hashtable
二叉搜索树具有对数平均时间的表现,但这种的表现构造在一个假设上:输入数据有足够的随机性。这一节介绍一种名为hastable(散列表)的数据结构,这种结构在插入、删除、搜寻等操作上也具有“常数平均时间”的表现,而这种表现是以统计为基础的,不需仰赖输入元素的随机性。
hashtable概述
hashtable通过hash function将元素映射到不同的位置,但当不同的元素通过hash function映射到相同的位置时,便产生了“碰撞”问题。解决碰撞问题的方法主要有线性探测、二次探测、开链法等。
线性试探
负载系数:意指元素个数除以表格大小。负载系数永远在0~1之间,除非采用开链策略。
当hash function计算处某个元素的插入位置,而该位置上的空间不再可用时,最简单的办法就是循序往下一一寻找(如果到达尾端,就绕过头部继续寻找),直到找到一个可用的空间为止。只要表格足够大,总是能够找到一个i安身立命的空间,需要花费的时间就很难说了。进行元素搜索操作时,道理也相同,如果hash function计算出来的位置上的元素与我们搜寻目标不符,就循序往下一一寻找,直到找到吻合者,或直到遇上空格元素。至于元素的删除,必须采用惰性删除,也就是只标记删除记号,实际删除操作则待表格中心整理时再进行——这是因为hash table中的每一个元素不仅表述自己,也关系到其它元素的排列。

欲分析线性探测的表现,需要两个假设:(1)表格足够大;(2)每个元素都独立。在此假设下,最坏的情况是线性巡防整个表格,平均情况则是寻访一半表格,和常数实际时间差已经很大了。会造成主集团(primary clustering)问题。
二次试探
二次试探发主要用来解决primary clusterign问题。其命名由来是因为解决碰撞问题的方程式F(i)=i^2是个二次方程式。明确地说,如果hash function计算出来新元素的位置为H,而该位置实际上已被使用,那么就依序尝试H+1^2,H+2^2,H+3^2,……,H+i^2,而不是像线性探测那样依序尝试H+1,H+2,H+3,……,H+i。

二次试探可以消除主集团(primary clustering),却可能造成次集团(secondary clustering)。
开链
另外一种与二次探测法分庭抗礼的,是所谓的开链法。这种做法是在每一个表格中维护一个list;hash function为我们分配某一个list,然后我们在那个list身上执行元素的插入、搜寻、删除等操作。虽然针对list而进行的搜索只是一种线性操作,但如果list够短,速度还是够快。
使用开链法表格的负载系数将大于1。SGI STL的hash table便是采用这种做法。
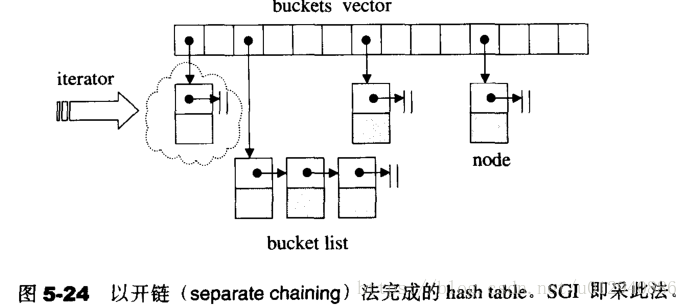
hashtable的桶子(buckets)与节点(nodes)
SGI STL称hash table表格内的元素为桶子(bucket),此名大约的意思是,表格的每个单元,覆盖的不只是节点(元素),甚至可能是一个“桶”节点。
下面是hash table的节点定义:
template<class Value> struct _hashtable_node { _hashtable_node* next; Value val; };
bucket所维护的linked list并不采用STL的list或slist,而是自身维护上述的hash table node。
hashtable的迭代器
