STL HashTable实现剖析
常用容器
- unordered_map
- unordered_multimap
- unordered_set
- unordered_multiset
接口层
// gnu 实现
template<typename _Key, typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = equal_to<_Key>,
typename _Alloc = allocator<std::pair<const _Key, _Tp>>>
class unordered_map
{
typedef __umap_hashtable<_Key, _Tp, _Hash, _Pred, _Alloc> _Hashtable;
_Hashtable _M_h; // 内部的唯一成员变量: hashtable
};
/// Base types for unordered_map.
template<bool _Cache>
using __umap_traits = __detail::_Hashtable_traits<_Cache, false, true>;
template<typename _Key,
typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = std::equal_to<_Key>,
typename _Alloc = std::allocator<std::pair<const _Key, _Tp> >,
typename _Tr = __umap_traits<__cache_default<_Key, _Hash>::value>>
using __umap_hashtable = _Hashtable<_Key, std::pair<const _Key, _Tp>,
_Alloc, __detail::_Select1st,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
template<typename _Key, typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = equal_to<_Key>,
typename _Alloc = allocator<std::pair<const _Key, _Tp>>>
class unordered_multimap
{
typedef __ummap_hashtable<_Key, _Tp, _Hash, _Pred, _Alloc> _Hashtable;
_Hashtable _M_h;
};
/// Base types for unordered_multimap.
template<bool _Cache>
using __ummap_traits = __detail::_Hashtable_traits<_Cache, false, false>;
template<typename _Key,
typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = std::equal_to<_Key>,
typename _Alloc = std::allocator<std::pair<const _Key, _Tp> >,
typename _Tr = __ummap_traits<__cache_default<_Key, _Hash>::value>>
using __ummap_hashtable = _Hashtable<_Key, std::pair<const _Key, _Tp>,
_Alloc, __detail::_Select1st,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
