推荐算法介绍
推荐系统在各种系统中广泛使用,推荐算法则是其中最核心的技术点,为推荐系统选择正确的推荐算法是非常重要的决定。目前为止,已经有许多推荐算法可供选择,但为你需要解决的特定问题选择一种特定的算法仍然很困难。每一种推荐算法都有其优点和缺点,当然也有其限制条件,在作出决定之前,你必须要一一考量。在实践中,你可能会测试几种算法,以发现哪一种最适合你的用户,测试中你也会直观地发现它们是什么以及它们的工作原理。
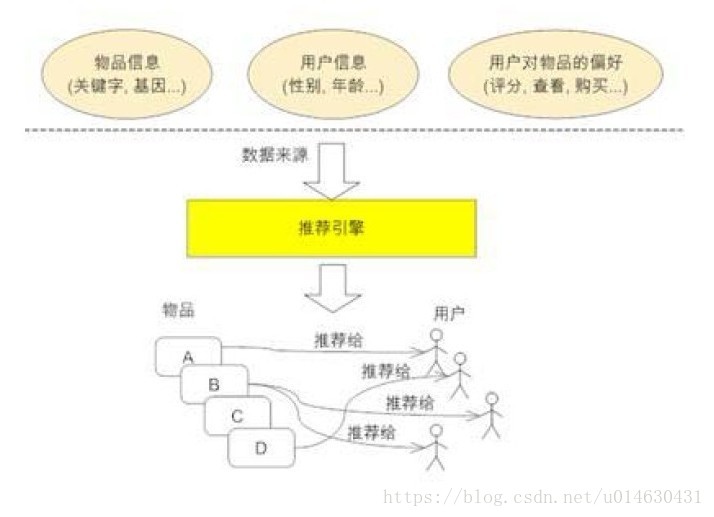
推荐系统算法通常是某类推荐模型的实现,它负责获取数据,例如用户的喜好和可推荐项的描述,以及预测给定的用户组会对哪些选项感兴趣。
推荐引擎根据不同依据有不同的分类:
a. 根据其是不是为不同的用户推荐不同的数据,分为基于大众行为(网站管理员自行推荐,或者基于系统所有用户的反馈统计计算出的当下比较流行的物品)、及个性化推荐引擎(帮你找志同道合,趣味相投的朋友,然后在此基础上实行推荐);
b. 根据其数据源,分为基于人口统计学的(用户年龄或性别相同判定为相似用户)、基于内容的(物品具有相同关键词和Tag,没有考虑人为因素),以及基于协同过滤的推荐(发现物品,内容或用户的相关性推荐,分为三个子类);
c. 根据其建立方式,分为基于物品和用户本身的(用户-物品二维矩阵描述用户喜好,聚类算法)、基于关联规则的(The Apriori algorithm算法是一种最有影响的挖掘关联规则频繁项集的算法)、以及基于模型的推荐(机器学习,所谓机器学习,即让计算机像人脑一样持续学习,是人工智能领域内的一个子领域)。
下面介绍基于流行度的算法、协同过滤算法、基于内容算法、基于模型算法、混合算法。
1. 基于流行度的算法
可以按照一个项目的流行度进行排序,将最流行的项目推荐给用户。比如在微博推荐中,将最为流行的大V用户推荐给普通用户。微博每日都有最热门话题榜等等。
算法十分简单,通过简单热度排序即可。
文章> Predict Whom One Will Follow:Followee Recommendation in Microblogs中推荐好友有一部分采取的策略是Item-popularity.通过计算在训练集中项目(可以是人、群组、公众号)被接受的次数来得到项目的流行度信息。
文章> A Social and Popularity-based Tag Recommender通过结合标签的流行度和邻居意见向用户推荐标签。
缺点:无法提供个性化推荐
优点:算法简单,对于新注册的用户比较有效
改进或者新的思路:加入用户分群的流行度排序,例如把热榜上的体育内容优先推荐给体育迷。这里可以考虑社区发现 聚类等算法
2.协同过滤算法
协同过滤算法(Collaborative Filtering, CF)是很常用的一种算法,在很多电商网站上都有用到,这是利用集体智慧的一个典型方法。随着 Web2.0 的发展,Web 站点更加提倡用户参与和用户贡献,因此基于协同过滤的推荐机制因运而生。它的原理很简单,就是根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐。
基于协同过滤的推荐,可以分为如下几类:
基于用户的推荐(通过共同口味与偏好找相似邻居用户,K-邻居算法,你朋友喜欢,你也可能喜欢),
基于项目的推荐(发现物品之间的相似度,推荐类似的物品,你喜欢物品A,C与A相似,可能也喜欢C),
有的地方对协同过滤算法这样分类:
基于邻域的协同过滤(基于用户和基于项)
基于模型的协同过滤(矩阵因子分解、受限玻尔兹曼机、贝叶斯网络等等)
2.1 基于用户的CF
1、分析各个用户对item的评价(通过浏览记录、购买记录等);
2、依据用户对item的评价计算得出所有用户之间的相似度;
3、选出与当前用户最相似的N个用户;
4、将这N个用户评价最高并且当前用户又没有浏览过的item推荐给当前用户。
首先我们根据网站的记录计算出一个用户与item的关联矩阵,如下,以微博数据为例
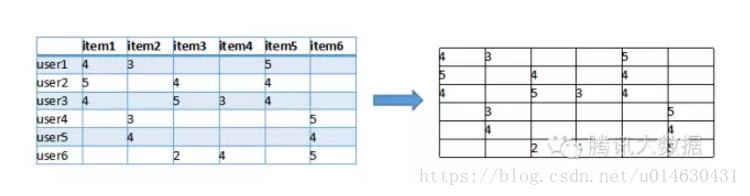
图中,行是不同的用户,列是所有物品,(x, y)的值则是x用户对y物品的评分(喜好程度)。我们可以把每一行视为一个用户对物品偏好的向量,然后计算每两个用户之间的向量距离,这里我们用余弦相似度来算:
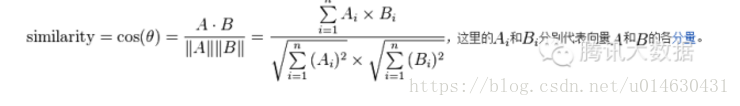
然后得出用户向量之间相似度如下,其中值越接近1表示这两个用户越相似:
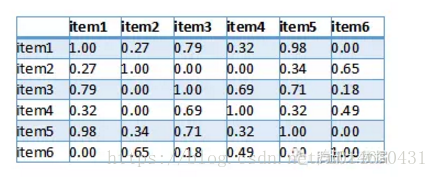
最后,我们要为用户1推荐物品,则找出与用户1相似度最高的N名用户(设N=2)评价的物品,去掉用户1评价过的物品,则是推荐结果。
2.2 基于物品的CF
其原理与基于用户的CF大同小异,只不过主体为物品。
1、分析各个用户对item的浏览记录。
2、依据浏览记录分析得出所有item之间的相似度;
3、对于当前用户评价高的item,找出与之相似度最高的N个item;
4、将这N个item推荐给用户。
其计算方式也大致相同,只是关联矩阵变为了item和item之间的关系,若用户同时浏览过item1和item2,则(1,1)的值为1,最后计算出所有item之间的关联关系如下:
对于微博数据集,item可以指的是被关注者(followee),而item之间的相似度可以通过用户对于item的行为来统计。如果用户对于item有过行为,则可以令偏好值为1。针对用户关注行为列表,可以通过统计item在用户关注列表中的共现次数来计算。

