教程所需环境:
最近在学习scrapy的过程中,偶然看到一些模拟登陆的文章,就想自己实现模拟登录知乎,结果知乎刚好更新新版本,对Form data进行了加密,由于本人对js了解甚少,无法获取到知乎对表单数据的加密方式,转而实现豆瓣登录。
1. python 3.x
2. request、lxml、pillow等库
1、从目标网页中获取表单数据
豆瓣登录页:
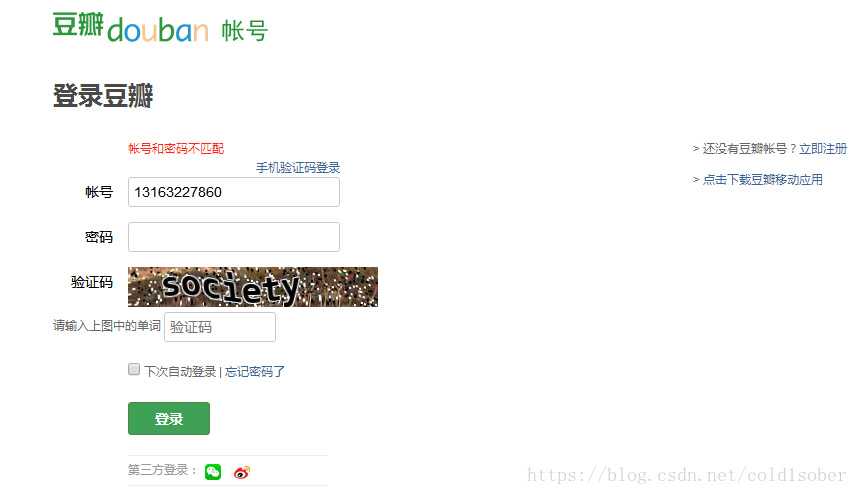
登录豆瓣的请求页分析:
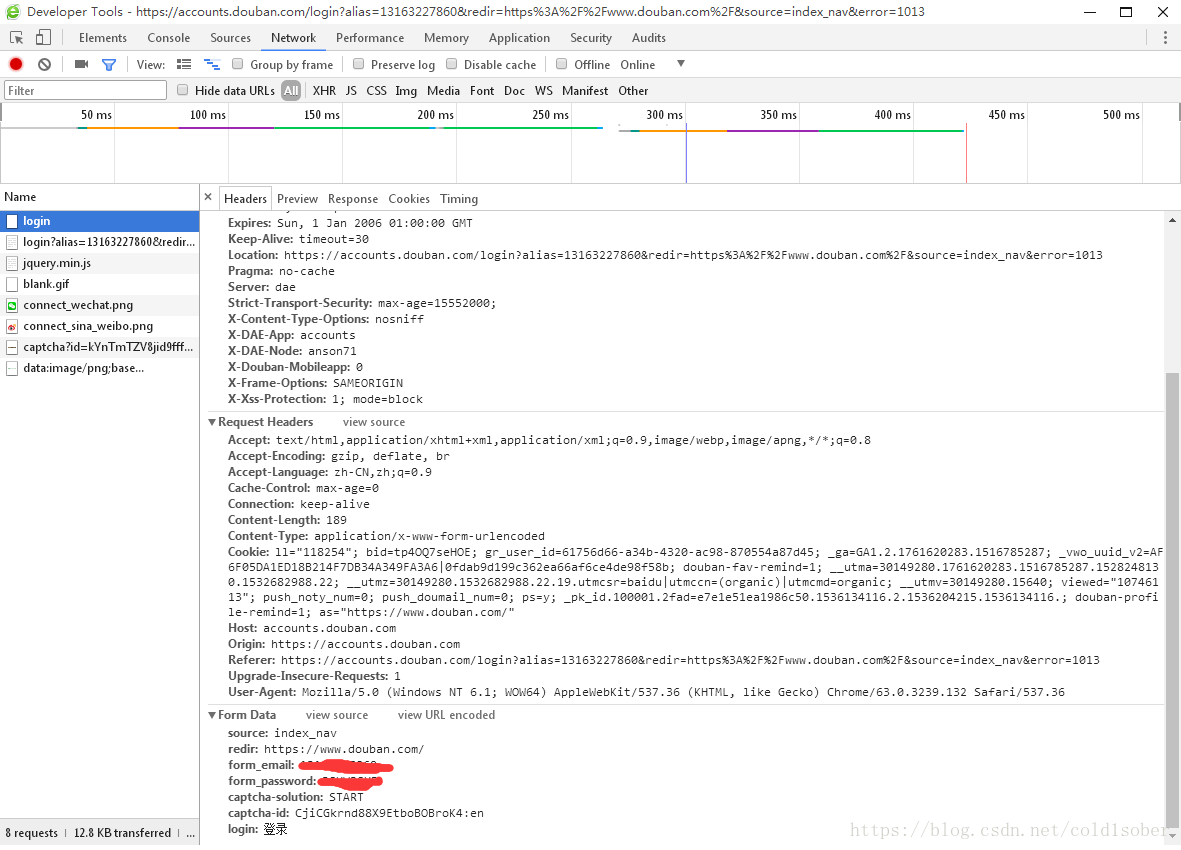
Form data就是我么需要构建的表单数据,从当前登录请求中可以看出豆瓣在传输过程中还是明文传输,并未对表单数据进行加密。表单中各个字段的意义:
source:为固定值,一般为index_nav或者None;
redir:表示登录后加载页面的域名地址;
form_email:你的用户名;
form_password:你的密码;
captcha-solution:验证码信息;
captcha-id:验证码id;
login:固定值,”登录”;
其中,验证码相关captcha-id和captcha-solution在登录界面的源码中都可以提取得到。
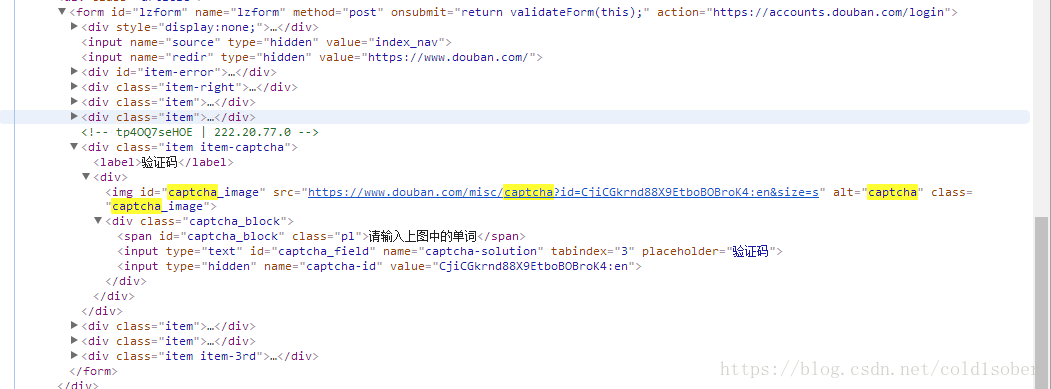
2、验证码识别部分
在模拟登陆第一次登录时,往往要进行验证码的识别,验证码识别可以实现手动输入,下次登录直接加载cookie也不会需要进行任何验证码的识别,出于个人兴趣,简单的试验了下通过pytesseract库实现验证码的自动识别,不过效果并不如人意。
在进行图片处理之前,对验证码进行简单分析:

- 背景图案颜色与字体颜色差别较大;
- 图片中有较均匀的黑色和白色噪点;
- 只有英文单词,没有数字和符号,且字体有轻微扭曲但无遮盖,字体有白色描边;
可以通过PS软件将图片放大之后进行rgb分析,将图片二值化,如图:

可以看出背景已经被二值化去掉,需要处理图片中的噪点,在调用pytesseract库中高斯滤波、中值滤波及均值滤波等方法后,发现中值滤波在人的视角上效果较好。

源码:
from PIL import Image, ImageFilter
import pytesseract
img = Image.open('e:\py3\\captcha.png')
# 滤波去掉背景色
threshold = 21
width, height = img.size
for i in range(0, width):
for j in range(0, height):
p = img.getpixel((i, j))
r, g, b = p
if r > threshold or g > threshold or b > threshold:
img.putpixel((i, j), (255, 255, 255))
else:
img.putpixel((i, j), (0, 0, 0))
# 二值化后的效果图
# img.save('1.jpg')
img = img.filter(ImageFilter.MedianFilter())
img.save('process.jpg')
res = pytesseract.image_to_string(Image.open('process.jpg'), lang='eng')
print(res.strip().lower())3、实现模拟登陆部分
直接上源码:
import requests
import urllib
from lxml import etree
from PIL import Image