/// Base types for unordered_set.
template <bool _Cache>
using __uset_traits = __detail::_Hashtable_traits<_Cache, true, true>;
template <typename _Value,
typename _Hash = hash<_Value>,
typename _Pred = std::equal_to<_Value>,
typename _Alloc = std::allocator<_Value>,
typename _Tr = __uset_traits<__cache_default<_Value, _Hash>::value>>
using __uset_hashtable = _Hashtable<_Value, _Value, _Alloc,
__detail::_Identity, _Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
/// Base types for unordered_multiset.
template <bool _Cache>
using __umset_traits = __detail::_Hashtable_traits<_Cache, true, false>;
template <typename _Value,
typename _Hash = hash<_Value>,
typename _Pred = std::equal_to<_Value>,
typename _Alloc = std::allocator<_Value>,
typename _Tr = __umset_traits<__cache_default<_Value, _Hash>::value>>
using __umset_hashtable = _Hashtable<_Value, _Value, _Alloc,
__detail::_Identity,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
对应到_Hashtable类:
template <typename _Key, typename _Value, typename _Alloc,
typename _ExtractKey, typename _Equal,
typename _Hash, typename _RangeHash, typename _Unused,
typename _RehashPolicy, typename _Traits>
class _Hashtable
: public __detail::_Hashtable_base<_Key, _Value, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused, _Traits>,
public __detail::_Map_base<_Key, _Value, _Alloc, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused,
_RehashPolicy, _Traits>,
public __detail::_Insert<_Key, _Value, _Alloc, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused,
_RehashPolicy, _Traits>,
public __detail::_Rehash_base<_Key, _Value, _Alloc, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused,
_RehashPolicy, _Traits>,