hastable迭代器必须永远维系着整个“buckets vector”的关系,并记录目前所指的节点。其前进操作是首先尝试从目前所指的节点出发,前进一个位置(节点),由于节点被安置于list内,所以利用节点的next指针可轻易达成前进操作。如果目前节点正巧是list的尾端,就跳至下一个bucket身上,那正是指向下一个list头部节点。
注意,hashtable的迭代器没有后退操作(operator--()),hastable也没有定为逆向迭代器。
hashtable的数据结构
template <class Value, class Key, class HashFcn, class ExtractKey, class EqualKey, class Alloc>
value:节点的实值类别 key:节点的键值类别 HashFcn:hash function函数类别 ExtractKey:从节点中取出键值的方法 EqualKey:判断键值相同与否的方法 Alloc:空间配置器,默认使用std::alloc
hashtable的构造与内存管理
节点配置函数与节点释放函数
node* new_node(const value_type& obj) { node* n = node_allocator::allocate(); n->next = 0; __STL_TRY { construct(&n->val, obj); return n; } __STL_UNWIND(node_allocator::deallocate(n)); } void delete_node(node* n) { destroy(&n->val); node_allocator::deallocate(n); }
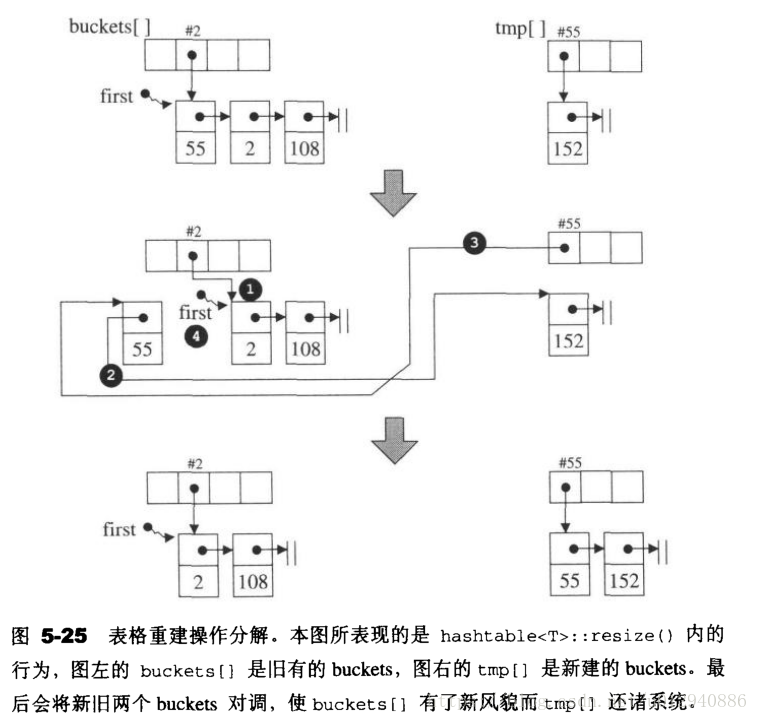
插入操作(insert)与表格重整(resize)
表格重整:
resize() { 表格是否需要重建判断原则:拿元素个数和bucket vector的大小来比,如果前者比后者大就重建表格。因此,每个bucket(list)的最大容量和bucket vector的大小相同。 如果要重建,找出下一个质数作为vector的大小,建立新的buckets 处理每一个旧的bucket{ 建立一个新节点指向节点所指的串行的起始节点 处理每一个旧bucket所含串行的每一个节点{ 找出节点落在哪一个新的bucket内 令旧bucket指向其所指的串行的下一个节点 将当前节点插入到新的bucket内,成为其串行的第一个节点 回到旧bucket所指的待处理串行,准备处理下一个节点 } } 新旧两个buckets对调,如果双方大小不同,大的会变小,小的会变大 离开时释放temp的内存 }
hash functions
<stl_hash_fun.h>定义有数个现成的hash functions,全都是仿函数。hash function是计算元素位置的函数,SGI将这项任务赋予bkt_num(),再由它来调用这里提供的hash function,取得一个可以对hashtable进行模运算的值。针对char,int,long等整数型别,这里大部分hash function什么也不做,只是返回原值。但对于字符字符串(const char*),就设计了一个转换函数如下:
inline size_t __stl_hash_string(const char* s) { unsigned long h = 0; for ( ; *s; ++s) h = 5*h + *s; return size_t(h); }