Sklearn的metrics模块下有多个计算模型评价指标的函数,本文只介绍二分类的指标函数。
1.准确率
1.1参数说明
sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)| 解释 | |
|---|---|
| 参数 | y_true 真实的label,一维数组格式 2.y_pred 模型预测的label,一维数组 3.normalize 默认True,返回正确预测的比例,False返回预测正确的个数 4.sample_weight 样本权重 |
| 返回结果 | score:返回正确的比例或者个数,由normalize指定 |
计算公式如下,详情参考http://scikit-learn.org/dev/modules/model_evaluation.html#accuracy-score
1.2 应用
import pandas as pd
import numpy as np
from sklearn import metrics
y_pred = [0,1,0,1]
y_true = [0,0,0,0]## 返回正确率
metrics.accuracy_score(y_pred,y_true)0.5
## 返回正确个数
metrics.accuracy_score(y_pred,y_true,normalize=False)2
2.混淆矩阵
2.1 参数说明
| 参数 | y_true 真实的label,一维数组格式,列名 2.y_pred 模型预测的label,一维数组,行名 3.labels 默认不指定,此时y_true、y_pred取并集,升序,做label 4.sample_weight 样本权重 |
| 返回结果 | C:返回混淆矩阵,注意label |
2.2 应用
y_true = [2, 0, 2, 0, 0, 1]
y_pred = [0, 0, 2, 2, 3, 2]
metrics.confusion_matrix(y_true, y_pred)array([[1, 0, 1, 1],
[0, 0, 1, 0],
[1, 0, 1, 0],
[0, 0, 0, 0]], dtype=int64)
简单说明:y_true和y_pred的并集为[0,1,2,3],对角线为每一类的预测准确率。[1,3]第一行第三例为1,意为实际为2,正确预测为2的样本有1个。这样看还是不直观。官网上有一个可视化混淆矩阵的函数,可以参看http://scikit-learn.org/dev/auto_examples/model_selection/plot_confusion_matrix.html#sphx-glr-auto-examples-model-selection-plot-confusion-matrix-py
import itertools
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()y_test = [1, 1, 1, 0]
y_pred = [1, 1, 0, 0]
# Compute confusion matrix
# #注意混淆矩阵要求预测结果在第一个位置
cnf_matrix = confusion_matrix(y_test, y_pred)
## 限制两位小数
np.set_printoptions(precision=2)# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=[0, 1], title='Confusion matrix, without normalization')
plt.show()Confusion matrix, without normalization
[[1 0]
[1 2]]

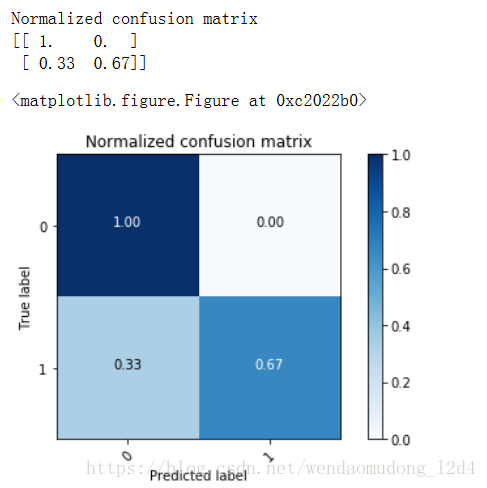
# Plot normalized confusion matrix
plt.figure()
plot_confusion_matrix(
cnf_matrix,
classes=[0, 1],
normalize=True,
title='Normalized confusion matrix')
plt.show()Normalized confusion matrix
[[ 1. 0. ]
[ 0.33 0.67]]
<matplotlib.figure.Figure at 0xc2022b0>
3. Recall&Precision
3.1 参数说明
| 参数 | y_true 真实的label,一维数组格式,列名 2.y_pred 模型预测的label,一维数组,行名 3.labels 默认不指定,此时y_true、y_pred取并集,升序,做label 4.sample_weight 样本权重 5.target_names 行标签,顺序和label的要一致 6.digits int,小数的位数 7. output_dict 输出格式,默认False,如果True,返回字典 |
| 返回结果 | report:返回计算结果,形式依赖于output_dict |
| 文档 | http://scikit-learn.org/dev/modules/generated/sklearn.metrics.classification_report.html#sklearn.metrics.classification_report |
3.2 应用
要注意y_true和y_pred的位置顺序。
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0, 2, 2, 1]
target_names = ['class 0', 'class 1', 'class 2']
print(metrics.classification_report(y_true, y_pred)) precision recall f1-score support
0 0.50 1.00 0.67 1
1 0.00 0.00 0.00 1
2 1.00 0.67 0.80 3
avg / total 0.70 0.60 0.61 5
print(metrics.classification_report(y_true, y_pred, target_names=target_names)) precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
avg / total 0.70 0.60 0.61 5
4.Roc&Auc
计算AUC,画ROC曲线的貌似没有直接的函数。
4.1 参数
| 参数 | y_true 真实的label,一维数组格式,列名 2.y_pred 模型预测的label,一维数组,行名 3.average 有多个参数可选,一般默认即可 4.sample_weight 样本权重 5.max_fpr 取值范围[0,1),如果不是None,则会标准化,使得最大值=max_fpr |
| 返回结果 | report:返回计算结果,形式依赖于output_dict |
| 文档 | http://scikit-learn.org/dev/modules/generated/sklearn.metrics.roc_auc_score.html#sklearn.metrics.roc_auc_score |
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
metrics.roc_auc_score(y_true, y_scores)0.75
2018-07-16 于南京市建邺区新城科技园