Large-scale Bisample Learning on ID Versus Spot Face Recognition
Abstract
在真实的人脸识别应用中,每个人都有两张图像,这是一个巨大的数据量。一个是人脸登记的ID照片,另一个是现场拍摄的probe照片。现有的大多数方法都是针对有限宽度(相对较少的类)和足够深度(每个类有许多样本)的训练数据设计的。它们将在ID versus Spot (IvS)数据上面临巨大的挑战,包括类内变量表示不足和对计算设备的过度需求。在本文中,我们提出了一种基于深度学习的IvS人脸识别的大规模双样本学习(large-scale bisample learning,LBL)方法。针对每个类别只有两个样本的双样本问题,提出了一种分类-验证-分类(CVC)的训练策略,以逐步提高IvS的性能。在此基础上,提出了一种主导原型softmax (dominant prototype softmax ,DP-softmax),使深度学习在大规模类上具有可扩展性。我们在一个超过200万个身份的IvS面部数据集上进行LBL。实验结果表明,该方法取得了较好的识别效果,验证了LBL在IvS人脸识别中的有效性。
1 Introduction
人脸识别技术近年来有了很大的进步,主要是由于网络架构[1,2,3,4,5]、训练策略[6,7,8,9,10,11]和大量的人脸数据[12,13,14,15]的发展。目前的方法主要集中于自然环境的人脸识别,训练数据集通过网络搜索引擎[12]或电子相册应用程序[13]从互联网上采集。大多数自然环境的数据集,如CASIA-Webface[12]、Ms-Celeb-1M[14]和VGG2[15]都是适定的,它们只有有限的类(少于100,000个),每个类有足够的的样本(超过20个)。然而,在许多真实的人脸数据中,情况并非如此,比如ID versus Spot (IvS)人脸识别,其目的是将无约束的现场照片与有约束的ID照片进行匹配,如图1所示。与自然环境数据集相比,IvS数据集面临以下三方面的挑战。
Heterogeneity: ID和现场照片是在不同的环境中拍摄的。这些ID照片是在有约束的环境下拍摄的,背景干净,正面拍摄,光照正常,表情中立。现场照片是在无约束的环境下拍摄的。有姿势,灯光,表情和遮挡(例如,眼镜,发型,围巾等)变化。此外,由于身份证照片每10 - 20年更新一次,身份证照片和现场照片之间可能存在很大的年龄差距。这种异质性增加了IvS人脸识别的难度。
Bisample Data:通常情况下,IvS训练数据是由人脸认证系统收集的。当用户通过认证系统时,他的两张照片将被记录下来,一张是他的身份证照片,另一张是他在网上拍的现场照片。因此,每个受试者只有两个样本。类的内部变异没有很好地表示,使得对双样本数据的判别训练成为一个更具挑战性的问题。
Large-scale Classes: IvS数据由实际系统收集,其中可能有多达数百万甚至数亿个身份。如何在有限的GPU设备下进行如此大规模的深度学习是值得研究的。
这三个特征对IvS人脸识别提出了很大的挑战。在实际应用中,要求高识别率和低错误接受率。为此,在特征空间中,类间样本间有较大边界和类内样本间的紧致性是必要的。然而,由于每个对象只有两个样本,因此很难描述训练阶段的内部变化,使得得到的特征空间不够有区别。此外,还有大量的类。在GPU设备有限的情况下,探索这些类之间的区别信息是一个很大的挑战。以softmax深度学习为例,GPU内存中需要数百万个原型,这对于大多数计算设备来说是不可行的。
在本文中,我们将IvS数据的深度学习问题转化为一个大规模的双样本学习(Large-scale Bisample Learning, LBL)问题,即训练数据包含大量的类,而每个类只有一个正样本对。为了增强现有的训练策略来处理LBL问题,必须解决两个挑战:双样本数据导致的弱内部变化和大量类导致的模型训练可扩展。针对弱的内部变异,提出了一种渐进的模型转移方法——命名为分类-验证-分类(Classification-Verification-Classification,CVC)。通过分类对从网络采集的数据进行预训练,通过验证对IvS数据进行细化处理,得到良好的初始化效果。然后进行大规模的分类,得到最终的IvS模型。
为了提高模型训练的可扩展性,我们在CVC的最后阶段采用了一个原型选择策略,将类softmax的损失扩展到任意数量的类。具体地说,我们观察到softmax的梯度是由一小部分类控制的,而类的近似性可以有效地识别出占主导地位的类。在此基础上,我们为每个类建立一个主导队列,记录其相似的类,从中选择最具主导地位的类参与分类。新的softmax只需要0.15%的类就可以进行有效的训练,大大降低了对计算设备的需求。
TITANX GPU)下达到了最先进的性能。此外,我们还发布了一个包含1262个身份的Public-I vS数据集以供公开评估。此外,为了使我们的工作具有可重复性,我们设计了一个新的协议Megaface-bisample来模拟大规模双样本学习任务。据我们所知,这是在大规模双样本人脸数据上训练深度神经网络的第一次研究。
2 Related Works
在本节中,我们回顾了基于深度学习的人脸识别,并讨论了与LBL任务相关的两个问题:(1)数据不足的学习和(2)大规模分类。
2.1 Deep Learning based Face Recognition
目前有两种训练人脸识别深度模型的方案:分类和验证。分类方案将每个身份看作一个惟一的类别,并将每个样本分类到一个类中。在测试过程中,去除分类层,将顶层特征作为人脸表示[16]。最常见的损失是softmax[16,6,17]。在此基础上,center loss[18]提出学习类特定的特征中心,使特征在嵌入空间中更加紧凑。L2-softmax[19]在特性上增加了l2约束,以促进代表性不足的类。normface[20]对特性和原型进行了标准化,使训练和测试阶段更加接近。近年来,研究发现提高不同类别间的边界是改善特征识别的有效方法,包括large-margin softmax[21]、A-softmax[22]、GA-softmax[23]和AM-softmax[24]。该方案利用分类层中的原型,将样本与其他类区分开来,收敛速度快,泛化能力好。
另一方面,验证方案优化了样本间的距离。在一个小批量中,contrastive loss[7]优化了特征空间中的两两距离,减少了类内距离,扩大了类间距离。triplet loss[8]由一个锚点、一个正样本和一个负样本组成。损失的目的是将正的一对和负的一对在距离上分开。lifted structured loss[25]考虑了所有的小批量内的成对距离,并选择最佳的正样本和负样本。根据局部的softmax公式,n-pairs loss[26]针对所有与正对相关的负对来优化每个正对。此外,为了保证[8]的快速收敛,还广泛采用了hard negative mining来去除容易分辨的负对。最近,[27]提出了一种基于gan的方法来故意生成hard triplet样本,以提高triplet损失训练的效率和有效性。验证方案的性能取决于在一个小批量[25]中生成的对的数量,这是由批量大小决定的。然而,增加批处理大小意味着扩展GPU内存是非常昂贵的。为了降低GPU内存的开销,智能采样[28]在数据层而不是在特征层中选择有价值的对。该方法对损失较大的配对进行记忆,然后选择概率较高的配对[28,9,29]。
目前大多数人脸识别方法都是基于自然环境下的数据集,如CASIA-Webface [12], Ms-Celeb-1M [14], MF2[13]和VGG2[15]。这些适定的数据集具有有限数量的身份,每个身份也有足够的样本。然而,在IvS数据集中却不是这样。表1给出了自然环境下和IvS数据集之间的简要比较:

