容
print(name)
driver.quit() # 关闭浏览器
运行结果
关于Xpath的语法可以参考:
9.定位一组元素
使用find_elements配合一定的规则以及语句,可以定位一组元素。
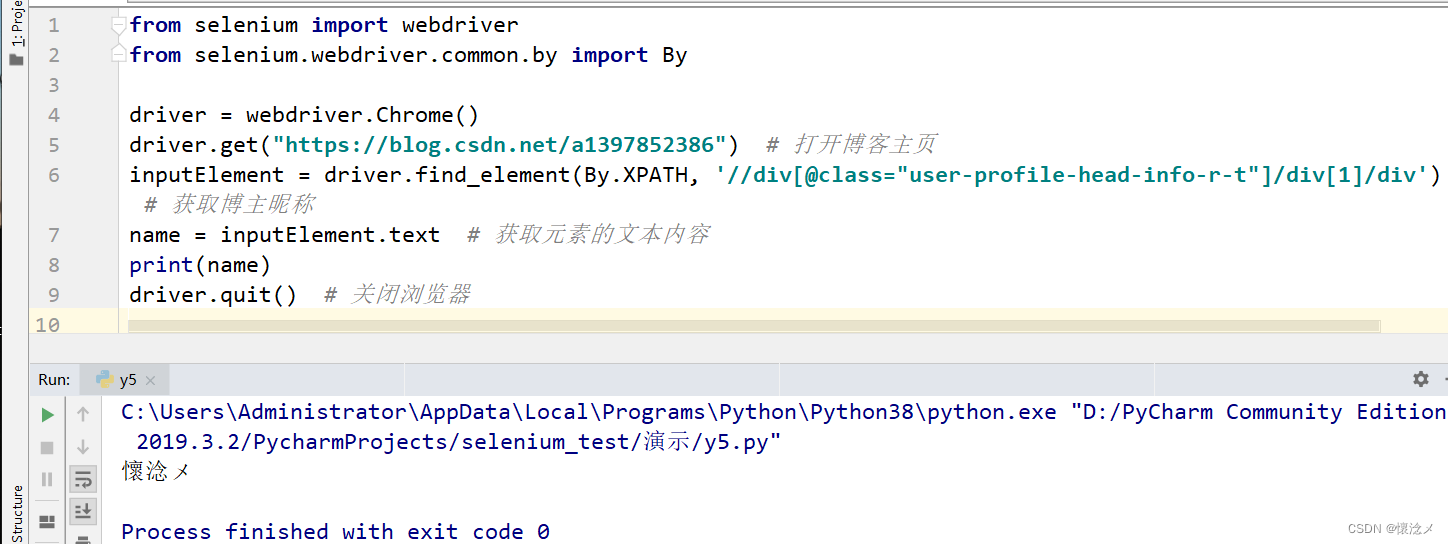
如查找所有文章标题
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/a1397852386") # 打开博客
articles = driver.find_elements(By.XPATH, '//div[@class="blog-list-box-top"]/h4') # 查找所有文章
for article in articles:
print(article.text) # 遍历输出所有文章标题
输出结果
五.浏览器操作
1.浏览器窗口大小控制
使用set_window_size可以修改浏览器窗口的大小
from selenium import webdriver
driver = webdriver.Chrome()
driver.set_window_size(1200, 800) # 修改窗口大小
driver.get("https://blog.csdn.net/a1397852386")
使用minimize_window将浏览器窗口最小化,使用maximize_window将浏览器窗口最大化。
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/a1397852386")
driver.minimize_window() # 最小化浏览器窗口
time.sleep(2)
driver.maximize_window() # 最大化浏览器窗口
2.浏览器前进&后退&刷新
对浏览器的控制还包括控制浏览器前进、后退,使用back控制浏览器返回,使用forward控制浏览器前进。
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/a1397852386") # 打开博客
driver.get("https://www.baidu.com/") # 打开百度
driver.back() # 返回到博客
time.sleep(2) # 睡眠2秒
driver.forward() # 前进到百度
time.sleep(2) # 睡眠2秒
driver.refresh() # 刷新一次
上例中,首先打开博客,再打开百度,然后返回到博客,再前进到百度,最后刷新一次。
3.窗口切换
在实际操作时,可能会涉及多个窗口(tab)之间的切换,使用switch_to.window方法可以进行窗口之间的切换。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/a1397852386") # 打开博客
blog = driver.find_element(By.XPATH, '//span[@title="GUI-PyQt5"]/parent::a') # 选取title="GUI-PyQt5"的span节点的父节点a标签
blog.click() # 单击链接后跳转
window = driver.window_handles # 获取所有窗口的句柄
driver.switch_to.window(window[0]) # 切换回索引为0的窗口
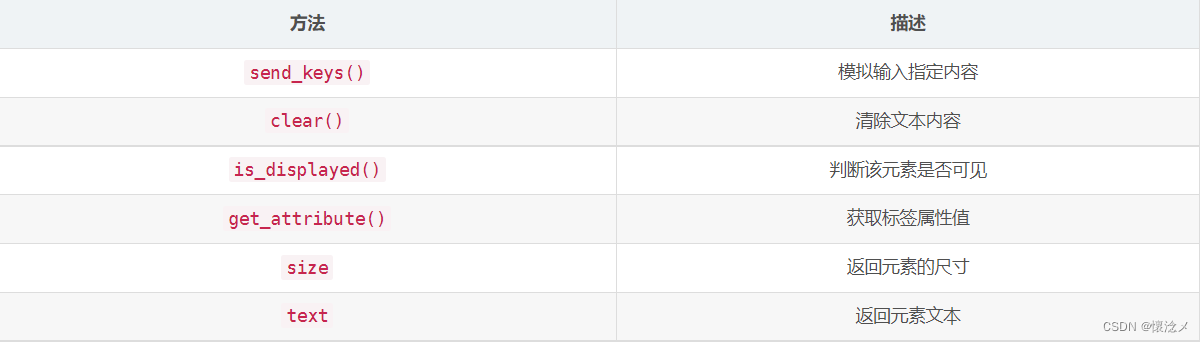
4.webdriver常用操作
5.鼠标控制
- context_click() #右击 --> 此方法模拟鼠标右键点击效果
- double_click() # 双击 --> 此方法模拟双标双击效果
- drag_and_drop() #拖动 --> 此方法模拟双标拖动效果
- move_to_element() #悬停 --> 此方法模拟鼠标悬停效果
- perform() #执行 --> 此方法用来执行以上所有鼠标方法
6.键盘操作
- send_keys(Keys.BACK_SPACE)#删除键(BackSpace)
- send_keys(Keys.SPACE)#空格键(Space)
- send_keys(Keys.TAB)#制表键(Tab)
- send_keys(Keys.ESCAPE)#回退键(Esc)
- send_keys(Keys.ENTER)#回车键(Enter)
- send_keys(Keys.CONTROL,‘a’)# 全选(Ctrl+A)
