1.机器学习介绍
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习算法是从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。
机器学习可分为以下几种类别
• 监督学习:输入数据被称为训练数据,它们有已知的标签和结果。常见的算法包括回归分析和统计分类
• 无监督学习:输入数据不带标签或者没有一个已知的结果。常见算法有聚类
• 半监督学习:输入数据由带标签和不带标签组成。有分类和回归
• 强化学习:输入数据作为作为来自环境的激励供给模型,且模型做出反应。反馈作为环境的惩罚或奖赏。包括Q学习,时序差分学习。
常见算法
• 分类和回归-----线性回归、逻辑回归、贝叶斯分类、决策树分类等
• 聚类----KMeans聚类、LDA主题、KNN等
• 关联规则-----Apriori、FPGrowth等
• 推荐-----协同过滤、ALS等
• 神经网络-----BP、RBF、 SVM等
• 深度神经网络等
2.spark介绍
引用官网一句话:Apache Spark™ is a unified analytics engine for large-scale data processing.
Spark, 是一种"One Stack to rule them all"的大数据计算框架, 期望使用一个技术堆栈就 完美地解决大数据领域的各种计算任务。Spark使用Spark RDD、 Spark SQL、 Spark Streaming、 MLlib、 GraphX成功解决了大数 据领域中, 离线批处理、 交互式查询、 实时流计算、 机器学习与图计算等最重要的任务和问题。
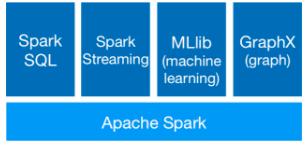
• Spark Core用于离线计算
• Spark SQL用于交互式查询
• Spark Streaming用于实时流式计算
• Spark MLlib用于机器学习
• Spark GraphX用于图计算
3.spark MLlib介绍
spark MLlib 是spark中可以扩展的机器学习库,它有一系列的机器学习算法和实用程序组成。包括分类、回归、聚类、协同过滤、等,还包含一些底层优化的方法
• 机器学习算法:常规机器学习算法包括分类、回归、聚类和协同过滤。
• 特征工程:特征提取、特征转换、特征选择以及降维。
• 管道:构造、评估和调整的管道的工具。
• 存储:保存和加载算法、模型及管道
• 实用工具:线性代数,统计,数据处理等。
