目录
一、安装Hadoop前的准备
服务器目录约定:
所有的按照文件均放在/export下
/export/package 放置下载的安装包(只在主节点下,其他几点通过scp命令安装)
/export/java安装jdk
备注:
/etc/hostname 作用:给服务器起一个名称
/etc/hosts 作用: 类似Windows下的hosts文件,配置节点的ip和域名对应关系
1、在VMware中构建三台centos7服务器,每个节点对应的hostname和IP如下
node1 192.168.254.101
node2 192.168.254.102
node3 192.168.254.103
用户名和密码:
root 111111
2、设置node1和node2、node3免密钥登录,便于在主节点的配置快速复制到从节点
这里node1设置为master节点,node2和node3位从节点,详细的免密钥登录参考
3、在主节点node1安装jdk然后同步到其他节点
首先下载jdk-7u80-linux-i586.tar.gz包上传到服务器,然后使用tar命令解压安装包
tar zxvf jdk-7u80-linux-x64.tar.gz -C /export/java
配置环境变量 vi /etc/profile,把下面的配置添加到最后
# jdk
export JAVA_HOME=/export/java/jdk1.7.0_80
export JRE_HOME=/$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin然后使用:source /etc/profile
刷新环境变量配置,最后使用java -version

然后使用scp命令,把安装包和环境变量配置同步到其他节点
同步复制安装包:
scp -r /export/java/jdk1.7.0_80 node2:/export/java/jdk1.7.0_80
scp -r /export/java/jdk1.7.0_80 node3:/export/java/jdk1.7.0_80
同步复制环境变量文件:
scp /etc/profile node2:/etc/profile
scp /etc/profile node3:/etc/profile
在node2和node3查看jdk的按照情况
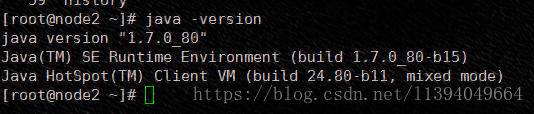
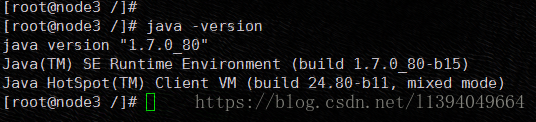
4、关闭每个节点的防火墙
查看防火墙状态 firewall-cmd --state
关闭防火墙 systemctl stop firewalld.service
开启防火墙 systemctl start firewalld.service
禁止开机启动启动防火墙 systemctl disable firewalld.service
二、安装Hadoop
约定目录结构
/export/data HDFS的数据目录
/export/data/hadoop/dfs/name 存放元数据,在hdfs-site.xml中配置
/export/data/hadoop/dfs/data 存放数据目录,在hdfs-site.xml中配置
/export/temp Hadoop的临时文件的目录,在core-site.xml中配置
1、安装Hadoop
首先下载hadoop-2.7.3.tar.gz安装包,并且上传到服务器上,然后使用下面的命令解压安装包
tar zxvf hadoop-2.7.3.tar.gz -C /export/
2、配置Hadoop的环境变量
export HADOOP_HOME=/export/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin 3、修改Hadoop的配置文件
这里要涉及到的配置文件有7个:
/export/hadoop-2.7.3/etc/hadoop/hadoop-env.sh Hadoop环境变量
/export/hadoop-2.7.3/etc/hadoop/yarn-env.sh
/export/hadoop-2.7.3/etc/hadoop/slaves 配置从节点
/export/hadoop-2.7.3/etc/hadoop/core-site.xml Hadoop核心全局配置文件,其他文件的配置项可以覆盖它的配置项
/export/hadoop-2.7.3/etc/hadoop/hdfs-site.xml HDFS配置文件,该模板的属性继承于core-site.xml
/export/hadoop-2.7.3/etc/hadoop/mapred-site.xml MapReduce的配置文件,该模板的属性继承于core-site.xml
/export/hadoop-2.7.3/etc/hadoop/yarn-site.xml
其中mapred-site.xml默认不存在的,可以通过复制mapred-site.xml.template文件获得。
配置文件1:hadoop-env.sh
export JAVA_HOME=/export/java/jdk1.7.0_80配置文件2:yarn-env.sh
export JAVA_HOME=/export/java/jdk1.7.0_80配置文件3:slaves (这个文件里面保存所有slave节点)
node2
node3配置文件4:core-site.xml
<configuration>
//指定hdfs的主端口 namenode要放在哪台机器上
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
//流缓冲区大小 128MB
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/export/temp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>配置文件5:hdfs-site.xml
<configuration>
//Namenode HTTP服务器地址和端口。
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
//存贮在本地的名字节点数据镜象的目录,作为名字节点的冗余备份