- send_keys(Keys.CONTROL,‘c’)#复制(Ctrl+C)
7.等待元素
1.implicitly_wait隐式等待
由webdriver提供的方法,一旦设置,这个隐式等待会在WebDriver对象实例的整个生命周期起作用,它不针对某一个元素,是全局元素等待,即在定位元素时,需要等待页面全部元素加载完成,才会执行下一个语句。如果超出了设置时间的则抛出异常。如:设置等待时间如10秒,如果10秒内出现,则继续向下,否则抛异常。可以理解为在10秒以内,不停刷新看元素是否加载出来。
缺点:当页面某些js无法加载,但是想找的元素已经出来了,它还是会继续等待,直到页面加载完成(浏览器标签左上角圈圈不再转),才会执行下一句。某些情况下会影响脚本执行速度。
使用隐式等待
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.implicitly_wait(10) # 隐式等待10秒
driver.get('http://www.baidu.com') # 打开百度页面
element = driver.find_element(By.ID, "kw") # 查找输入框
element.send_keys('selenium自动化测试~') # 输入关键字
2.WebDriverWait显示等待
显示等待是单独针对某个元素,设置一个等待时间如5秒,每隔0.5秒检查一次是否出现,如果在5秒之前任何时候出现,则继续向下,超过5秒尚未出现则抛异常。显示等待与隐式等待相对,显示等待必须在每个需要等待的元素前面进行声明。
需要通过from selenium.webdriver.support.wait import WebDriverWait导入模块
- driver:浏览器驱动
- timeout:最长超时时间,默认以秒为单位
- poll_frequency:检测的间隔步长,默认为0.5s
- ignored_exceptions:超时后的抛出的异常信息,默认抛出NoSuchElementExeception异常。
WebDriverWait()一般由until()或 until_not()方法配合使用
until(method, message=’ ‘):调用该方法提供的驱动程序作为一个参数,直到返回值为True
until_not(method, message=’ '):调用该方法提供的驱动程序作为一个参数,直到返回值为False
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
element = WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located((By.ID, "kw")))
element.send_keys('selenium')
在本例中,通过as关键字将expected_conditions重命名为EC,并调用presence_of_element_located()方法判断元素是否存在。
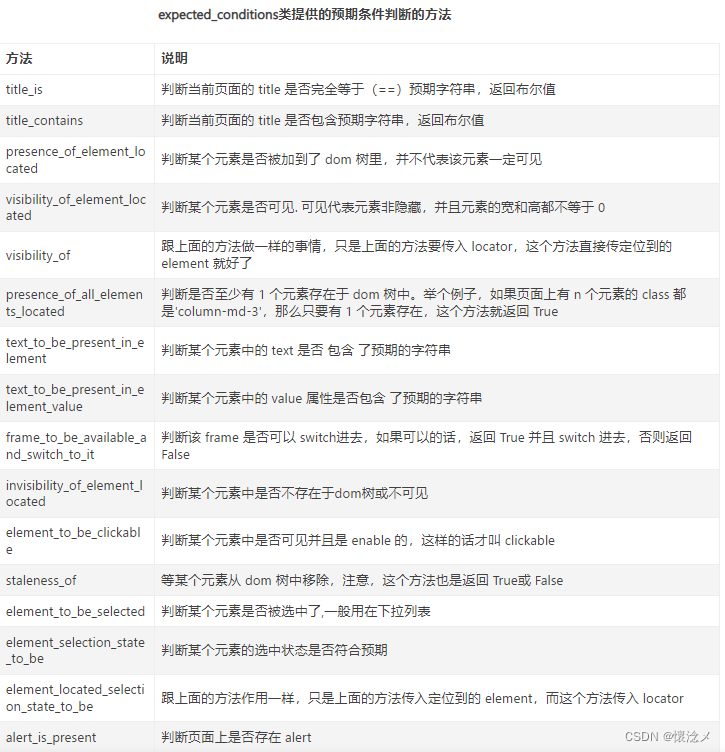
3.强制等待
有时候我们希望脚本在执行到某一位置时暂停一段时间等待页面加载,这时可以使用sleep()方法。
sleep()方法会固定休眠一定的时长,然后再继续执行。sleep()方法默认参数以秒为单位。
使用强制等待
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('http://www.baidu.com') # 打开百度页面
time.sleep(10) # 强制等待10秒
element = driver.find_element(By.ID, "kw") # 查找输入框
element.send_keys('selenium自动化测试~') # 输入关键字
8.执行JS脚本
通过selenium是没有办法实现下拉滚动条,跳出弹窗等js操作,但是支持execute_script方法传递其他操作模拟执行js。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/a1397852386')
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 将滚动条滚动到最下面
driver.execute_script('alert("懷淰メ")') # 执行JS,弹出窗口
以上代码执行后。先是打开播客主页,然后获取滚动条最大值并且将滚动条滚动到最下面,最后弹出对话框,可能操作很快,可以适当地加入延时。
9.iframe切换
什么是iframe?
