一、获取MNIST手写数据集
需要注意的是直接运行下面的代码可能不能直接下载成功,可以从这里先提前(https://download.csdn.net/download/x454045816/10157075) 下载,放到mldata文件夹中,就不会报错了
from sklearn.datasets import fetch_mldata
mnist=fetch_mldata("MNIST original",data_home='./')
mnist
分别获取数据集的特征数据X以及标签数据y
X,y=mnist["data"],mnist["target"]
print(X.shape)
print(y.shape)
可以看到整个数据集一共有70000张图片,每张图片有784个特征(这是因为图片的像素为28*28=784,同时需要了解的是每个像素值介于0~255)
二、分割数据集,创建测试集,注意在创建完测试集后,很长的一段时间只是在训练集上的操作,只有当你处于项目的尾声,当你准备上线一个分类器的时候,才应该使用测试集
1.MNIST数据集将前60000张图片作为训练集,后10000张图片作为测试集
X_train,X_test,y_train,y_test=X[:60000],X[60000:],y[:60000],y[60000:]
2.打乱训练集利用numpy.random.permutation(https://docs.scipy.org/doc/numpy/reference/generated/numpy.random.permutation.html)
import numpy as np
shuffle_index=np.random.permutation(60000)
X_train,y_train=X_train[shuffle_index],y_train[shuffle_index]
三、训练一个二分类器
简化问题,只尝试识别标签0~9中的一个数字,假如识别数字5的二分类器。识别结果为是5和非5
1.由原标签y_train和y_test创建二分类器标签向量
y_train_5=(y_train==5)
y_test_5=(y_test==5)
# print(type(y_train_5))
# print(y_train_5)
2.利用随机梯度下降SGD分类器
好处是能够高效地处理非常大的数据集
from sklearn.linear_model import SGDClassifier
sgd_clf=SGDClassifier(random_state=42)
3.用训练集寻训练模型
sgd_clf.fit(X_train,y_train_5)
四、评估分类器模型
1.利用cross_val_score,实现k折交叉验证,将训练集分成k折,每次从k折中随机一个折作为验证集,另外k-1个折作为训练集,这样就有多少个折就有多少个(1,k-1)个(验证集,训练集)组合的模型性能的accuracy得分
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf,X_train,y_train_5,scoring="accuracy",cv=3)
看似交叉验证时模型的精度(accuracy)平均能大于95%
2.但是我们可以编写一个非常简单的没有实际训练功能的自定义预测值的“非5”二分类器:
fit函数并没有实际的训练功能
predict函数也没有用到训练只是直接会返回一个值为False的len(X)行,1列的numpy数组作为这个判别模型的预测值
numpy.zeros(shape,dtype=float,order='C')说明:
shape:指明数组几行几列
dtype:指明值的类型,当dtype=bool时,值会初始化为False
from sklearn.base import BaseEstimator
class Never5Classifier(BaseEstimator):
def fit(self,X,y=None):
# print ('test-print1')
pass
def predict(self,X):
# print('test-print2')
return np.zeros((len(X),1),dtype=bool)
never_5_clf=Never5Classifier()
cross_val_score(never_5_clf,X_train,y_train_5,scoring="accuracy",cv=3)
可以看到在运用上面毫无实际预测功能只是人工设定预测值的判别器,对于非5的判别accuracy也能高达90%。原因在于只有 10% 的图片是数字 5,所以你总是猜测某张图片不是 5,你也会有90%的可能性是对的。
所以这个小例子说明accuracy通常来说不是一个好的性能度量指标,特别是当你处理有偏差的数据集,比方说其中一些类比其他类频繁得多。
3.利用precision、recall评估模型性能
(1)首先需要了解混淆矩阵,可自行查阅资料,混淆矩阵对角线上的数字是预测标签值和实际标签值一样的个数。
为了得到混淆矩阵,我们应该有对于标签y的预测结果值,通过cross_val_predict实现
(2)关于cross_val_predict函数说明:
cross_val_score是运用了交叉验证返回的是模型性能的score,而cross_val_predict同样也是运用了交叉验证,不过它的目的在于得到预测结果值.它的功能就是返回每条样本作为CV中的验证集时,对应的模型对于该样本的预测结果
from sklearn.model_selection import cross_val_predict
y_train_pred=cross_val_predict(sgd_clf,X_train,y_train_5,cv=3)
# print (len(y_train_pred)==len(y_train))用于验证是不是预测结果和训练输入的数据一样多
利用sklearn可以得到混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5,y_train_pred)
混淆矩阵中的每一行表示一个实际的类, 而每一列表示一个预测的类。该矩阵的第一行认为“非 5”(反例)中的 53272 张被正确归类为 “非 5”(他们被称为真反例,true negatives), 而其余 1307 被错误归类为"是 5" (假正例,false positives)。第二行认为“是 5” (正例)中的 1077 被错误地归类为“非 5”(假反例,false negatives),其余 4344 正确分类为 “是 5”类(真正例,true positives)。一个完美的分类器将只有真反例和真正例,所以混淆矩阵的非零值仅在其主对角线(左上至右下)
(3)由混淆矩阵可以得到Precision和recall
Precision=TP/TP+FP
Recall=TP/TP+FN
可以参考Hands-On Machine Learning with Scikit-Learn and TensorFlow上面的这幅图帮助理解:
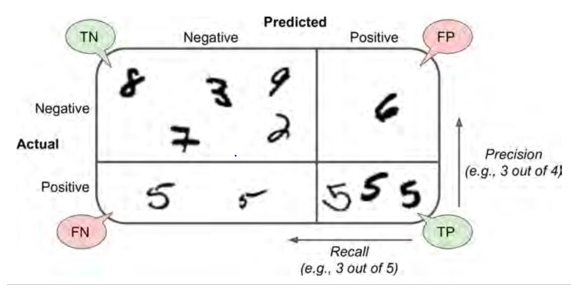
另外,要区分一下accuracy和precision: accuracy = (TP + TN) / (TP + FP + TN + FN)
from sklearn.metrics import precision_score,recall_score
precision_score(y_train_5,y_train_pred)
recall_score(y_train_5,y_train_pred)