public __detail::_Equality<_Key, _Value, _Alloc, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused,
_RehashPolicy, _Traits>,
private __detail::_Hashtable_alloc<
__alloc_rebind<_Alloc,
__detail::_Hash_node<_Value,
_Traits::__hash_cached::value>>>,
private _Hashtable_enable_default_ctor<_Equal, _Hash, _Alloc>
{
using __traits_type = _Traits;
using __hash_cached = typename __traits_type::__hash_cached;
using __constant_iterators = typename __traits_type::__constant_iterators;
// hash表中节点类型
using __node_type = __detail::_Hash_node<_Value, __hash_cached::value>;
using __node_alloc_type = __alloc_rebind<_Alloc, __node_type>;
using __hashtable_alloc = __detail::_Hashtable_alloc<__node_alloc_type>;
// hash表中节值类型
using __node_value_type =
__detail::_Hash_node_value<_Value, __hash_cached::value>;
using __node_ptr = typename __hashtable_alloc::__node_ptr;
using __value_alloc_traits =
typename __hashtable_alloc::__value_alloc_traits;
using __node_alloc_traits =
typename __hashtable_alloc::__node_alloc_traits;
// __node_base的定义
using __node_base = typename __hashtable_alloc::__node_base;
using __node_base_ptr = typename __hashtable_alloc::__node_base_ptr;
// __bucket_type的定义如下,实际上就是指向__node_base的指针
using __buckets_ptr = typename __hashtable_alloc::__buckets_ptr;
using __insert_base = __detail::_Insert<_Key, _Value, _Alloc, _ExtractKey,
_Equal, _Hash,
_RangeHash, _Unused,
_RehashPolicy, _Traits>;
using __enable_default_ctor = _Hashtable_enable_default_ctor<_Equal, _Hash, _Alloc>;
private:
// buckets的定义,是一个二级指针,可以理解为类型为__node_base*的数组
__buckets_ptr _M_buckets = &_M_single_bucket;
size_type _M_bucket_count = 1; // bucket 节点个数
__node_base _M_before_begin;
size_type _M_element_count = 0; //hashtable中list节点个数