一个网页里面嵌套了另一个框架/页面,即在一个HTML页面中还内嵌了另外一个HTML页面,只不过这个内嵌的HTML是放在标签对中。
selenium提供了两种方法来获取iframe中的内容:
1.driver.switvh_to.frame(frame_reference)
比如,我们要提取这个网页中的iframe里的元素,需要先定位到此iframe再进行提取。

from selenium import webdriver
import os
from selenium.webdriver.common.by import By
htmlFile = "../testFrame.html"
fileAbs = "file:///" + os.path.abspath(htmlFile)
driver = webdriver.Chrome()
driver.get(fileAbs) # 打开本地html
iframe = driver.find_element(By.TAG_NAME, "iframe") # 定位到iframe
driver.switch_to.frame(iframe) # 切换进入iframe
introEle = driver.find_element(By.XPATH, '//p[@class="introduction-fold default"]') # 定位到个人介绍
print(introEle.text)
2.frame_to_be_available_and_switch_to_it(frame_reference)
此方法会判断iframe是否可用,并且会自动切换到iframe中。
使用以下代码亦能够实现iframe的切换,仅需要传入一个定位器(locator)即可。
from selenium import webdriver
import os
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
htmlFile = "../testFrame.html"
fileAbs = "file:///" + os.path.abspath(htmlFile)
driver = webdriver.Chrome()
driver.get(fileAbs) # 打开本地html
WebDriverWait(driver, 20).until(EC.frame_to_be_available_and_switch_to_it((By.TAG_NAME, "iframe")))
introEle = driver.find_element(By.XPATH, '//p[@class="introduction-fold default"]') # 定位到个人介绍
print(introEle.text)
当页面中iframe中还有iframe时,假如此时我们想进入二级iframe,则需要先进入一级iframe,再进入二级iframe。
3.selenium跳出iframe
①从二级iframe跳到一级iframe,即跳到父级:
driver.switchTo().parentFrame();
#或者
driver.switch_to.parent_frame()
②从iframe跳到主窗口
driver.switch_to_default_content()
#或者
driver.switch_to.default_content()
10.弹窗处理
JavaScript的弹窗有三种——alert(警告框)、confirm(确认框)和prompt(提示框)。可以调用webdriver的相关方法对弹窗进行处理。
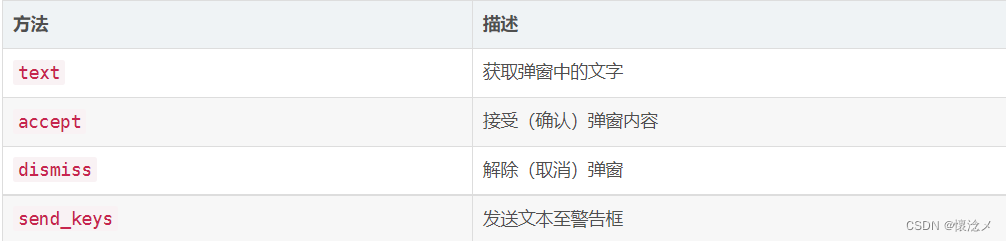
11.浏览器截图
这个功能在日常测试开发中还是比较常用的,Selenium提供了四种截图方法:

下面写个例子测试一下:
from selenium import webdriver
import os
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.save_screenshot("1.png") # 截取当前屏幕截图,并保存为指定文件,filename 为指定的保存路径或图片文件名
driver.get_screenshot_as_file(os.getcwd() + "/" + "2.png") # 获取当前截图,使用完整的路径
print(driver.get_screenshot_as_base64()) # 获取当前屏幕截图 base64 编码字符串
print(driver.get_screenshot_as_png()) # 获取当前截图的二进制文件数据
执行了上面代码,会产生两个截图,文件名分别是1.png和2.png,并且控制台输出了截图的base64编码以及图片的二进制文件数据。
12.webdriver加入参数
我们在使用selenium库调用chromedriver.exe时需要很多的配置参数下面列出了常用参数,可以通过webdriver.ChromeOptions().add_argument()函数将参数加入。
1.常用参数
chrome_options.add_argument(‘–user-agent=“”’) # 设置请求头的User-Agent
chrome_options.add_argument(‘–window-size=1280x1024’) # 设置浏览器分辨率(窗口大小)
chrome_options.add_argument(‘–start-maximized’) # 最大化运行(全屏窗口),不设置,取元素会报错
chrome_options.add_argument(‘–disable-infobars’) # 禁用浏览器正在被自动化程序控制的提示
chrome_options.add_argument(‘–incognito’) # 隐身模式(无痕模式)
chrome_options.add_argument(‘–hide-scrollbars’) # 隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument(‘–disable-javascript’) # 禁用javascript