from http import cookiejar
class douban_login:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Chrome/67.0.3396.62 Safari/537.36"
}
session = requests.Session()
# 创建一个session对象
session.cookies = cookiejar.LWPCookieJar(filename="cookies.txt")
try:
# 加载已存在的cookie
session.cookies.load(ignore_discard=True)
except:
print("cookies未能加载")
url = 'https://www/douban.com'
login_url = 'https://www.douban.com/accounts/login'
print(session.cookies)
# allow_redirects=false 禁止重定向,通过加载个人主页看是否已经登录
response = session.get(url='https://www.douban.com/people/156403233/', headers=headers, allow_redirects=False)
def islogin(self, username, password):
print(self.response.status_code)
# print(self.response.text)
if self.response.status_code == 200:
print("login successed")
else:
print("login failed")
self.login(username, password)
def login(self, username, password):
post_data = {}
response = self.session.get(url=self.login_url, headers=self.headers)
# print(response.text)
html = etree.HTML(response.text)
captcha_id = html.xpath('//div[@class="captcha_block"]/input[@name="captcha-id"]/@value')
captcha_url = html.xpath('//img[@id="captcha_image"]/@src')
if len(captcha_id)>0:
print("需要输入验证码:")
# 将验证码保存为本地图片
urllib.request.urlretrieve(url=captcha_url[0], filename=r"e:\\py3\\captcha.png")
# 打开本地图片
img = Image.open(r"e:\\py3\\captcha.png")
img.show()
captcha_value = input("请输入验证码:")
post_data = {
"source": None,
"redir": "https://www.douban.com/",
"form_email": '13163227860',
"form_password": 'mjl123456',
"captcha-solution": captcha_value,
"captcha-id": captcha_id[0],
"login": "登录",
}