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/export/data/hadoop/dfs/name</value>
</property>
//数据节点的块本地存放目录
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/export/data/hadoop/dfs/data</value>
</property>
//备份数
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
//使WebHDFS(REST API)在Namenodes和数据节点
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>配置文件6:mapred-site.xml
<configuration>
//告诉hadoop以后MR(Map/Reduce)运行在YARN上
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>配置文件7:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value> node1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value> node1:8033</value>
</property>
</configuration>4、启动
在启动之前记得格式化namenode空间:hadoop namenode -format
首先切换到安装目录/export/hadoop-2.7.3
由于Hadoop2的架构,数据存放HDFS和计算框架解耦,所以可以分别启动
1)、启动HDFS
./sbin/start-dfs.sh
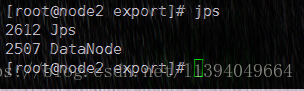
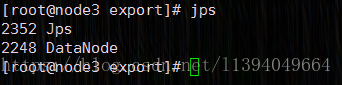
访问HDFS管理界面:http://192.168.254.101:50070

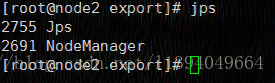
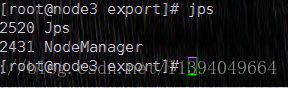
2)、启动yarn
./sbin/start-yarn.sh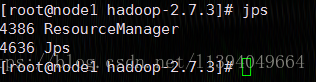
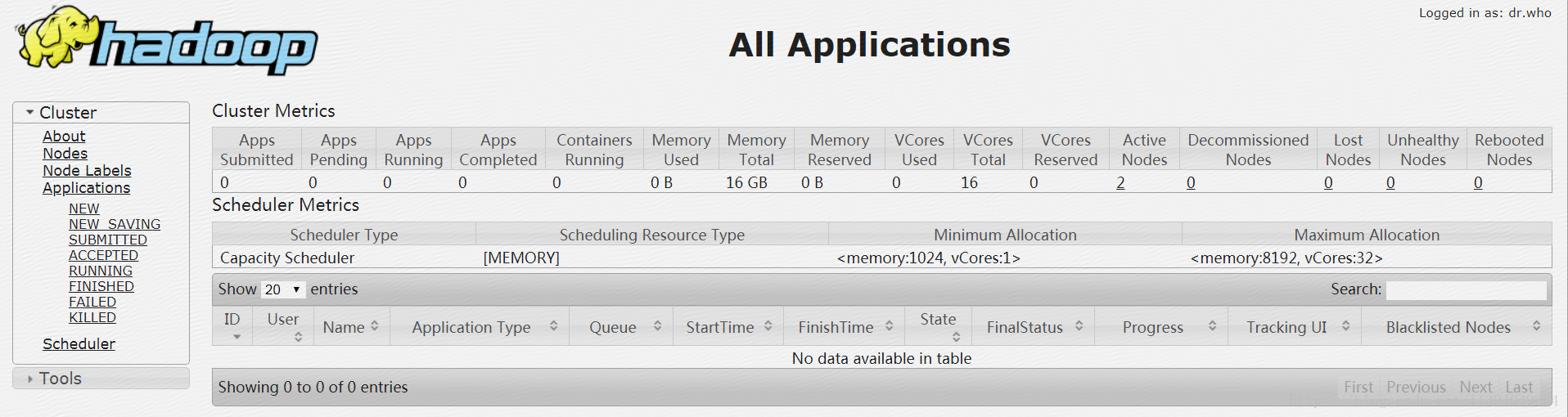
访问MR管理界面:http://192.168.254.101:8088
3、启动全部
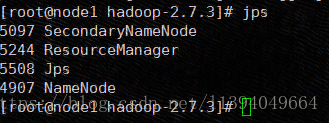
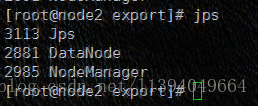
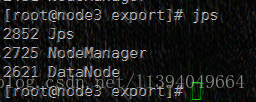
5、Hadoop常用命令说明
| 文件名称 | 说明 |
| hadoop-daemon.sh | 通过执行hadoop命令来启动/停止一个守护进程(daemon);该命令会被bin目录下面所有以start或stop开头的所有命令调用来执行命令,hadoop-daemons.sh也是通过调用hadoop-daemon.sh来执行命令的,而hadoop-daemon.sh本身就是通过调用hadoop命令来执行任务。 |
| start-all.sh | 全部启动,它会调用start-dfs.sh及start-yarn.sh |
| start-dfs.sh | 启动NameNode、DataNode以及SecondaryNameNode |
| start-yarn.sh | 启动MapReduce |
| stop-all.sh | 全部停止,它会调用stop-dfs.sh及start-yarn.sh |
| stop-balancer.sh | 停止balancer |
| stop-dfs.sh | 停止NameNode、DataNode及SecondaryNameNode |
| stop-yarn.sh | 停止MapReduce |
三、安装过程可能遇到的问题
1、启动时候出现
guard.: ssh: Could not resolve hostname guard.: Name or service not known
now.: ssh: Could not resolve hostname now.: Name or service not known
etc/profile配置文件添加
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS=-Djava.library.path=$HADOOP_HOME/lib2、datanode节点起来了,但是没有namenode节点和secondarynode节点,并且启动界面有下面的信息
Starting namenodes on [Java HotSpot(TM) Client VM warning: You have loaded library /export/hadoop-2.7.3/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
这个问题的错误原因会发生在64位的操作系统上,原因是从官方下载的hadoop使用的本地库文件(例如lib/native/libhadoop.so.1.0.0)都是基于32位编译的,运行在64位系统上就会出现上述错误。解决方法之一是在64位系统上重新编译hadoop,另一种方法是在hadoop-env.sh和yarn-env.sh中添加如下两行:
export HADOOP_COMMON_LIB_NATIVE_DIR=/export/hadoop-2.7.3/lib/native
export HADOOP_OPTS="-Djava.library.path=/export/hadoop-2.7.3/lib"
3、启动hadoop时,namenode无法启动,log中出现:java.io.IOException: NameNode is not formatted
解决方案:hadoop namenode -format