chrome_options.add_argument(‘–blink-settings=imagesEnabled=false’) # 不加载图片, 提升速度
chrome_options.add_argument(‘–headless’) # 浏览器不提供可视化页面
chrome_options.add_argument(‘–ignore-certificate-errors’) # 禁用扩展插件并实现窗口最大化
chrome_options.add_argument(‘–disable-gpu’) # 禁用GPU加速
chrome_options.add_argument(‘–disable-software-rasterizer’)
chrome_options.add_argument(‘–disable-extensions’)
chrome_options.add_argument(‘–start-maximized’)
2.全部参数
参考官方文档:
https://peter.sh/experiments/chromium-command-line-switches/
3.测试一下参数
就拿常用的设置UA举例子
未加入自定义UA之前
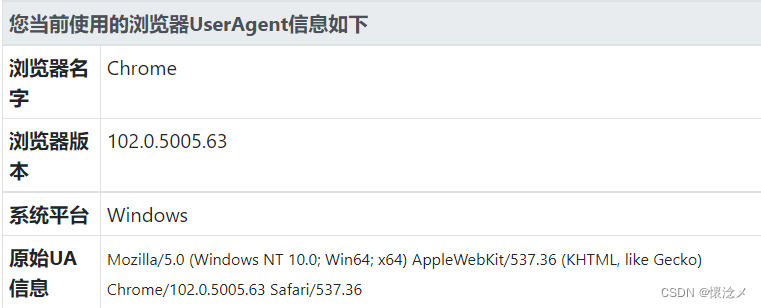
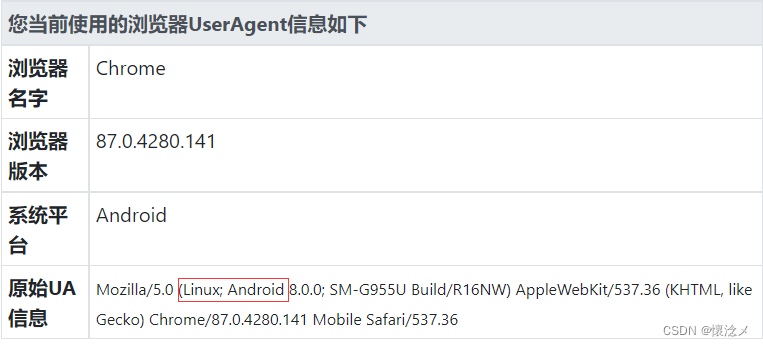
from selenium import webdriver
options=webdriver.ChromeOptions()
options.add_argument(
'User-Agent=Mozilla/5.0 (Linux; Android 8.0.0; SM-G955U Build/R16NW) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Mobile Safari/537.36')#改用安卓手机UA
driver=webdriver.Chrome(chrome_options=options)
driver.get("https://useragent.buyaocha.com/")
加入自定义UA之后
六.实战
1.实战–鼠标键盘操作
本次实现 打开csdn主页-输入框输入Selenium-单击搜索-切换回窗口1-全选页面
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://csdn.net") # 打开博客首页
inputEle = driver.find_element(By.ID, 'toolbar-search-input') # 定位搜索框
inputEle.send_keys("Selenium") # 置入关键词
searchBtn = driver.find_element(By.XPATH, '//button[@id="toolbar-search-button"]') # 定位搜索按钮
searchBtn.click() # 搜索关键词
windows = driver.window_handles # 获取窗口句柄
driver.switch_to.window(windows[0]) # 切换回窗口1
pageHtml = driver.find_element(By.XPATH, '//html') # 选取页面元素
pageHtml.send_keys(Keys.CONTROL, "a") # 全选页面
执行完代码,结果和我一样的,给我点个赞,谢谢~
2.实战-抓取表情包
需求:自动根据关键字对表情包进行搜索,将检索到的表情包原始图片链接提取出来。
import time
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from urllib.parse import urljoin
homePageUrl = "https://fabiaoqing.com/"
driver = webdriver.Chrome()
driver.get(homePageUrl)
searchEle = WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located((By.ID, "searchinput")))
searchEle.send_keys("点赞") # 输入“点赞”
searchEle.send_keys(Keys.RETURN) # 进行搜索
maxHeight = driver.execute_script("return document.body.scrollHeight;")
while True:
driver.execute_script(f'window.scrollTo(0, document.body.scrollHeight)') # 将滚动条滚动到最下面
time.sleep(0.3)
maxHeightNew = driver.execute_script("return document.body.scrollHeight;") # 重新获取最大高度
if maxHeightNew == maxHeight: # 如果当前最大值等于之前最大值,对图片进行解析
picEles = driver.find_elements(By.XPATH,
'//div[@class="ui segment imghover"]/div/a/img') # 查找已经加载出来的图片
for pic in picEles:
picUrl = pic.get_attribute("data-original")
print(urljoin(homePageUrl, picUrl))
break
else:
maxHeight = maxHeightNew # 将新的最大值赋值给最大值
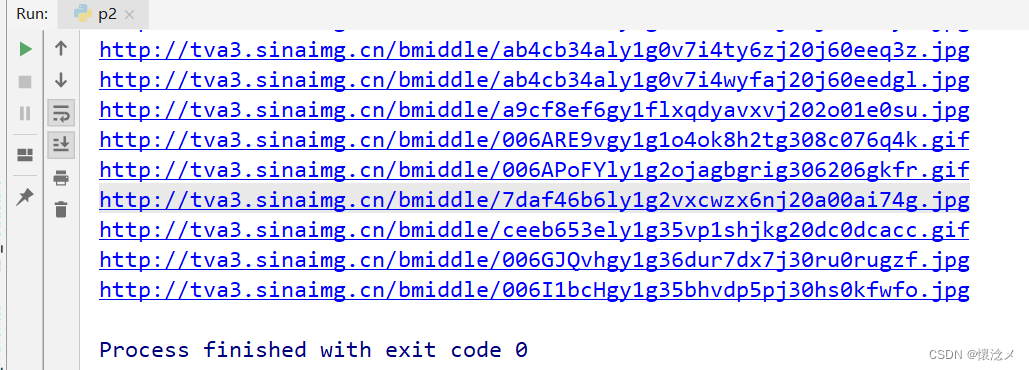
大家的运行结果和我一样吗?