我们的CASIA-IvS有超过200万个身份,但每个身份只有两个样本,现有的研究方法已经不能很好地工作了。探索ivs特定的训练策略是必要的。
2.2 Learning with Insufficient Data
Low-shot learning旨在通过少量样本[32]识别新类。通常情况下,low-shot学习将知识从一个适定的源域转移到low-shot的目标域。Siamese net[33]通过对源域的同或异分类来训练Siamese CNN,提取目标域的最近邻匹配深度特征。MANN[34, 35,36]通过记忆源域中样本的特征来帮助预测未标记的类。模型回归[37,38]直接将神经网络的权值跨域传递。特征的l2正则化[39,40,41]可以防止网络忽略low-shot类。此外,虚拟样本生成[40,42]和半监督样本[43]被发现在促进low-shot类方面是有效的。虽然low-shot学习和双样本学习都倾向于学习样本不足的概念,但它们的区别在于low-shot 学习属于close-set分类, 双样本学习属于open-set 分类,其中测试样本绝对属于不可见类。
Long-tail problem 指的是只有有限数量的类频繁出现,而其他大多数类却很少出现的情况。在长尾数据上训练的深度模型往往忽略了尾部的类。为了解决这个问题,[44]从tail类中检索更多的样本。[45]通过随机抽样使样本均匀分布。[31]提出了一个范围损失来平衡rich和poor的类,其中最大的类内距离减少,最短的类中心距离增加。
2.3 Large-scale Classification
大规模分类的目的是对大量的类进行分类,其中类的数量达到数百万或数千万。这一任务为深度学习提出了一个大问题:由于参数大小和计算成本过高,不能采用常见的softmax loss。Megaface挑战赛[13]提出了四种方法来在有670k个身份的数据上训练模型。Model-A通过softmax在随机的20,000个身份上训练网络。model-B 使用triplet loss在所有的670k个身份上微调Model-A。Model-C采用rotating softmax,每20个epoch随机选择2600个身份。每次旋转后,softmax层中的参数都被随机初始化。Model-D在所有身份上进一步使用了triplet loss微调Model-C。
在计算机视觉之外,extreme multi-lable leaning[46]和noise contrastive estimation[47]与大规模分类有关。extreme multi-lable leaning学习分类器从一个大的标签集合[46]中用最相关的标签来标记一个样本。它面临着与LBL相同的挑战,即当类数非常大时,训练一个多类分类器在计算上是不可行的。为了解决这个问题,基于树的方法[48,49,50]学习了如下的标签层次结构:根节点包含整个标签集,节点被递归分区,直到每个叶子节点包含少量标签。最后,基分类器只识别一个叶节点中的样本。虽然基于树的方法减少了每个分类器的类数,但是由于它的级联结构[51],在顶层产生的预测错误无法在较低的层次上得到纠正。另一方面,基于嵌入的方法[52,53,54]假设标签矩阵[46],其中每一行是一个样本的一个{0,1}标签向量,是低秩的,标签向量可以投影到一个低维的线性子空间。因此,极端分类任务可以转化为低维回归问题。但是,低秩假设表明样本集中于少量的活动类,而在IvS数据中则不是这样。
Noise Contrastive Estimation(NCE)[47]提供了一种不需要归一化常数的近似估计概率分布的方法,而归一化常数是大规模分类的主要成本开销。其基本思想是训练一个逻辑回归分类器,从数据分布和噪声分布中区分样本,从而将密度估计简化为概率二分类。虽然NCE已经成功地应用于语言模型[55,56,57],但最近的人脸识别任务[7,16]表明,促进类间的对比是训练判别模型的关键。将多类分类转化为二元逻辑回归可能会丢失类间信息,导致性能下降。
3 Large-scale Bisample Learning
该方法为大规模双样本数据的深度学习提供了一条完整的途径。我们首先讨论了分类和验证方案,展示了它们的优点和缺点是如何激发所提出的方法的。然后提出了在双样本数据上训练深度神经网络的方法。最后,我们开发了一个主导原型softmax,以一个可扩展的方式执行200万数据的分类。图2展示了我们的方法的概述:

3.1 Problem Formulation and Motivation
目前有两种深度神经网络的训练方案,即验证和分类。验证方案优化了样本到样本的距离,如contrastive loss[7]和triplet loss[8]。在每个迭代中,它通过使正样本对更接近而使负样本对更远离来在一个小批量数据中执行局部优化。此外,mining策略[8]过滤出容易区分的配对,以快速收敛。另一方面,分类方案将每个身份看作一个唯一的类,并将网络训练成一个N-way分类问题,如softmax[16]和A-softmax[22]。与验证方案相比,分类方案通过将每个样本识别为N个类中的一个来进行全局优化。
在这篇论文中,我们通过比较分类和验证来激发我们的方法。有趣的是,如果我们用公式来表示整个小批量的损失函数,我们可以将这两种方案统一在一个成对匹配和加权的框架中。首先,验证方案利用神经网络提取特征,并对深度特征进行配对;以contrastive loss[7]为例:

其中x为神经网络提取的D维深度特征;X = [x1,…, xM]是mini-batch中的特性,其中M是批大小;如果xj和xk属于同一类,yjk = 1;如果不属于同一类,yjk = 0;NM(·)是hard negative minig,使用阈值τ过滤掉容易区分的负样本对(即大于阈值τ说明容易区分)。我们可以看到,contrastive loss在深层特性X中形成对,并为它们分配{0,1}权重。
相反,分类方案在特征和原型之间建立成对的。以softmax loss[7]为例:

其中W = [w1,…, wN]为softmax层中的原型矩阵,其中N为类的数量,y(j)为xj的标签。其对原型wi和特征xj的导数为:

其中1(·)为指标函数,当语句为真时为1,否则为0, pij为xj属于第i类的概率。考虑到网络训练只涉及反向传播的梯度,我们可以构造一个与等式2具有相同梯度的虚拟softmax loss:
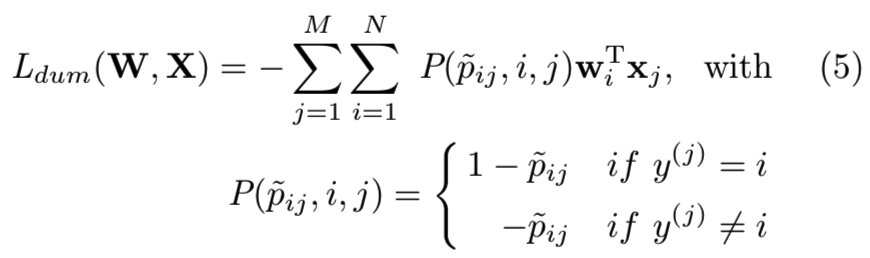
其中![]() 是如等式4中的pij一样计算得到的,被视为一个常数。Lcls和Ldum在网络训练中是等价的,因为它们产生相同的反向传播信号(因为两个式子对原型wi和特征xj求导的结果是相同的)。很明显,Ldum在W和X之间进行配对,并通过概率pij为每一对(wi,xj)分配一个权重。在训练中,概率高的负对和概率低的正对具有更大的权重,产生更大的信号。
是如等式4中的pij一样计算得到的,被视为一个常数。Lcls和Ldum在网络训练中是等价的,因为它们产生相同的反向传播信号(因为两个式子对原型wi和特征xj求导的结果是相同的)。很明显,Ldum在W和X之间进行配对,并通过概率pij为每一对(wi,xj)分配一个权重。在训练中,概率高的负对和概率低的正对具有更大的权重,产生更大的信号。
对比等式5和等式1,我们可以得出分类和验证都遵循相同的成对匹配和加权框架。唯一的区别在于候选项的配对(带有原型的特性与带有内部特性的特性)和加权方法(soft权重与hard权重)。最近的研究从经验上观察到,增加对的数目通常会带来更快的收敛速度和更好的区分能力,因此涉及更多对的损失函数是首选的。在一个以M为批大小,以N为类数量的mini-batch内,分类损失在等式5中产生N×M对,验证损失在等式1中产生M (M−1)/2对。在有限GPU内存的实际实现中,总是N≫M。例如,使用TITAN-X GPU训练ResNet64[21]时,批处理大小M约为50,类数N很容易达到数万甚至数十万。随着数量级对的增加,分类方案有望获得更多的判别特征(因为其能成的对数更多),目前的方法[21,23,24,58]已经证明了这一点。然而,有两个挑战使得IvS数据无法进行分类。首先,我们的实验证明,由于内部变化较弱,分类方案在双样本数据上难以收敛。其次,由于GPU内存有限,分类方案对大规模类的可扩展性较弱。对于目前的优化方法和计算设备来说,直接对每个类两个样本进行200万-way的分类是不可行的。
在本文中,我们利用我们的方法使分类方案在大规模双样本数据上是可行的。为此,应该增强其对双样本数据的鲁棒性和对大规模类的可伸缩性。首先,我们发现只有当双样本数据初始化良好时,分类方案才收敛于双样本数据。因此,我们提出了一种CVC训练策略来初始化模型并构造分类方案的原型。其次,我们提出了一个原型选择策略,将分类方案扩展到任意数量的类。通过改进,我们获得了优于现有方法的性能。
3.2 Bisample Learning
研究发现,当训练数据不足时,从相关任务中转移知识比直接在目标域[33]上训练效果更好(即使用预训练模型)。受此启发,我们将适定的野生数据作为源域,将IvS数据作为目标域。提出了一种分类-验证-分类(CVC)训练策略,将自然环境场景中的知识转移到IvS场景中,通过大规模分类提高训练性能。如图2所示,CVC包括三个阶段:
1.Pre-learning (Classification): 我们首先在一个自然环境下的数据集上训练深度模型,以获得一个良好的初始化来进行一般的人脸识别。由于类的数量有限(少于100,000个),我们可以采用softmax[16]和A-softmax[22]之类的分类损失来执行one-vs-all优化。训练后的模型在自然环境场景中表现良好,但由于较大的偏差[59],在IvS场景中表现很差。尽管如此,该模型已经学习了人脸的基本知识,不会被IvS数据所迷惑。
2.Transfer Learning (Verification): 因为验证方案只涉及到少量的类,每个类只需要两个样本来优化每次迭代的类内距离。我们认为验证对大规模双样本数据是稳健的。在这一阶段,我们采用验证方案将人脸知识从自然环境场景转移到IvS场景。具体地说,我们删除了分类层,并对IvS数据集上的模型进行了细化,使用如contrastive[7]或triplet[8]的验证损失。得益于前一阶段的初始化和验证方案对双样本数据的鲁棒性,我们可以成功地优化损失函数,为最终的大规模分类提供良好的初始化。
3.Fine-grained Learning (Classification): 我们在网络的顶部构建一个分类层,并在IvS数据集上使用200万个类进行分类。在每次迭代中,采用一种新的主导原型softmax来选择少量的主导类参与分类。新的softmax能够有效地、高效地进行大规模分类,进一步提高了性能,最终在IvS场景中实现了令人满意的识别精度。
CVC的关键是知识转移要平稳。我们发现经过第一阶段后,大规模的分类已经能够收敛。然而,损失下降缓慢,优化陷入一个糟糕的局部最优。考虑到验证方案对数据分布具有良好的鲁棒性,我们在两个分类阶段之间搭建了一个验证阶段,使得大规模分类的初始化效果更好,最终获得了更好的性能。虽然在训练网络人脸模型时采用了先分类后验证的[60]联合identification-verification的[7]方法,但这两种方案都是在同一数据集上进行的。CVC的前两个阶段分别应用于不同场景的不同数据集,起到知识传递的作用。
为了在CVC的最后阶段进行分类,我们必须构造一个缺失的分类层,其中包含每个类的原型。将原型作为类的代理,对其深度特征进行优化,利用类的特征构造类的原型。具体来说,我们尝试了两种原型:ID-prototype和avg-prototype。假设xiid和xispot分别是第i个身份的ID照片的深层特性和现场照片的深层特性,我们设置ID-prototype为wiid = xiid和avg-prototype为![]() 。直观地,ID-prototype使现场照片的特征逼近更可靠的ID特征,而avg-prototype使这两个特征逼近它们的质心。我们的实验表明,哪种原型更好取决于损失函数。
。直观地,ID-prototype使现场照片的特征逼近更可靠的ID特征,而avg-prototype使这两个特征逼近它们的质心。我们的实验表明,哪种原型更好取决于损失函数。
在下一节中,我们将介绍如何在CVC的最后阶段进行大规模的分类。
3.3 Large-scale Classification
3.3.1 Random Prototype Softmax
有了初始化良好的网络和原型,剩下的惟一问题是将分类方案扩展到大量的类。如果我们直接对200万个类进行分类,这个庞大的原型将占用1/3的GPU内存(12GB中的4GB),并且由于其参数众多,大大增加了训练时间。
我们的目标是通过降低大规模分类的成本来提高可伸缩性。如图3所示:

我们在每次迭代中选择一部分原型参与分类。在等式5的softmax的配对公式中,给定一个mini-batch X = [x1, ... , xM] ,其中样本有不同的标签,所有的原型W = [w1, ..., wN] (原型使用上面的ID-prototype和avg-prototype得到,N表示类数量)可以分为M个正的原型Wpos和其余的负的原型Wneg。Wpos中的每个原型在X中有一个伙伴组成一个正对,而Wneg中的原型不与X中的任何一个共享类,只组成负对。鉴于M ≪ (N−M),没有必要将整个Wneg放入GPU内存中,因为负对是冗余的。在此基础上,我们提出了一个简单的解决方案,称为随机原型softmax (RP-softmax)。RP-softmax将完整的原型矩阵W存储在内存中。在每次迭代中,首先构造一个临时的原型矩阵![]() ,其中
,其中![]() 从Wneg中随机选择了Niter−M个原型,Niter是被选择的原型的数量。然后将Witer拷贝到GPU中进行训练,并更新到Witer+中。最后,通过用更新的原型替换选定的原型W,Witer+和W是同步的。总体上,算法1列出了原型的选择和更新过程。
从Wneg中随机选择了Niter−M个原型,Niter是被选择的原型的数量。然后将Witer拷贝到GPU中进行训练,并更新到Witer+中。最后,通过用更新的原型替换选定的原型W,Witer+和W是同步的。总体上,算法1列出了原型的选择和更新过程。

超参数Niter在RP-softmax中起着关键作用。较大的Niter带来更多的负对,提供了更丰富的互变信息。然而,增加Niter并不是没有成本的。除了耗时的大矩阵乘法,softmax层必须被阻塞,直到Witer被复制到GPU。有时等待时间超过了前向传播时间。此外,增加Niter会压缩batch size,降低数据驱动层如batch-normalization的质量。因此,Niter是根据经验设置的,以平衡性能和训练时间。在我们的实验中,Niter = 100,000时,RP-softmax显著地改善了IvS场景中的性能。
3.3.2 Dominant Prototype Softmax
虽然RP-softmax使大规模的分类成为可能,但由于它的盲原型选择,使其仍然是低效的。在本节中,我们证明了在原型选择中,真正重要的是质量而不是数量。我们从演示开始,在每个迭代中,只有一小部分的负原型生成强大的梯度。
在等式3中,一个负的wi原型有助于pijwi的反向传播梯度,其范数为pij||wi||。一般情况下,我们规定||wi||为1[22],这样范数将等于pij, pij可以测量出wi对训练过程的影响。在本文中,使用一个mini-batch X = [x1,…, xM],我们将负原型的energy定义为:

其中,pij是xj属于第i类的概率。注意,由于wi是负原型,所以X中没有一个具有i的标签(即选取的mini-batch中没有类i)。为了分析energy是否集中在一小部分原型上,我们进一步将top-K的累积energy定义为:
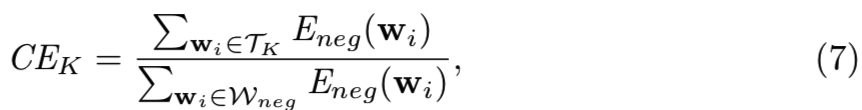
其中Wneg为负原型集合,TK为energy最大的K个负原型集合。较大的CEK和较小的K表示负原型的能量高度集中。我们沿着训练过程绘制CEK,如图4所示:

可以看出,前5000名在开始阶段占有92.71%的能量。随着训练的进行,能量变得越来越集中。在训练过程的中后期,top-5000的能量分别增加到96.09%和98.79%。这些结果表明,只有一小部分原型能够产生大的梯度来影响训练。我们称这些具有大能量的负原型为主导原型(dominant prototypes)。
在实际实现中,给定一组特性,在计算softmax中的概率之前,我们如何知道最主要的原型?在这篇论文中,我们假设如果两个身份具有相似的ID特征,那么它们的原型和特征很可能形成hard 负对。在此基础上,我们提出了主导原型Softmax (dominant prototypes softmax,DP-softmax)。其基本思想是从一组主导队列中选择原型,并通过softmax谓词更新队列。具体操作步骤如下:
Queue Initialization: 对于每个类i,我们将K-Nearest Classes NCK(i)定义为top-K类,这些class具有与i类最接近的ID特征。在训练之前,我们利用ID特征构建一个近似的nearest neighbor (ANN) graph,得到每个类的NCK(i)。然后构造了每个类的主导队列Qi和候选集合Ci。Q由NC100(i)初始化,其成员由ID特征到i类的距离排序。Ci是NC300(i)的集合,其中Qi⊆Ci。(所以其实某个i类的主导队列就是其k近邻中前k个距离最近的其他类)
Prototype Selection: 训练开始后,在每次迭代中,我们需要为mini-batch X = [x1, ... , xM]选择原型。首先,我们选择它的正原型![]() ,其中y(j)是xj的标签类(即正原型就是选定的mini-batch中的每个x对应的类对应的原型)。其次,为每个特征xj选择其主导队列
,其中y(j)是xj的标签类(即正原型就是选定的mini-batch中的每个x对应的类对应的原型)。其次,为每个特征xj选择其主导队列![]() 中类的原型以及全负原型为
中类的原型以及全负原型为![]() 。第三,我们去掉重复的原型和随机选择负原型到
。第三,我们去掉重复的原型和随机选择负原型到![]() 中,直到原型数量到达预设的数量为止。最后,在该迭代中,Wpos和
中,直到原型数量到达预设的数量为止。最后,在该迭代中,Wpos和![]() 构建了临时的原型矩阵Witer,并将其复制到GPU中用于训练。算法2总结了DP-softmax:
构建了临时的原型矩阵Witer,并将其复制到GPU中用于训练。算法2总结了DP-softmax:

Queue Updating: 在每次迭代训练后,我们可以根据softmax的预测更新主导队列。对于xj特征,它的最高激活类h提供了有价值的信息:首先,如果h = y(j),那么它就是一个成功的预测,没有什么需要更新的。其次,如果h 不等于 y(j),但是![]() (说明虽然没有正好将其判定为它真正的类,但是也将其判定为了其最近邻的类),那么这就是一个错误匹配,但是错误匹配的类仍在主导队列。因此我们也不用更新队列。第三种情况就是,
(说明虽然没有正好将其判定为它真正的类,但是也将其判定为了其最近邻的类),那么这就是一个错误匹配,但是错误匹配的类仍在主导队列。因此我们也不用更新队列。第三种情况就是,![]() ,说明在训练过程中,类邻居变化了(说明最近k个邻居没匹配,匹配到了更远的邻居)。因此,需要将这个h类添加到最近邻队列
,说明在训练过程中,类邻居变化了(说明最近k个邻居没匹配,匹配到了更远的邻居)。因此,需要将这个h类添加到最近邻队列![]() 中,并将
中,并将![]() 中与y(j)最不相似的类踢出(有一个进去,就得有一个出来嘛)。最后,如果
中与y(j)最不相似的类踢出(有一个进去,就得有一个出来嘛)。最后,如果![]() 这意味着h和y(j)在一开始有不同的ID特征,但在这个时候变得很接近。造成这种情况的主要原因是h类的现场照片标签有误或者照片质量不高,导致其原型被误导,如图5所示。因此,我们不更新Qy(j),因为h是一个有噪声的标签。
这意味着h和y(j)在一开始有不同的ID特征,但在这个时候变得很接近。造成这种情况的主要原因是h类的现场照片标签有误或者照片质量不高,导致其原型被误导,如图5所示。因此,我们不更新Qy(j),因为h是一个有噪声的标签。