else:
post_data = {
"source": None,
"redir": "https://www.douban.com/",
"form_email": username,
"form_password": password,
"login": "登录",
}
login_response = self.session.post(url=self.login_url, data=post_data, headers=self.headers)
if login_response.status_code == 200:
print("login success")
# print(self.session.cookies)
# ignore_discard表示即使cookies将被丢弃也将它保存下来;
# ignore_expires表示如果在该文件中 cookies已经存在,则覆盖原文件写入
self.session.cookies.save(ignore_discard=True, ignore_expires=True)
# 辅助信息,确认是否成功登录
logined_html = etree.HTML(login_response.text)
title = logined_html.xpath("//div[@class='content']/div[@class='title']/a/text()")
print(title)
if __name__ == '__main__':
# 输入账号密码
douban_login().islogin("*********", "**********")
第一次登录运行结果(需手动输入验证码,自动识别效果较差,故模块并未加进来):
cookies未能加载
<LWPCookieJar[]>
302
login failed
需要输入验证码:
请输入验证码:muscle
login success
<LWPCookieJar[<Cookie bid=BmVSlyVfkKs for .douban.com/>, <Cookie ck=Bb4u for .douban.com/>,
<Cookie dbcl2="156403233:1DdKuSJ1quM" for .douban.com/>]>
['日本七夕:从传说到现代', '大暑,说围棋', '我奶奶给我的财产,我后来才发现', '【手绘游记】滇西南之行-享受
宁静的夏日时光', '博物君设计监制,守护你的甜美梦乡', '上一次,你感到快乐是什么时候?|马男波杰克,现代人的
精神创伤病理手册', '别去羡慕那些大作家,他们曾经和你一样不想动笔', '永远是孩子——Michael Jackson(上)',
'博物君专访 | 如何被翻牌是一门“玄学”', '这是关于一个传说。', '张辰亮:博物学是无用的吗?', '在“丧”这件
事上,可能没哪个作家比他更彻底 | 纪念太宰治樱桃忌', '端午', '小白放火', '在这里,爸爸变成了离开水的鱼',
'少时并不知,跟父亲自在相处的时光,并非我们想象的无边无际', '尼采说:我们拥有艺术,所以不会被真相击垮',
'韩松落:《阳光灿烂的日子》和《教父》里,为什么都有它出现?']
生成相应cookie后运行结果,不需要手动输入验证码:
<LWPCookieJar[<Cookie bid=BmVSlyVfkKs for .douban.com/>,
<Cookie ck=Bb4u for .douban.com/>,
<Cookie dbcl2="156403233:1DdKuSJ1quM" for .douban.com/>]>
200
login successed