优点:算法简单,一定程度上准确率高
缺点:
1、依赖于准确的用户评分;
2、在计算的过程中,那些大热的物品会有更大的几率被推荐给用户;
3、冷启动问题。当有一名新用户或者新物品进入系统时,推荐将无从依据;
4、在一些item生存周期短(如新闻、广告)的系统中,由于更新速度快,大量item不会有用户评分,造成评分矩阵稀疏,不利于这些内容的推荐。
3. 基于内容的算法
大量的语料库中通过计算(比如典型的TF-IDF算法),我们可以算出新闻中每一个关键词的权重,在计算相似度时引入这个权重的影响,就可以达到更精确的效果。
利用word2vec一类工具,可以将文本的关键词聚类,然后根据topic将文本向量化。如可以将德甲、英超、西甲聚类到“足球”的topic下,将lv、Gucci聚类到“奢侈品”topic下,再根据topic为文本内容与用户作相似度计算。
利用word2vec一类工具,可以将文本的关键词聚类,然后根据topic将文本向量化。如可以将德甲、英超、西甲聚类到“足球”的topic下,将lv、Gucci聚类到“奢侈品”topic下,再根据topic为文本内容与用户作相似度计算。
4 基于模型的算法
基于模型的方法有很多,用到的诸如机器学习的方法也可以很深,这里只简单介绍下比较简单的方法——Logistics回归预测。我们通过分析系统中用户的行为和购买记录等数据,得到如下表:

图中的行是一种物品,x1~xn是影响用户行为的各种特征属性,如用户年龄段、性别、地域、物品的价格、类别等等,y则是用户对于该物品的喜好程度,可以是购买记录、浏览、收藏等等。通过大量这类的数据,我们可以回归拟合出一个函数,计算出x1~xn对应的系数,这即是各特征属性对应的权重,权重值越大则表明该属性对于用户选择商品越重要。
在拟合函数的时候我们会想到,单一的某种属性和另一种属性可能并不存在强关联。比如,年龄与购买护肤品这个行为并不呈强关联,性别与购买护肤品也不强关联,但当我们把年龄与性别综合在一起考虑时,它们便和购买行为产生了强关联。比如,20~30岁的女性用户更倾向于购买护肤品,这就叫交叉属性。通过反复测试和经验,我们可以调整特征属性的组合,拟合出最准确的回归函数。最后得出的属性权重如下:

基于模型的算法由于快速、准确,适用于实时性比较高的业务如新闻、广告等,而若是需要这种算法达到更好的效果,则需要人工干预反复的进行属性的组合和筛选,也就是常说的Feature Engineering。而由于新闻的时效性,系统也需要反复更新线上的数学模型,以适应变化。
5. 混合算法
现实应用中,其实很少有直接用某种算法来做推荐的系统。在一些大的网站如Netflix,就是融合了数十种算法的推荐系统。我们可以通过给不同算法的结果加权重来综合结果,或者是在不同的计算环节中运用不同的算法来混合,达到更贴合自己业务的目的。
参考:
推荐算法分类综述 -> http://baijiahao.baidu.com/s?id=1595347710876973146&wfr=spider&for=pc
推荐算法入门 -> https://blog.csdn.net/qq_17116557/article/details/51145294
推荐算法分类综述 -> https://blog.csdn.net/imail2016/article/details/51570018
协同过滤算法原理-> https://www.cnblogs.com/luminous1/p/8405191.html