整个原型选择和队列更新操作可以实时完成。与RP-softmax相比,DP-softmax显著提高了质量,减少了原型的数量,导致更快的训练和更好的性能。
由于原型保存在内存中,可以轻松地保存数千万个原型,所以主导原型选择将分类方案扩展到任意数量的类。此外,当新的训练数据到来时,原型矩阵W可以通过新身份的ID特征进行扩展(因为第二步的verification训练已经得到一个初始化的模型了,所以新添加的身份就能够用这个初始化好的模型得到对应的特征,然后使用上面提到的ID-prototype和avg-prototype方法得到其对应的原型值,加入到总原型矩阵W中,然后再在后面的训练中更新)。然后根据整个训练数据对网络进行调整。
4 Experiments
在这一节中,系统地评价了所提出的大规模双样本学习(LBL)。我们首先分析了CVC的训练策略。然后,我们探讨了不同的原型选择方法如何影响最终的性能。最后对CASIA-IvS-Test、Public-IvS和Megaface-bisample三个数据集进行了对比实验。
4.1 Datasets
Ms-Celeb-1M: Ms-Celeb-1M[14]是最大的自然环境下的数据集之一,包含98,685名名人和1,000万张图像。[30]的列表被用来清除有噪声的标签,产生了79,077个身份和500万张图像。
CASIA-IvS: 收集CASIA-IvS数据集进行IvS人脸识别。训练集CASIA-IvS-Train包含2,578,178个身份,每个身份有两个图像。其中一幅是身份证照片,背景统一,正面拍摄,光照正常,表情中性。另一种是现场设备拍摄的现场照片,其姿态、表情、光照、遮挡、分辨率各不相同,如图6所示:

测试集CASIA-IvS-Test包含4000个身份和8000个图像,这些图像被手动检查以清除有噪声的标签,并确保训练集和测试集之间没有身份重叠。在测试过程中,所有的ID照片和现场照片都是成对的,产生了4000个正样本对和近1600万个负样本对。
Public-IvS: 发布IvS测试数据集以供公开评估。我们发现一些公众人物,如政治家、教师和研究人员,在百度百科[61]和官方网页上都有他们的身份证照片。我们记录了他们的名字,并在网上收集了他们的现场照片。然后,我们手动清理数据集并删除侧脸视图的图像。最终的Public-IvS数据集有1,262个身份和5,507张图像,每个身份都有一张身份照片和1到10张现场照片。有4871对正样本和近600万对负样本。图7显示了一些Public-IvS的图像:

尽管Public-IvS并不是严格意义上的IvS数据集(因为现场照片是从web上收集的),但是在Public-IvS上的实验与真实的CASIA-IvS-Test的结果是一致的。
4.2 Experimental Settings
预处理。我们通过FaceBox[62]检测器检测人脸,通过简单的6层CNN定位5个landmarks(两只眼睛、鼻尖和两个嘴角)[63]。所有的人脸都经过相似变换归一化,裁剪成120×120 RGB的图像。
CNN的架构。为了公平起见,实验中的所有CNN模型都遵循相同的ResNet64架构[22]。它有四个residual块,通过平均池化得到一个512维的特征向量。学习率从0.001开始,并在损失没有减少时除以10。所有的网络都并行地训练在4个TITANX GPU上,批量大小被设置为占用所有的GPU内存。具体来说,验证方案中批处理大小为66,分类方案中批处理大小为50。
训练设置。CVC训练策略分为三个阶段:对自然环境下的数据进行分类的预学习、对IvS数据进行验证的转移学习和对IvS数据进行大规模分类的细粒度学习。在第一阶段,我们从零开始在Ms-Celeb-1M数据集上用A-Softmax损失[22]训练模型。在第二阶段,我们使用triplet loss[8]在CASIA-IvS-Train数据集上微调模型。通过N-pairs batch construction[26]、在线hard negative mining[8]和anchor swapping[64]来修改triplet loss。在第三阶段,我们采用提出的DP-softmax在CASIA-IvS-Train数据集微调模型。如未指定,在mini-batch中每个类有两个样本;第三阶段的分类层由ID-prototypes方法初始化;softmax提供概率,A-softmax提供梯度。在DP-softmax中,主导队列和候选集的大小分别为100和300。
评估设置。对于每个图像,我们从原始图像和翻转后的图像中提取特征,并将它们连接起来作为最终的表示。分数是由两个特征的余弦距离来衡量的。我们用ROC曲线来评价所有的网络。在实际应用中,由于错误接受比错误拒绝具有更高的风险,因此在低错误接受率(FAR)下的验证率(VR)更可取。
4.3 Bisample Training
4.3.1 Classification-Verification-Classification (CVC)
为了说明CVC的有效性,我们在表2中显示了中间结果:
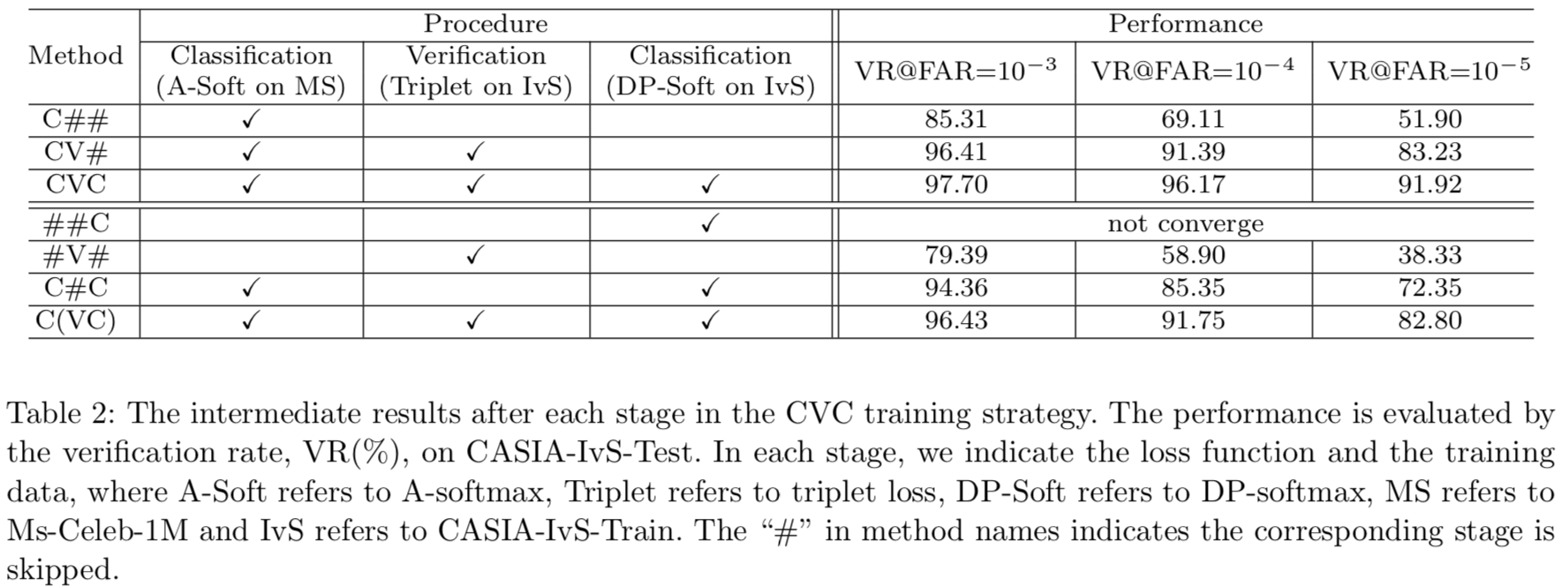
在第一阶段之后,c# #是一个在自然环境场景中训练良好的模型,在LFW上是99.53%[65],在FAR=10−6的Megaface挑战[13]上是90.38%。然而,最先进的人脸模型在CASIA-IvS-Test上不能很好地工作,这表明两种场景之间存在较大的偏差。其次,在经过使用triplet loss在CASIA-IvS-Train数据集上优化后,CV#获得了更好的性能,这表明知识已经成功地从自然环境场景转移到IvS场景。最后,CASIA-IvS-Train上的大规模分类进一步提高了性能,FAR=10−5时达到91.92%。
为了进一步分析每个阶段的影响,我们进行了消融研究,删除了一些阶段。首先,在##C中,我们直接对IvS数据执行大规模的分类,而不进行任何初始化,并发现经过20万次迭代后,损失并没有减少。其次,我们尝试在IvS数据上使用triplet loss从零开始训练模型。由于学习任务在没有初始化的情况下是具有挑战性的,所以我们在开始时没有使用hard negative mining,并且稍微增加了hard negative的比例。训练收敛,但模型#V#有一个糟糕的结果。第三,我们在自然环境的数据上对模型进行预训练,并通过大规模分类直接对IvS数据进行细化。训练成功收敛,但生成的C#C比完整的CVC差。最后,在对自然环境的数据进行预处理后,我们对IvS数据进行联合验证和大规模分类,得到了C(VC)模型,该模型也不如完整的CVC。结果表明:(1)通过比较##C、C#C和CVC,良好的初始化对于双样本数据的大规模分类是至关重要的。(2)与C#C、CV#和CVC相比,验证方案在处理大规模双样本数据时比分类方案具有更高的可扩展性,但不能单独获得令人满意的性能。(3)与C#C、C(VC)和CVC相比,在知识转移过程中,平滑性是非常重要的,最好将这两个分类阶段与验证阶段连接起来。
在CVC学习中,我们观察到一些有趣的现象。首先,我们发现第一阶段的自然环境下的性能对最后的IvS的性能的影响。我们从两个具有不同自然环境下的性能的预训练模型开始(LFW数据下,使用triplet loss时为98.0%,A-softmax时为99.53%),并发现它们最终的IvS表现略有不同(IvS数据下 ,当FAR= 10−5时分别为91.23%和91.92%)。其次,在IvS数据进行微调处理后,发现该模型不能保持较高的自然环境下的性能。我们在CASIA-IvS-Test和LFW数据中对模型进行评估[66],如表3所示:

在CVC的各个阶段后,IvS的性能得到了提高,但代价是退化的自然环境下的性能。我们进一步在两种场景的联合数据上训练我们的模型,发现在IvS略有下降的情况下,自然环境下的性能有了很大的改善。这种联合训练在两种情况下都是很好的策略。
4.3.2 Prototype Construction
如第3.2节所介绍的,在大规模分类中构造原型有两种方法:ID-prototype是使用ID照片的特征,而avg-prototype是使用该类中所有特征的平均向量。构建原型的方法取决于所涉及的损失函数。我们选择最具代表性的softmax[16]和最先进的A-softmax[22]作为实验对象。表4显示了不同loss和原型的性能。

当采用softmax时,由avg-prototype初始化的模型在一开始几乎是收敛的,损失只是产生很小的梯度。如果我们用id-prototype代替了avg-prototype, softmax的损失将会有更大的初始损失,并最终得到更好的结果。当A-softmax被采用时,角边际(angular margin)保持初始损失足够大,两个原型以接近的性能结束。在我们的实验中,我们更喜欢使用ID-prototype,并且只在没有ID照片的情况下才使用avg-prototype,就像4.7中的模拟实验一样。
4.4 Large-scale Classification
在大规模的分类中,我们需要每次选择一部分原型。在第3.3节中,我们介绍了两种原型选择方法:一种是随机选择原型,另一种是选择主导原型。
4.4.1 Random Prototype Softmax
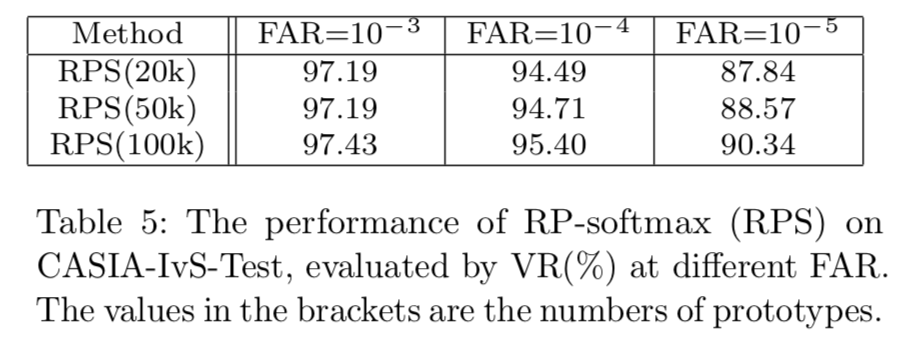
在随机原型softmax (RP-softmax)中,由于单个原型的内存开销很小,我们可以以批处理大小的小成本增加所涉及的类。我们在表5中分别用20k、50k和100k原型对RP-softmax进行了评估,发现更多的原型通常具有更好的性能。
然而,增加原型的数量并不是没有成本的。更多的原型增加了计算softmax和在gpu中复制原型的开销。在图8中,我们展示了不同原型数下的时间成本和GPU-util百分比。当原型从20k增加到100k时,训练时间增加了78%,GPU-util百分比从82%下降到62%。我们进一步尝试了300k个原型,发现GPU-util的百分比下降到了48%,这意味着大部分时间都花在了等待原型复制上。

