本篇博客主要整理基于深度学习的目标检测所用的数据集,
评价指标见上一篇博客。
参考链接:
1、链接1
2、链接2
3、链接3
1、Pascal VOC
VOC综述
VOC数据集是目标检测经常用的一个数据集,从05年到12年都会举办比赛(比赛有task: Classification 、Detection(将图片中所有的目标用bounding box框出来) 、 Segmentation(将图片中所有的目标分割出来)、Person Layout),
然后本篇博客主要整理了VOC2007和VOC2012两个数据集。
然后先介绍一下VOC数据集,以2007版为例。
一共包含了20类。
- person
- bird, cat, cow, dog, horse, sheep
- aeroplane, bicycle, boat, bus, car, motorbike, train
- bottle, chair, dining table, potted plant, sofa, tv/monitor
关于数据集:
- 所有的标注图片都有Detection需要的label, 但只有部分数据有Segmentation Label。
- VOC2007中包含9963张标注过的图片, 由train/val/test三部分组成, 共标注出24,640个物体。
- VOC2007的test数据label已经公布, 之后的没有公布(只有图片,没有label)
- 对于检测任务,VOC2012的trainval/test包含08-11年的所有对应图片。 trainval有11540张图片共27450个物体。
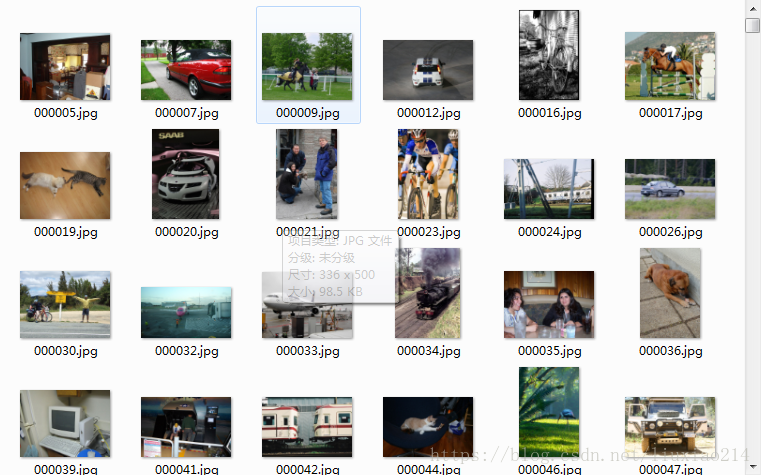
数据集下载完后会有5个文件夹。Annotations、ImageSets、JPEGImages、SegmentationClass、SegmentationObject。
JPRGImages
包含了所有的图片信息,包含训练集和验证集。
以年份和编号命名,尺寸大约为500*375或者是375*500,训练或者验证时会统一resize。
Annotations
存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片

<annotation>
<folder>VOC2007</folder>
<filename>000005.jpg</filename>#文件名
<source>#文件来源
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>325991873</flickrid>
</source>
<owner>
<flickrid>archintent louisville</flickrid>
<name>?</name>
</owner>
<size>#文件尺寸,包括长、宽、通道数
<width>500</width>
<height>375</height>
<depth>3</depth>
</size>
<segmented>0</segmented>#是否用于分割
<object>#检测目标
<name>chair</name>#目标类别
<pose>Rear</pose>#摄像头角度
<truncated>0</truncated>#是否被截断,0表示完整
<difficult>0</difficult>#目标是否难以识别,0表示容易识别
<bndbox>#bounding-box
<xmin>263</xmin>
<ymin>211</ymin>
<xmax>324</xmax>
<ymax>339</ymax>
</bndbox>
</object>
<object>#检测到的多个物体, 可以看到上图中,图片000005中有多个椅子
<name>chair</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>165</xmin>
<ymin>264</ymin>
<xmax>253</xmax>
<ymax>372</ymax>
</bndbox>
</object>
<object>#检测到的多个物体
<name>chair</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>1</difficult>
<bndbox>
<xmin>5</xmin>
<ymin>244</ymin>
<xmax>67</xmax>
<ymax>374</ymax>
</bndbox>
</object>
<object>
<name>chair</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>241</xmin>
<ymin>194</ymin>
<xmax>295</xmax>
<ymax>299</ymax>
</bndbox>
</object>
<object>#检测到的多个物体
<name>chair</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>1</difficult>
<bndbox>
<xmin>277</xmin>
<ymin>186</ymin>
<xmax>312</xmax>
<ymax>220</ymax>
</bndbox>
</object>
</annotation>
对应图片为:

ImageSets
ImageSets中是每一种类型的challenge对应的图像数据。
一共四个文件夹,不知道为什么,win7下载后只有3个文件夹。
- Action下存放的是人的动作(例如running、jumping等等,这也是VOC challenge的一部分)
- Layout下存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分)
- Main下存放的是图像物体识别的数据,总共分为20类。
- Segmentation下存放的是可用于分割的数据。
然后我们主要关注于main文件夹。里面放了20个类的train、val、trainval的txt。
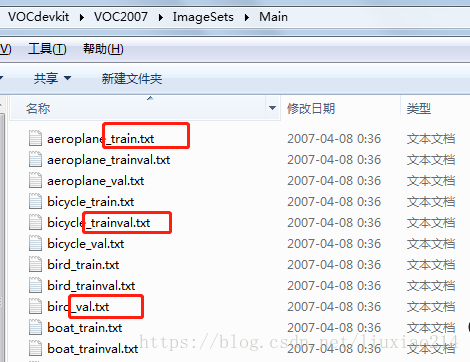
- _train中存放的是训练使用的数据,每一个class的train数据都有5717个。
- _val中存放的是验证结果使用的数据,每一个class的val数据都有5823个。
- _trainval将上面两个进行了合并,每一个class有11540个。
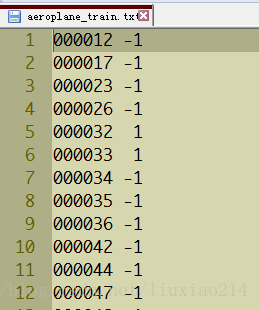
上图中前面代表图片编号,后面-1代表负样本,1代表正样本。
SegmentationClass
这里面包含了2913张图片,每一张图片都对应JPEGImages里面的相应编号的图片。这里面的图片的像素颜色共有20种,对应20类物体。比如所有飞机都会被标为红色。

SegmentationObject
这里面同样包含了2913张图片,图片编号都与Class里面的图片编号相同。这里面的图片和Class里面图片的区别在于,这是针对Object的。在Class里面,一张图片里如果有多架飞机,那么会全部标注为红色。而在Object里面,同一张图片里面的飞机会被不同颜色标注出来。

VOC 2007
Train/Validation Data (439 MB)
Test Data With Annotations (431 MB)
Development Kit
PDF Documentation
VOC 2012
Train/Validation Data (1.9 GB)
Test Data (1.8 GB)
Development Kit
PDF Documentation
2、COCO
和VOC相比,coco数据集,小目标多、单幅图片目标多、物体大多非中心分布、更符合日常环境,所以coco检测难度更大。
1)Object segmentation(2)Recognition in Context(3)Multiple objects per image(4)More than 300,000 images(5)More than 2 Million instances(6)80 object categories(7)5 captions per image(8)Keypoints on 100,000 people
coco数据集以场景理解为目标,从复杂的日常场景中截取,图像中的目标通过精确的Segmentation进行位置的标定,包含91类目标.