3.实战-浏览器自动截图程序
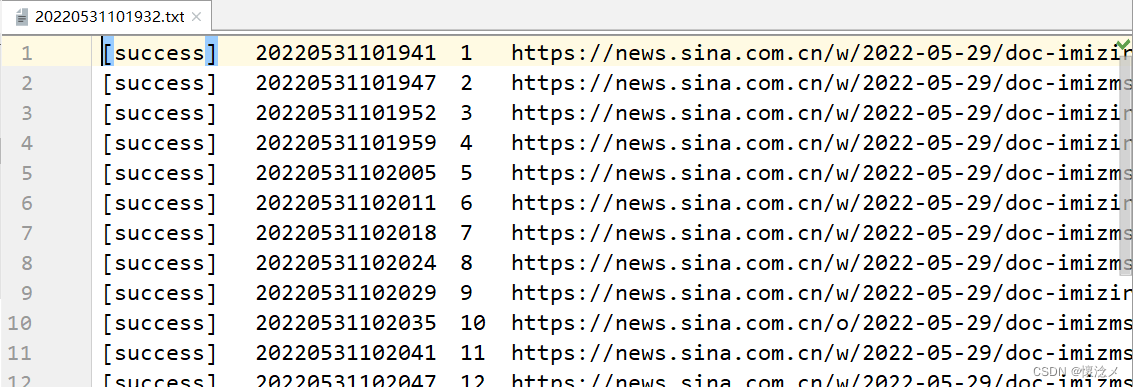
需求:对给定的一批URL进行逐一访问并且截取安卓版网页全图并且声称日志记录,记录访问成功、访问失败、访问超时的网址。
分析:通过设置浏览器参数实现浏览器页面的隐藏、UA设置,执行JS代码获取浏览器最大高度对浏览器进行缩放,调用webdriver的截图函数对浏览器页面进行截图。
AutoScreenShotProgram.py
import os
import time
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, JavascriptException
from selenium.webdriver import ActionChains, Keys
"""
selenium 项目
目标网站自动截图程序
"""
class AutoShotOnWeb(object):
def __init__(self):
self.makeDir("./screenShot")
self.makeDir("./log")
self.logDataFile = self.getTimeString() + ".txt"
def makeDir(self, dir):
"""
创建一个截图存储文件夹
:return:
"""
os.makedirs(dir, exist_ok=True)
def driverInit(self):
"""
驱动初始化
:return:
"""
options = self.getOptions()
# desired_capabilities = DesiredCapabilities.CHROME
# get直接返回,不再等待界面加载完成,提高加载速度
# desired_capabilities["pageLoadStrategy"] = "none"
self.driver = webdriver.Chrome(options=options)
self.setWebDriver()
def getOptions(self):
"""
对驱动进行设置
:return:
"""
options = webdriver.ChromeOptions()
# 使用安卓界面
options.add_argument(
'User-Agent=Mozilla/5.0 (Linux; Android 8.0.0; SM-G955U Build/R16NW) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Mobile Safari/537.36')
# 禁用JS
# options.add_argument('--disable-javascript')
# 必须用隐藏界面的,才能截取完整的图片
options.add_argument('--headless')
# 停用沙箱
options.add_argument('--no-sandbox')
# 禁用GPU实现加速
options.add_argument('--disable-gpu')
# 开启无痕模式
# options.add_argument('--incognito')
# 去掉显示“浏览器正在受自动化控制”
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 忽略证书错误
options.add_argument('--ignore-certificate-errors')
# 指定窗口大小
options.add_argument('--window-size=800,1000')
# 隐藏滚动条, 应对一些特殊页面
# options.add_argument('--hide-scrollbars')
# 静音
options.add_argument('--disable-audio')
# 允许不安全的主机
options.add_argument('--allow-insecure-localhost')
# 停用DNS预读
options.add_argument('--dns-prefetch-disable')
# 不发送 Http-Referer 头
options.add_argument('--no-referrers')
# 阻止chrome弹窗的出现
prefs = {
'profile.default_content_setting_values': {
'notifications': 2}}
options.add_experimental_option('prefs', prefs)
return options
def setWebDriver(self):
"""
对driver进行其它设置
:return:
"""
# self.driver.set_window_size(800, 1000)
# 设置页面超时时间
self.driver.set_page_load_timeout(30)
# 由于截图的是一组网页,所以加入了隐式等待
self.driver.implicitly_wait(30)
def startScreenShot(self):
"""
开始进行截图测试
:return:
"""
urlList = self.getUrls()
for i, url in enumerate(urlList):
url = url.strip()
i+=1
logData = "{}\t{}\t{}\t{}"
flag = self.judgeUrl(url)
print(f"开始处理{
url}")
if flag:
try:
self.driver.get(url)
ActionChains(self.driver).send_keys(Keys.ESCAPE).perform() # 停止http的通信
if self.judgeHaveAlert():
self.driver.switch_to.alert.accept()
self.saveScreenShot(i, url)
log = logData.format("[success]", self.getTimeString(), i, url)
except TimeoutException:
print(f"访问{
url}超时了")
log = logData.format("[timeOut]", self.getTimeString(), i, url)
else:
print(f"{
url}不是标准的url格式!")