4.4.2 Dominant Prototype Softmax
为了同时提高训练效率和性能,我们选择了主导原型而不是随机原型。在DP-softmax中,我们为每个类维护一个主导队列来存储它们的相似类,其中队列大小q是影响性能和训练时间的一个重要参数。表6为不同队列大小下的性能:

图9为相应的训练时间:

我们可以看到,性能随着队列大小的增加而增加,但是当q达到100时(只有3000个原型),性能很快就会饱和。考虑到性能和效率,我们在实现中设置q = 100。与拥有100,000个原型的RP-softmax相比,DP-softmax在训练时间更短的情况下获得了更好的性能(FAR=10−5时,分别为91.92% vs. 90.30% ;每次迭代花费时间分别为1.1s vs. 1.6s)
在表7中,我们还比较了有队列更新和没有队列更新时的性能,这说明了队列更新的有效性。
4.4.3 Softmax Formulation
大规模分类主要涉及一种原型选择策略,该策略可以与任何一种softmax公式相结合。除了传统的softmax[16],最先进的A-softmax[22]和AM-softmax[24]也可以采用。表8显示了不同softmax公式的结果:

我们可以看到A-softmax和AM-softmax通过引入边距提高了性能,A-softmax的效果最好。
4.5 Identity Volume
人们已经多次观察到,更多的数据总是能够提供更好的性能[8,67]。在IvS人脸识别中,数据的blessing还存在吗?为了研究这个问题,我们分别从CASIA-IvS-Train数据中随机抽取了100k、500k和2M个身份的子集,然后训练模型。如图10所示:

随着身份的增加,性能呈对数增长,这与[67]一致。我们相信更多的身份提供了更多关于类内和类间差异的信息,从而提供了更多的区别性特征。此外,该模型还可以进一步改进,获得更多的IvS数据。
4.6 Comparison Experiments
为了将我们的方法与现有的方法进行比较,我们选择了几种在大尺度双样本数据上可行的方法,包括contrastive[7]、triplet[8]、Lifted Struct[25]、N-pairs[26]和Megaface challenge [13] (MF-A to MF-D)中的模型A-D。我们还评估了语言模型中的大规模分类方法,包括Noise Contrastive Estimation (NCE) [47]和 Hierarchical Softmax (H-softmax)[50]。为了公平的比较,所有的方法都采用了ResNet64架构,并且它们的模型都在Ms-Celeb-1M上进行了预训练。在我们的实现中,为了进行对比,每个样本都与所有其他样本配对在一个小批中,并且负样本对通过hard negative mining方法进行过滤。对于triplet,我们采用N-pairs batch构造[26]和anchor swapping[64]来构造最多的triplets。此外,还进行了在线hard mining[8]来删除容易判别的triplet。对于N-pairs,我们采用N-pairs-mc loss针对所有相关的负样本对来优化每个正样本对,并使用hard negative mining生成具有相似类的mini-batch。对于Lifted Struct,我们直接使用发布的代码。对于MF-A,我们用softmax在随机选择的100,000个类上训练模型。然后我们在完整的数据上使用triplet loss将MF-A微调成MF-B。对于MF-C,我们采用rotating softmax,在每个epoch中随机选择20,000个类。然后我们采用相同的triplet微调策略来获得MF-D。对于NCE和H-softmax,直接与这两个损失训练不能收敛。在我们的实现中,我们首先通过triplet损失来训练模型,然后通过深度特性来初始化原型,作为我们的LBL,使训练收敛。对于我们的方法,我们首先提供一个简单的基线,用于在IvS数据上执行名为LBL(softmax)的softmax,在CVC的最后阶段,我们仅在100,000个类上训练模型(这是机器能够负担得起的最多的类),并且类不会随着训练的进行而更改。另外,我们使用RP-softmax和DP-softmax报告LBL。
表9显示了在真实的CASIA-IvS-Test和开放的Public-IvS数据集上的性能:

对应的ROC曲线如图11(a)和图11(b)所示:
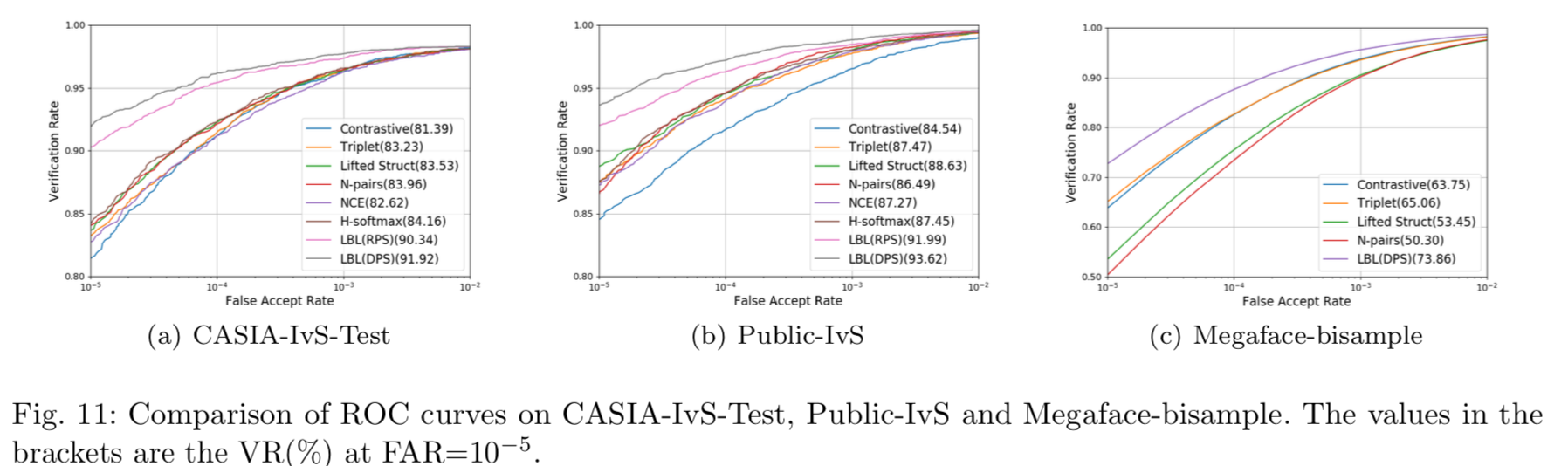
在实现过程中,我们发现MF-A并不能达到令人满意的性能,因为只能使用一小部分数据。由于rotating softmax会周期性地随机初始化原型,因此MF-C很难收敛。在对所有数据进行triplet损失微调后,由于初始化能力差,模型(MF-B和MF-D)仍然不能得到令人满意的性能。对于我们的方法LBL,我们可以看到Public-IvS与CASIA-IvS-Test的结果是一致的,而CASIA-IvS-Test是我们的方法表现最好的地方。此外,LBL在IvS数据上显著优于其他方法,尤其是在low FAR上。FAR=10−5时,CASIA-IvS-Test从84.16%提高至91.92%,Public-IvS从88.63%提高至93.62%。DP-softmax进一步改进了RP-softmax,达到了最佳的性能。在NCE和H-softmax等语言模型中,LBL的识别率也优于大规模分类方法。
4.7 Mimic Experiments on Megaface-bisample
为了使我们的工作可复制,我们在开放的MF2[13]数据集上模拟了大规模的双样本挑战,并提出了一个新的协议megafase -bisample。MF2包含657559个身份,比其他数据集多得多。我们将MF2分成两个子集,MF2-thick和MF2-mini。MF2-thick包含了超过15个样本的身份,用于模拟良好的预学习数据集。MF2-mini为每个身份随机选取了两个样本,用于模拟双样本数据。对于测试,我们遵循LFW[65]上的BLUFR协议[66]。综上所述,MF2-thick、MF2-mini和LFW-BLUFR分别模拟Ms-Celeb-1M、CASIA-IvS-Train和CASIA-IvS-Test。具体来说,MF2-thick有46000个身份,每个身份有34.8个样本,MF2-miniy已经清理了649,790个身份,每个身份2个样本,其图像列表将会发布。众所周知,MF2很少有名人,我们已经尽了最大的努力来确保MF2和LFW之间没有身份重叠。尽管Megaface-bisample不是IvS数据,但它也面临着同样的挑战:与IvS数据一样,它也存在弱的内部变化和模型训练可扩展性。由于在MF2中没有ID照片,我们用avg-prototype初始化分类层,用avg-prototype而不是ID特性来构造NCK。
首先,为了验证仿真的有效性,我们重新实现了表2中关于CVC训练策略的实验。如图12所示,各阶段均有显著改善:
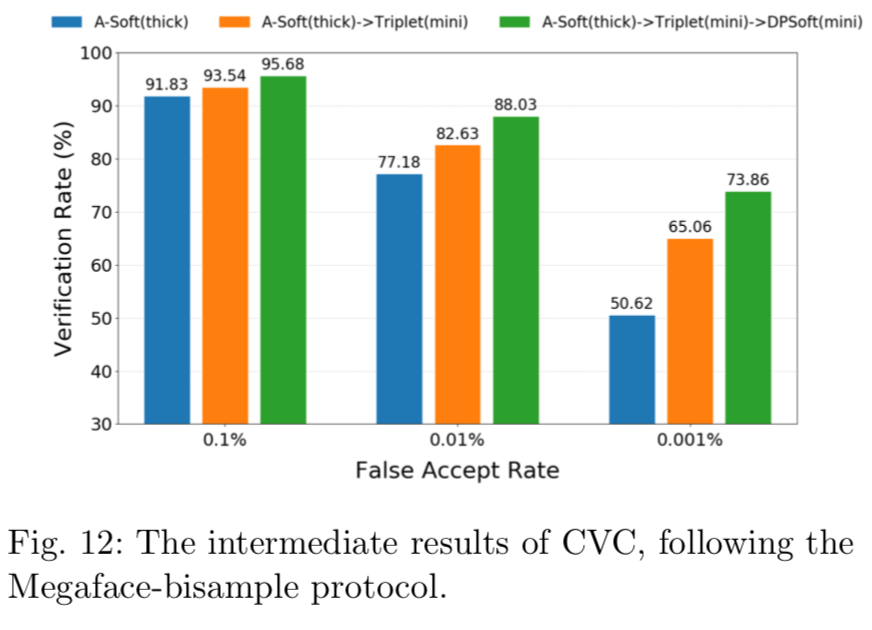
此外,我们尝试在MF2-mini上从零开始训练模型,发现训练很快陷入了糟糕的局部最优。由于结果与CASIA-IvS上的结果一致,我们认为Megaface-bisample可以很好地模拟我们的任务。
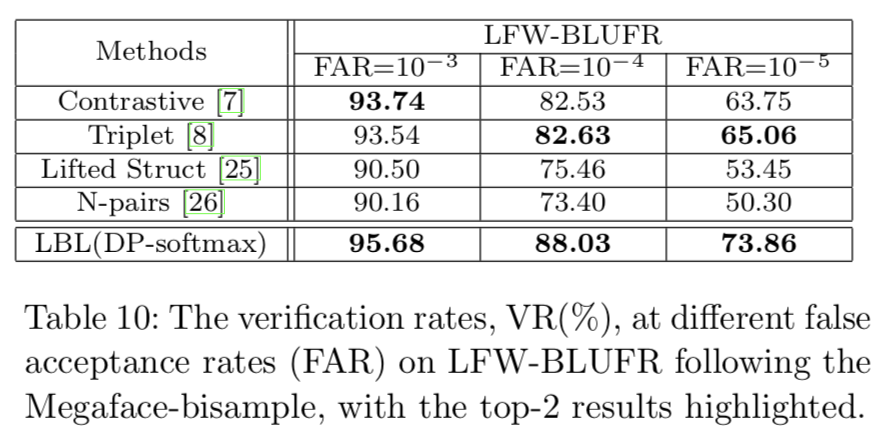
在Megaface-bisample上,我们还将我们的方法与表10中的最先进的方法进行了比较,其ROC曲线如图11(c)所示。提出的LBL仍然优于其他方法,在FAR= 10−5处的改进超过8%。
5 Conclusion
提出了一种大规模双样本学习(LBL)方法来在ID versus Spot (IvS)人脸数据上训练深度神经网络。具体地,我们开发了一个分类-验证-分类(CVC) 双样本训练策略,该策略首先将知识从自然环境场景转移到IvS场景,然后通过大规模分类来提高性能。我们还提出了一个主导原型softmax(DP-softmax)来执行200万个分类,并将其用于CVC的最后阶段。DP-softmax孜孜不倦地为每个mini-batch选择主导原型,从而提高了性能并同时降低了训练成本。在大型真实数据集上的实验表明,该算法显著提高了IvS的人脸识别能力,且DP-softmax算法仅用0.15%的类进行有效的分类。此外,我们还发布了一个用于IvS评估的Public-IvS数据集和一个新的协议megafase -bisample来模拟大规模的双样本学习任务。