_RehashPolicy _M_rehash_policy; // rehash策略
__node_base_ptr _M_single_bucket = nullptr; // 只需要一个桶用
}
__detail::_Hash_node 和 __detail::_Hashtable_alloc实际上才是核心数据结构。这两个类也是息息相关的:
/**
* Primary template struct _Hash_node.
*/
// _Hash_node为value+next
template <typename _Value, bool _Cache_hash_code>
struct _Hash_node
: _Hash_node_base,
_Hash_node_value<_Value, _Cache_hash_code>
{
_Hash_node *
_M_next() const noexcept
{
return static_cast<_Hash_node *>(this->_M_nxt);
}
};
// _Hash_node_base仅持有指向下一个节点的指针
struct _Hash_node_base
{
_Hash_node_base *_M_nxt;
_Hash_node_base() noexcept : _M_nxt() {}
_Hash_node_base(_Hash_node_base *__next) noexcept : _M_nxt(__next) {}
};
template <typename _Value, bool _Cache_hash_code>
struct _Hash_node_value
: _Hash_node_value_base<_Value>,
_Hash_node_code_cache<_Cache_hash_code>
{
};
/**
* struct _Hash_node_value_base
*
* Node type with the value to store.
*/
// _Hash_node_value_base持有value
template <typename _Value>
struct _Hash_node_value_base
{
typedef _Value value_type;
__gnu_cxx::__aligned_buffer<_Value> _M_storage;
_Value *
_M_valptr() noexcept
{
return _M_storage._M_ptr();
}
const _Value *
_M_valptr() const noexcept
{
return _M_storage._M_ptr();
}
_Value &
_M_v() noexcept
{
return *_M_valptr();
}
const _Value &
_M_v() const noexcept
{
return *_M_valptr();
}
};
综上,同经典的vector+链表的buckets相比,STL中_Hashtable类的buckets的实现为一个元素类型为的_Hash_node_base*数组。
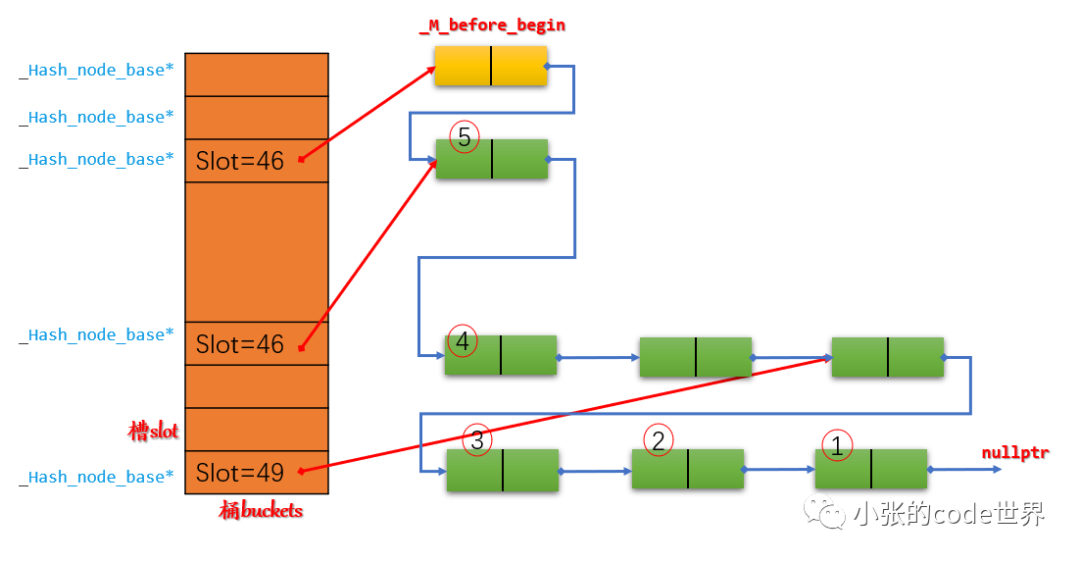
STL中也是采用开链法解决hash冲突,但是并不是一个slot一个链表,而是整个hash表是一个链表,“前一个”slot的尾节点指向“下一个”非空slot的头节点,slot中存储的是头节点的prev节点的地址。着重强调链表并不是按照slot数组数组即桶的前后顺序串联起来的,而是根据节点的插入时间串联起来的。
template <typename _NodeAlloc>
struct _Hashtable_alloc : private _Hashtable_ebo_helper<0, _NodeAlloc>
{
