从该序列的首元素往后观察,一旦出现乱序现象停止该轮观察,从该乱序元素开始逐个吸收元素组成一个序列,直到该序列所有元素的平均值小于或等于下一个待吸收的元素。
举例:
原始序列:<9, 10, 14>
结果序列:<9, 10, 14>
分析:从9往后观察,到最后的元素14都未发现乱序情况,不用处理。
原始序列:<9, 14, 10>
结果序列:<9, 12, 12>
分析:从9往后观察,观察到14时发生乱序(14>10),停止该轮观察转入吸收元素处理,吸收元素10后子序列为<14, 10>,取该序列所有元素的平均值得12,故用序列<12, 12>替代<14, 10>。吸收10后已经到了最后的元素,处理操作完成。
原始序列:<14, 9, 10, 15>
结果序列:<11, 11, 11, 15>
分析:从14往后观察,观察到9时发生乱序(14>9),停止该轮观察转入吸收元素处理,吸收元素9后子序列为<14,9>。求该序列所有元素的平均值得12.5,由于12.5大于下个待吸收的元素10,所以再吸收10,得序列<14, 9, 10>。求该序列所有元素的平均值得11,由于11小于下个待吸收的元素15,所以停止吸收操作,用序列<11, 11, 11>替代<14, 9, 10>。
package com.immooc.spark
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.regression.IsotonicRegression
import org.apache.spark.{SparkConf, SparkContext}
object Isotonic_Regression {
def main(args:Array[String]): Unit = {
val conf = new SparkConf().setAppName("Isotonic_Regression").setMaster("local[2]")
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
val data = sc.textFile("file:///Users/walle/Documents/D3/sparkmlib/sample_isotonic_regression_data.txt")
val parsedData = data.map{
line=>
val parts = line.split(',').map(_.toDouble)
(parts(0), parts(1), 1.0)
}
val splits = parsedData.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0)
val test = splits(1)
val model = new IsotonicRegression().setIsotonic(true).run(training)
val x = model.boundaries
val y = model.predictions
println("boundaries" + "\t" + "predictions")
for (i <- 0 to x.length -1){
println(x(i) + "\t" + y(i))
}
val predictionAndLabel = test.map{
point =>
val predictedLabel = model.predict(point._2)
(predictedLabel, point._1)
}
val print_predict = predictionAndLabel.collect
println("prediction" + "\t" + "label")
for (i <- 0 to print_predict.length - 1) {
println(print_predict(i)._1 + "\t" + print_predict(i)._2)
}
val meanSquaredError = predictionAndLabel.map { case (p, l) => math.pow((p - l), 2) }.mean()
println("Mean Squared Error = " + meanSquaredError)
}
}
http://www.waitingfy.com/archives/4659
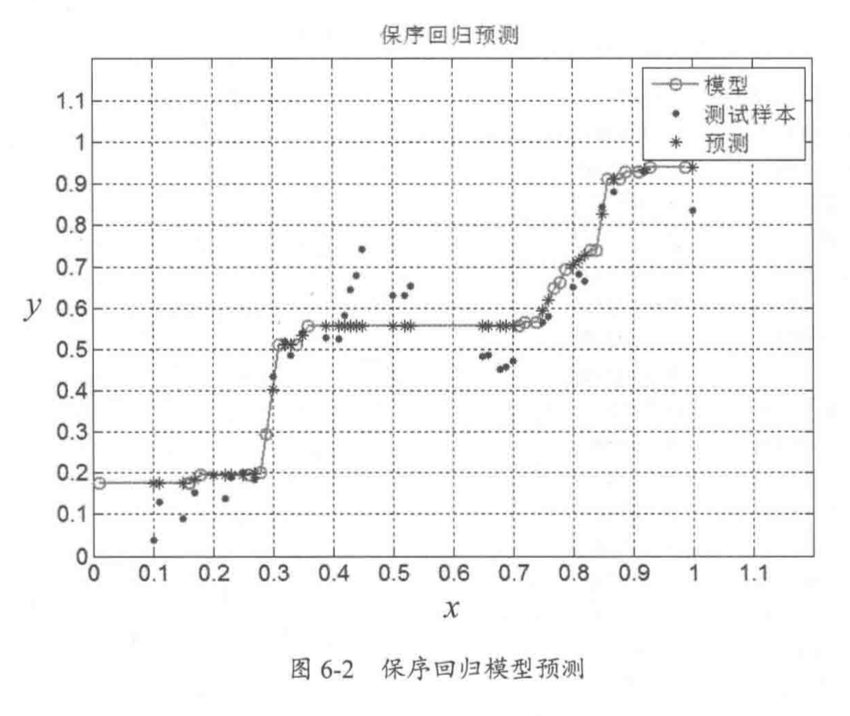
3. Result
boundaries predictions 0.01 0.168689444 0.17 0.168689444 0.18 0.19545421571428573 0.27 0.19545421571428573 0.28 0.20040796 0.3 0.43396226 0.31 0.5275369700000001 0.32 0.5275369700000001 0.35 0.54156043 0.36 0.5602243760000001 0.41 0.5602243760000001 0.44 0.5936596972222222 0.76 0.5936596972222222 0.77 0.64762876 0.79 0.6807751133333334 0.82 0.6807751133333334 0.83 0.73890872 0.84 0.73992861 0.86 0.89673636 0.87 0.89673636 0.9 0.93115757 0.95 0.93472718 1.0 0.93472718 prediction label 0.168689444 0.31208567 0.168689444 0.35900051 0.168689444 0.03926568 0.168689444 0.12952575 0.168689444 0.0 0.168689444 0.01376849 0.168689444 0.13105558 0.19545421571428573 0.13717491 0.19545421571428573 0.19020908 0.19545421571428573 0.19581846 0.31718510999999966 0.29576747 0.5322114566666667 0.4854666 0.5368859433333334 0.49209587 0.5602243760000001 0.5017848 0.5713694830740741 0.58286588 0.5825145901481482 0.64660887 0.5936596972222222 0.65782764 0.5936596972222222 0.63029067 0.5936596972222222 0.65323814 0.5936596972222222 0.67006629 0.5936596972222222 0.51555329 0.5936596972222222 0.33299337 0.5936596972222222 0.36206017 0.5936596972222222 0.4309026 0.5936596972222222 0.48393677 0.5936596972222222 0.48495665 0.5936596972222222 0.4518103 0.5936596972222222 0.47118817 0.5936596972222222 0.58031617 0.5936596972222222 0.55481897 0.5936596972222222 0.56603774 0.6642019366666667 0.66241713 0.6807751133333334 0.65119837 0.818332485 0.84242733 0.9082100966666666 0.90719021 0.9196838333333334 0.93115757 0.931871492 0.91942886 0.932585414 0.9291178 0.933299336 0.95665477 0.934013258 0.9500255 0.93472718 0.89801122 0.93472718 0.90311066 0.93472718 0.9036206 Mean Squared Error = 0.008860256490591361