log = logData.format("[fail]", self.getTimeString(), i, url)
self.saveAsLog(log)
self.driver.close()
self.driver.quit()
def getUrls(self):
"""
读取要访问截图的网站
:return:
"""
file = './实战/urls/newsUrl.txt'
with open(file, 'r', encoding="utf-8")as f:
urlList = f.readlines()
return urlList
def getTimeString(self):
"""
获取当前日期事件字符串用作图片文件名
:return:
"""
timeString = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time()))
return timeString
def saveAsLog(self, data):
"""
将截图结果写入日志
:param data:
:return:
"""
with open(f'./log/{
self.logDataFile}', 'a', encoding="utf-8")as f:
f.write(data + "\n")
def judgeUrl(self, url: str) -> bool:
"""
判断网站是否为标准url
:param url:
:return:
"""
if url.startswith("http://") or url.startswith("https://"):
return True
else:
return False
def judgeHaveAlert(self):
"""
判断是否有JS Alert
:return:
"""
try:
alert = self.driver.switch_to.alert
return alert
except:
return False
def saveScreenShot(self, number, url):
"""
存储截图文件到本地
:param number:
:param url:
:return:
"""
urlCut = url.split("/")[2].replace(":", "").strip()
timeString = self.getTimeString()
fileName = f"{
number}_{
urlCut}_{
timeString}.png"
print(f"正在存储{
fileName}...")
try:
# 执行JS获取页面的宽高
width = self.driver.execute_script(
"return document.body.scrollWidth;")
height = self.driver.execute_script(
"return document.body.scrollHeight")
except JavascriptException:
width = 800
height = 1200
if width < 800:
width = 800
if height < 1200:
height = 1200
self.driver.set_window_size(width, height) # 将窗口放大到指定大小
self.driver.save_screenshot("./screenShot/" + fileName)
if __name__ == '__main__':
case = AutoShotOnWeb()
case.driverInit()
case.startScreenShot()
输入示例
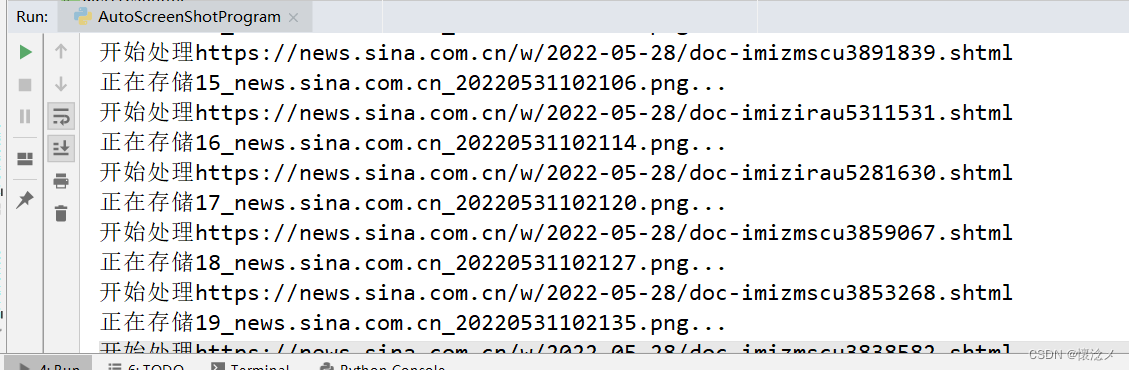
输出
截图

日志
4.实战-抓取某东商品信息
废话不说,上代码
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import selenium.common.exceptions
import json
import csv
import time
class JdSpider():
def open_file(self):
"""
设置结果存储格式
:return:
"""
self.fm = input('请输入文件保存格式(txt、json、csv):')
while self.fm != 'txt' and self.fm != 'json' and self.fm != 'csv':
self.fm = input('输入错误,请重新输入文件保存格式(txt、json、csv):')
if self.fm == 'txt':
self.fd = open('Jd.txt', 'w', encoding='utf-8')
elif self.fm == 'json':
self.fd = open('Jd.json', 'w', encoding='utf-8')
elif self.fm == 'csv':
self.fd = open('Jd.csv', 'w', encoding='utf-8', newline='')
def getOptions(self):
"""
对webdriver进行设置
:return:
"""
options = webdriver.ChromeOptions()
options.add_argument(
'User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36')
# 停用沙箱
options.add_argument('--no-sandbox')
# 禁用GPU实现加速
options.add_argument('--disable-gpu')
# 开启无痕模式
# options.add_argument('--incognito')
# 去掉显示“浏览器正在受自动化控制”
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 忽略证书错误
options.add_argument('--ignore-certificate-errors')
return options
def open_browser(self):
"""
设置driver
:return:
"""
options = self.getOptions()
self.browser = webdriver.Chrome(options=options)
self.browser.implicitly_wait(10)
self.wait = WebDriverWait(self.browser, 10)
def init_variable(self):
self.data = zip()
self.isLast = False
def parse_page(self):
"""
解析网页内容
:return:
"""
try:
skus = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//li[@class="gl-item"]')))
skus = [item.get_attribute('data-sku') for item in skus]
links = ['https://item.jd.com/{sku}.html'.format(sku=item) for item in skus]