using __node_ptr = __node_type *;
using __node_base = _Hash_node_base;
using __node_base_ptr = __node_base *;
using __buckets_alloc_type =
__alloc_rebind<__node_alloc_type, __node_base_ptr>;
using __buckets_alloc_traits = std::allocator_traits<__buckets_alloc_type>;
using __buckets_ptr = __node_base_ptr *;
};
// Insert a node at the beginning of a bucket.
// 插入函数的底层均调用_M_insert_bucket_begin
// __bkt为slot的索引,__node为需要插入的节点,使用key与value构造出来
void
_M_insert_bucket_begin(size_type __bkt, __node_ptr __node)
{
// 如果所要插入的slot已经有节点,直接插入头部
if (_M_buckets[__bkt])
{
// Bucket is not empty, we just need to insert the new node
// after the bucket before begin.
__node->_M_nxt = _M_buckets[__bkt]->_M_nxt;
_M_buckets[__bkt]->_M_nxt = __node;
}
// 如果所要插入的slot还没插入过节点
else
{
// The bucket is empty, the new node is inserted at the
// beginning of the singly-linked list and the bucket will
// contain _M_before_begin pointer.
__node->_M_nxt = _M_before_begin._M_nxt;
_M_before_begin._M_nxt = __node;
if (__node->_M_nxt)
// We must update former begin bucket that is pointing to
// _M_before_begin.
_M_buckets[_M_bucket_index(*__node->_M_next())] = __node;
_M_buckets[__bkt] = &_M_before_begin;
}
}
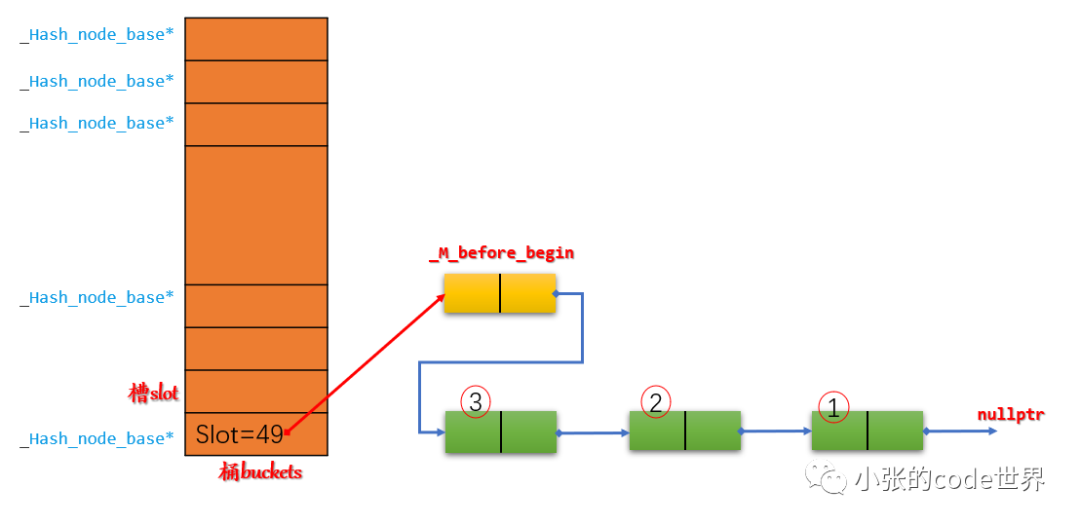
第一步:先在slot49中依次插入三个元素,由于是在头部插入,因此示意图如下:
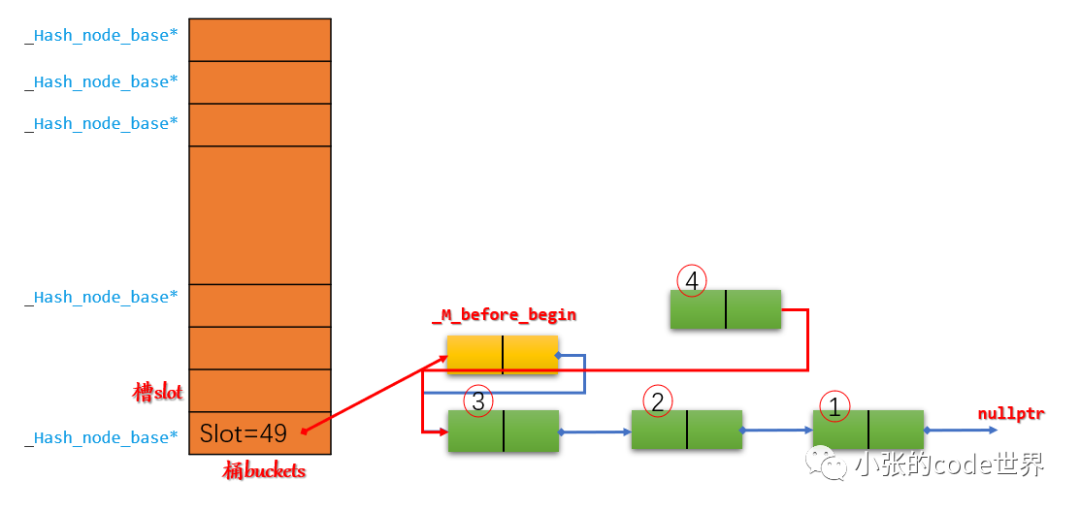
第二步:在slot46中插入一个元素4,示意图如下:
2.1 将新节点4指向_M_before_begin的next;
2.2 再将_M_before_begin的next指向新节点4:
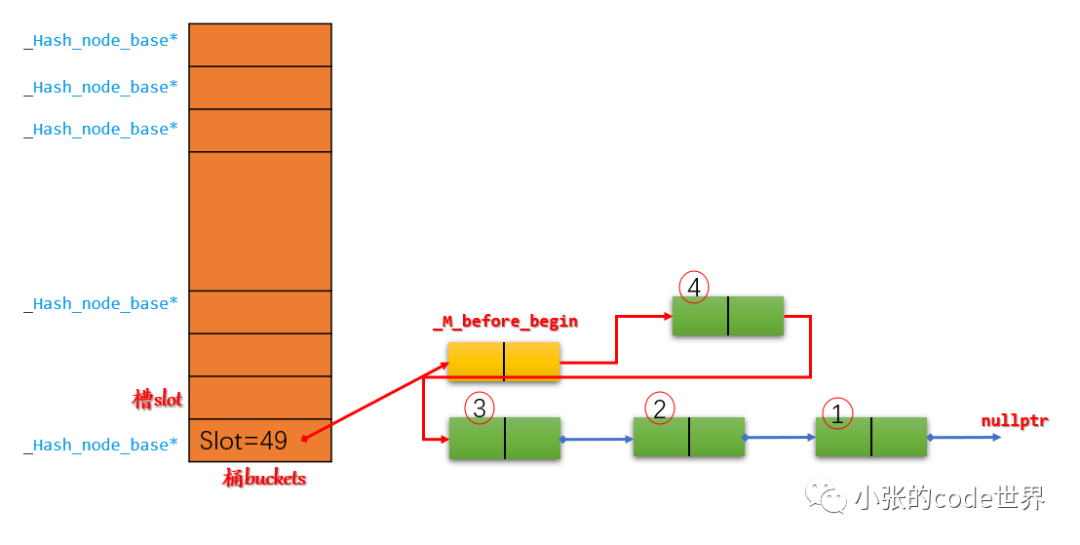
2.3 根据_M_buckets[_M_bucket_index(__node->_M_next())] = __node;,将Slot49修改为新节点4的地址:
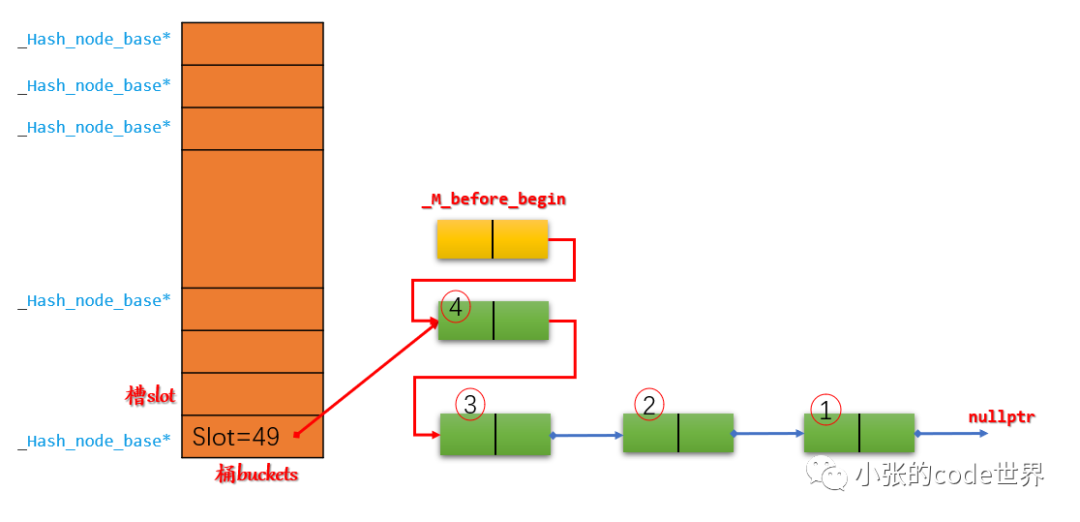
2.4 将Slot46指向_M_before_begin
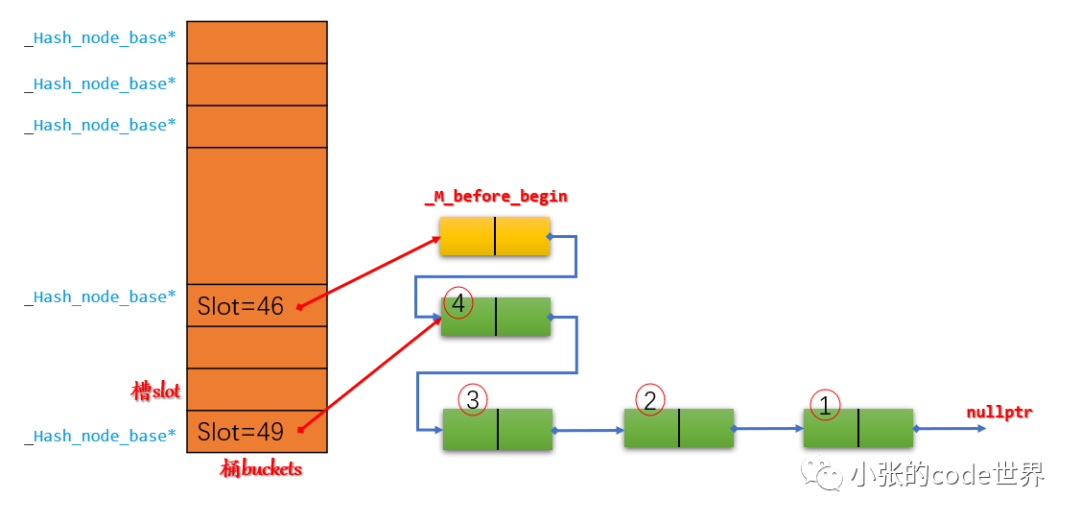
第三步:在slot3中插入一个元素5,示意图如下:
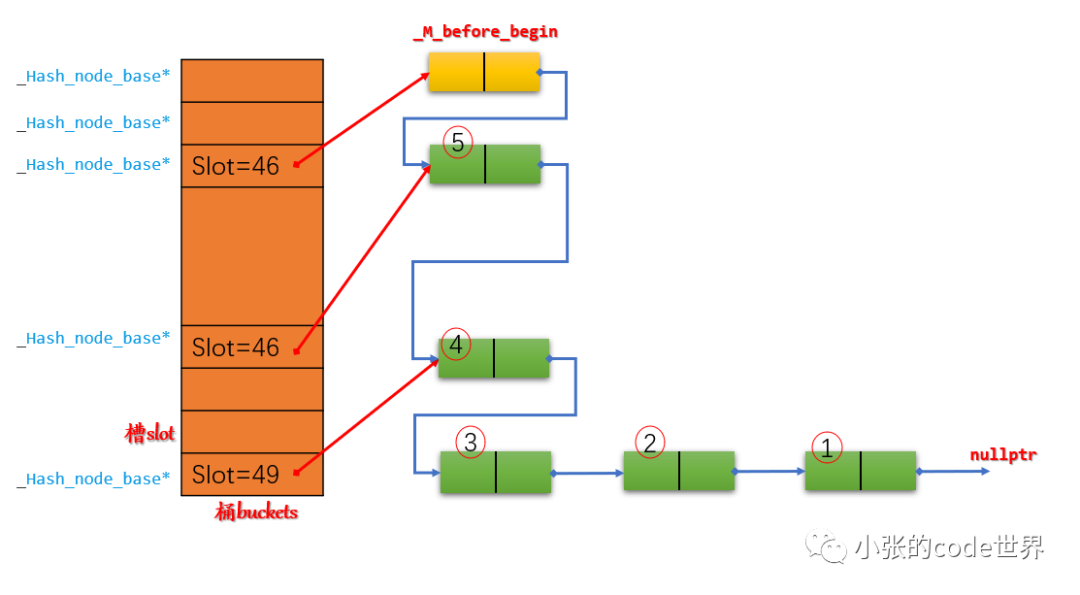
最后依次再插入更多的元素:
| 容器类 | _Key | _Value | _Alloc | _ExtractKey | _Equal | _Hash | _RangeHash | _Unused | _RehashPolicy | _Traits |
|---|---|---|---|---|---|---|---|---|---|---|
| unordered_map | _Key | std::pair<const _Key, _Tp> | std::allocator<std::pair<const _Key, _Tp>> | __detail::_Select1st | std::equal_to<_Key> | hash<_Key> | __detail::_Mod_range_hashing | __detail::_Default_ranged_hash | __detail::_Prime_rehash_policy | __uset_traits |
| unordered_multimap | _Key | std::pair<const _Key, _Tp> | std::allocator<std::pair<const _Key, _Tp>> | __detail::_Select1st | std::equal_to<_Key> | hash<_Key> | __detail::_Mod_range_hashing | __detail::_Default_ranged_hash | __detail::_Prime_rehash_policy | __uset_traits |
| unordered_set | _Value | _Value | std::allocator<_Value> | __detail::_Identity | std::equal_to<_Value> | hash<_Value> | __detail::_Mod_range_hashing | __detail::_Default_ranged_hash | __detail::_Prime_rehash_policy | __uset_traits |
| unordered_multiset | _Value | _Value | std::allocator<_Value> | __detail::_Identity | std::equal_to<_Value> | hash<_Value> | __detail::_Mod_range_hashing | __detail::_Default_ranged_hash | __detail::_Prime_rehash_policy | __uset_traits |
上表中列出的模板参数包括:
- _Key:节点的键值型别。
- _Value:节点的实值型别。
- _Alloc:用于内存分配的分配器类型。
- _ExtractKey:从节点中取出键值的方法。
- _Equal:判断键值相同与否的方法。
- _Hash:第一个哈希函数对象类型。
- _RangeHash:第二个哈希函数对象类型。
- _Unused:哈希函数对象类型。
- _RehashPolicy:rehash策略类。
- _Traits:“萃取”类
可以看出,_Hash = hash<_Key>,_RangeHash就是__detail::_Mod_range_hashing,_Unused就是__detail::_Default_ranged_hash。typename _H1, typename _H2, typename _Hash之间的关系如下:_Unused(k, N) = _RangeHash(_Hash(k), N)。
_Hashtable_base
其中注释中如下:
★ Helper class adding management of _Equal functor to _Hash_code_base type.
