软件准备信息,详见Spark2.2.0集群搭建部署之【软件准备篇】
基础配置信息,详见Spark2.2.0集群搭建部署之【基础配置篇】
SSH无密访问,详见park2.2.0集群搭建部署之【无密访问篇】
将hadoop-2.7.7.tar.gz 进行解压
tar -zxvf hadoop-2.7.7.tar.gz
配置环境变量信息,vi /etc/profile
export HADOOP_HOME=/root/xdb/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"刷新配置, source /etc/profile,以上配置在各个机器均做此操作。
修改$HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk即使环境变量中已经配置,此处必须修改,否则会报“JAVA_HOME is not set and could not be found.”。
修改$HADOOP_HOME/etc/hadoop/slaves
slave1修改$HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/xdb/hadoop-2.7.7/tmp</value>
</property>
</configuration>修改$HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/xdb/hadoop-2.7.7/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/xdb/hadoop-2.7.7/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
</configuration>修改$HADOOP_HOME/etc/hadoop/mapred-site.xml (cp mapred-site.xml.template mapred-site.xml)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:19888</value>
</property>
</configuration>修改$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
复制master节点的hadoop文件夹到slave1上。
scp -r hadoop-2.7.7 slave1:/root/xdb/在master节点启动集群,启动之前格式化一下namenode
hadoop namenode -format启动:
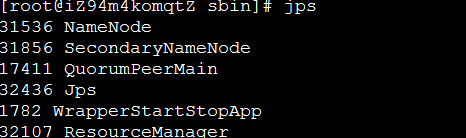
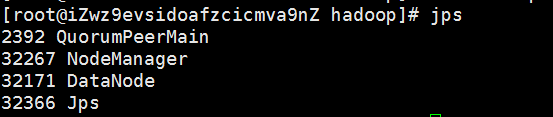
$HADOOP_HOME/sbin/start-all.sh检查,各节点执行 jps
NameNode显示
DataNode显示
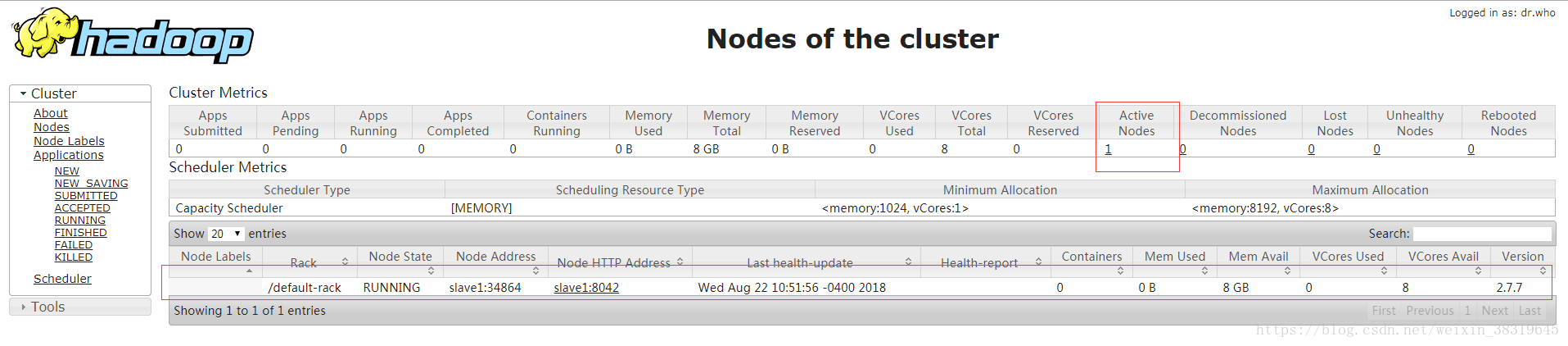
Hadoop管理界面, http://192.168.195.129:8088即可访问,可查看到active nodes节点有一条数据,即slave1.