prices = self.wait.until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@class="gl-i-wrap"]/div[2]/strong/i')))
prices = [item.text for item in prices]
names = self.wait.until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@class="gl-i-wrap"]/div[3]/a/em')))
names = [item.text for item in names]
comments = self.wait.until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@class="gl-i-wrap"]/div[4]/strong')))
comments = [item.text for item in comments]
self.data = zip(links, prices, names, comments)
except selenium.common.exceptions.TimeoutException:
print('parse_page: TimeoutException')
self.parse_page()
except selenium.common.exceptions.StaleElementReferenceException:
print('parse_page: StaleElementReferenceException')
self.browser.refresh()
def turn_page(self):
"""
网页翻页
:return:
"""
try:
self.wait.until(EC.element_to_be_clickable((By.XPATH, '//a[@class="pn-next"]'))).click()
time.sleep(1)
self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(2)
except selenium.common.exceptions.NoSuchElementException:
self.isLast = True
except selenium.common.exceptions.TimeoutException:
print('turn_page: TimeoutException')
self.turn_page()
except selenium.common.exceptions.StaleElementReferenceException:
print('turn_page: StaleElementReferenceException')
self.browser.refresh()
def write_to_file(self):
"""
将结果写入文件
:return:
"""
if self.fm == 'txt':
for item in self.data:
self.fd.write('----------------------------------------\n')
self.fd.write('link:' + str(item[0]) + '\n')
self.fd.write('price:' + str(item[1]) + '\n')
self.fd.write('name:' + str(item[2]) + '\n')
self.fd.write('comment:' + str(item[3]) + '\n')
if self.fm == 'json':
temp = ('link', 'price', 'name', 'comment')
for item in self.data:
json.dump(dict(zip(temp, item)), self.fd, ensure_ascii=False)
if self.fm == 'csv':
writer = csv.writer(self.fd)
for item in self.data:
writer.writerow(item)
def close_file(self):
self.fd.close()
def close_browser(self):
self.browser.quit()
def crawl(self):
"""
爬取主程序
:return:
"""
self.open_file()
self.open_browser()
self.init_variable()
print('开始爬取')
self.browser.get('https://search.jd.com/Search?keyword=%E7%AC%94%E8%AE%B0%E6%9C%AC&enc=utf-8')
time.sleep(1)
self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(2)
count = 0
while not self.isLast:
count += 1
print('正在爬取第 ' + str(count) + ' 页......')
self.parse_page()
self.write_to_file()
self.turn_page()
self.close_file()
self.close_browser()
print('结束爬取')
if __name__ == '__main__':
spider = JdSpider()
spider.crawl()
结果示例

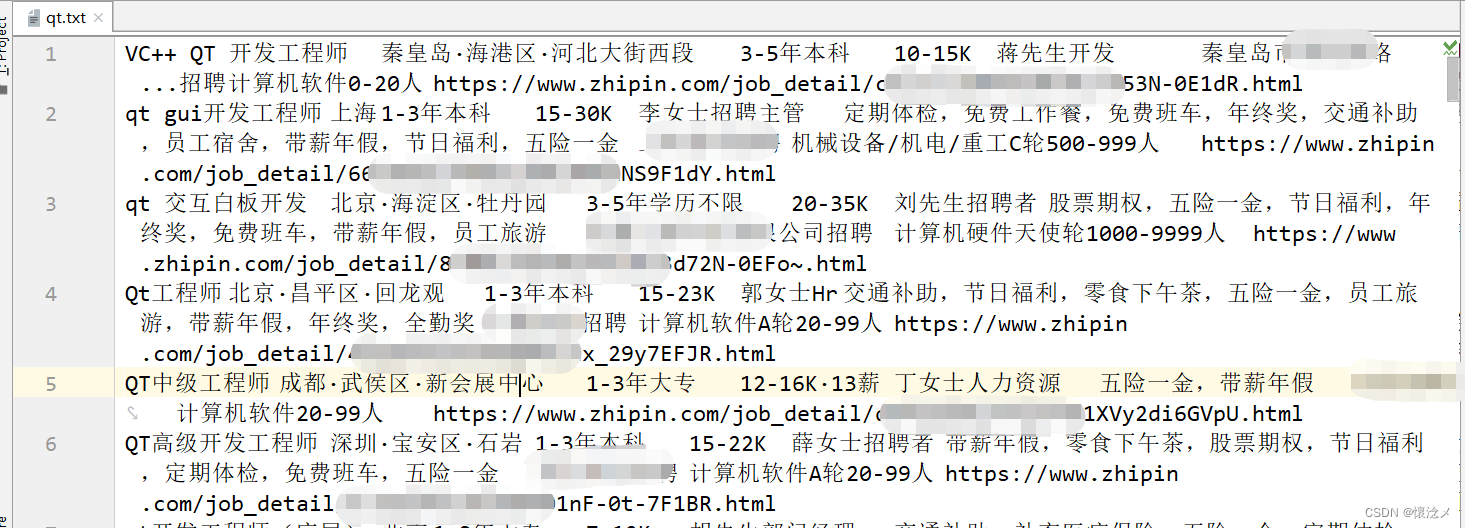
5.实战-抓取xx直聘
import random
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class bossSpider(object):
def __init__(self, keyWord):
self.keyWord = keyWord
self.homePage = f"https://www.zhipin.com/job_detail/?query={
self.keyWord}&city=100010000&industry=&position="
self.flag = True
self.driver_init()
def driver_init(self):
options = webdriver.ChromeOptions()
# 使用自用浏览器
user_directory = r'--user-data-dir=C:\Users\Administrator\AppData\Local\Google\Chrome\User Data'
options.add_argument(user_directory)
# 使用自定义请求头
options.add_argument(
'User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53')
# 取消测试环境
options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.driver = webdriver.Chrome(options=options)
self.driver.implicitly_wait(10)