帮助程序类,将仿函数_Equal的管理添加到_Hash_code_base中。
/**
* Primary class template _Hashtable_base.
*
* Helper class adding management of _Equal functor to
* _Hash_code_base type.
*
* Base class templates are:
* - __detail::_Hash_code_base
* - __detail::_Hashtable_ebo_helper
*/
template <typename _Key, typename _Value, typename _ExtractKey,
typename _Equal, typename _Hash, typename _RangeHash,
typename _Unused, typename _Traits>
struct _Hashtable_base
: public _Hash_code_base<_Key, _Value, _ExtractKey, _Hash, _RangeHash,
_Unused, _Traits::__hash_cached::value>,
private _Hashtable_ebo_helper<0, _Equal>
{
}
对比一下_Hash_code_base与_Hashtable_base,两者就差一个_Equal,据此这句话解释完毕。
它的基类又有两个分别是:
__detail::_Hash_code_base
__detail::_Hashtable_ebo_helper
_Hash_code_base
这个类最后一个__cache_hash_code表示是否缓存hash code。
O(1)
数组,可以通过索引index在O(1)的时间复杂度内获取元素,但如果不知道index则要O(N)的时间复杂度来查找该节点。hashtable为了弥补这一缺点,采用一个hash函数来计算元素的索引值,来满足O(1)的搜索时间复杂度。其过程如下。
- 计算元素的哈希值。对于单个键值对{key, value},计算key对应的哈希值 hashcode = hash_func(key) 。
- 计算元素在数组中的索引值。由于hashcode不一定处于[0, bucket_count]范围内,因此需要将hashcode映射到该范围:index = hashcode % bucket_count。
但若同时存在几个节点的hashcode值一样,那么后面插入的节点岂不是会覆盖前面的值?这个问题即 hash冲突。
hash冲突
在hashtable中,数组的每一个元素叫做桶(bucket)。
为了解决hash冲突,hashtable在每个桶里bucket[index]不再直接存储待插入节点的值,而是存储一个哨兵节点,使其指向一个链表,由这个链表来存储每次插入节点的值:
- 桶的索引值index依然是bucket_index函数的计算方式,即通过待插入节点的键来获取
- 待插入节点的值在哨兵指向的链表头部插入,由于是头部插入整个插入过程还是O(1)时间复杂度。
当发生hash冲突时,将所有hashcode相同的节点都插入到同一个链表中。由于采用的是头部插入法,那么即便是发生了hash冲突,此时插入时间复杂度也依然是O(1)。
hash退化
负载因子
为了解决hash退化,引入了两个概念:
负载因子(load_factor),是hashtable的元素个数与hashtable的桶数之间比值;
最大负载因子(max_load_factor),是负载因子的上限
他们之间要满足:
load_factor = map.size() / map.buck_count() // load_factor 计算方式
load_factor <= max_load_factor // 限制条件
当hashtable中的元素个数与桶数比值load_factor >= max_load_factor时,hashtable就自动发生Rehash行为,来降低load_factor:
- 扩容即使分配一块更大内存,来容纳更多的桶。
- 重新插入。按照上述插入步骤将原来桶中的buck_size个节点重新插入到新的桶中。
Rehash后,桶数增加了而元素个数不变,再次满足load_factor < max_load_factor条件。
Rehash
hashtable,由于要一直满足 load_factor <= max_load_factor ,限制着hash冲突程度,即每个桶的链表节点数不会无限制增加,整个hashtable的节点数达到一定程度就会Rehash,确保hashtable的搜索、删除的平均时间复杂度还是O(1)。
在std::unordered_map有个rehash函数,可以在任意时候使std::unordered_map发生Rehash,也可以等load_factor >= max_load_factor时自动发生。注意:
- 不同编译器的扩容策略不同,因此编译器Rehash后桶的个数不一致很正常。
- 目前msvc和g++中的max_load_factor字段默认值都是1。