self.wait = WebDriverWait(driver=self.driver, timeout=10, poll_frequency=0.5, ignored_exceptions=True)
def start(self):
if self.flag:
self.driver.get(self.homePage)
job_names = self.wait.until(EC.presence_of_all_elements_located(
(By.XPATH, '//div[@class="job-list"]//ul/li//div[@class="info-primary"]//span[@class="job-name"]/a')))
job_names = [n.get_attribute('title') for n in job_names]
job_locations = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH,
'//div[@class="job-list"]//ul/li//div[@class="info-primary"]//span[@class="job-area-wrapper"]/span[@class="job-area"]')))
job_locations = [l.text for l in job_locations]
job_reds = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH,
'//div[@class="job-list"]//ul/li//div[@class="info-primary"]//div[@class="job-limit clearfix"]/span[@class="red"]')))
job_reds = [r.text for r in job_reds]
job_limits = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH,
'//div[@class="job-list"]//ul/li//div[@class="info-primary"]//div[@class="job-limit clearfix"]/p')))
job_limits = [r.text for r in job_limits]
hr_names = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH,
'//div[@class="job-list"]//ul/li//div[@class="info-primary"]//div[@class="job-limit clearfix"]/div[@class="info-publis"]/h3')))
hr_names = [r.text for r in hr_names]
company_welfare = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH,
'//div[@class="info-desc"]')))
company_welfare = [w.text for w in company_welfare]
company_names = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH, '//div[@class="job-list"]//ul/li//div[@class="company-text"]/h3/a[1]')))
company_names = [r.get_attribute("title") for r in company_names]
company_status = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH, '//div[@class="job-list"]//ul/li//div[@class="company-text"]/p')))
company_status = [r.text for r in company_status]
job_links = self.wait.until(EC.presence_of_all_elements_located(
(By.XPATH, '//div[@class="job-list"]//ul/li//div[@class="info-primary"]//span[@class="job-name"]/a')))
job_links = [n.get_attribute('href') for n in job_links]
data = zip(job_names, job_locations, job_limits, job_reds, hr_names, company_welfare, company_names,
company_status, job_links)
self.save_data(data)
self.do_scroll()
ret = self.turn_page()
if ret:
self.start()
else:
print("爬完了。。。。")
def turn_page(self):
"""
翻页
:return:
"""
next_page_elemet = self.wait.until(
EC.visibility_of_element_located((By.XPATH, '//div[@class="page"]/a[@ka="page-next"]')))
if next_page_elemet.get_attribute("class") == "next disabled":
return False
else:
# time.sleep(0.5)#点击之前等待一下
self.driver.execute_script("arguments[0].click();", next_page_elemet) # 使用JS点击
# next_page_elemet.click()
self.flag = False
return True
def do_scroll(self):
"""
滚轮随机滑动
:return:
"""
h = random.randint(100, 500)
js_ = "return document.body.scrollHeight;"
real_height = self.driver.execute_script(js_)
js = f"window.scrollTo(0,{
int(real_height-h)})"
self.driver.execute_script(js)
def save_data(self, data):
"""
存储数据
:param data:
:return:
"""
with open(f"{
self.keyWord}.txt", 'a', encoding='utf-8')as f:
for d in data:
line = "\t".join(list(d))
print(line)
f.write(line + '\n')
if __name__ == '__main__':
spider = bossSpider("qt")
spider.start()
结果:
七.总结
本篇简单回顾了一下Selenium的使用方法,通过几个实例代码印证了理论,波卓学习Selenium只是为了做网页爬虫,抓取一些难抓取的数据。本篇已经写了接近三万字了,如果觉得通过本篇能学到点东西的话,麻烦给我点个赞!
