小编的毕业设计做的就是车牌识别系统,主要包含车牌定位、字符分割、车牌识别模块。先附上做的系统界面图。
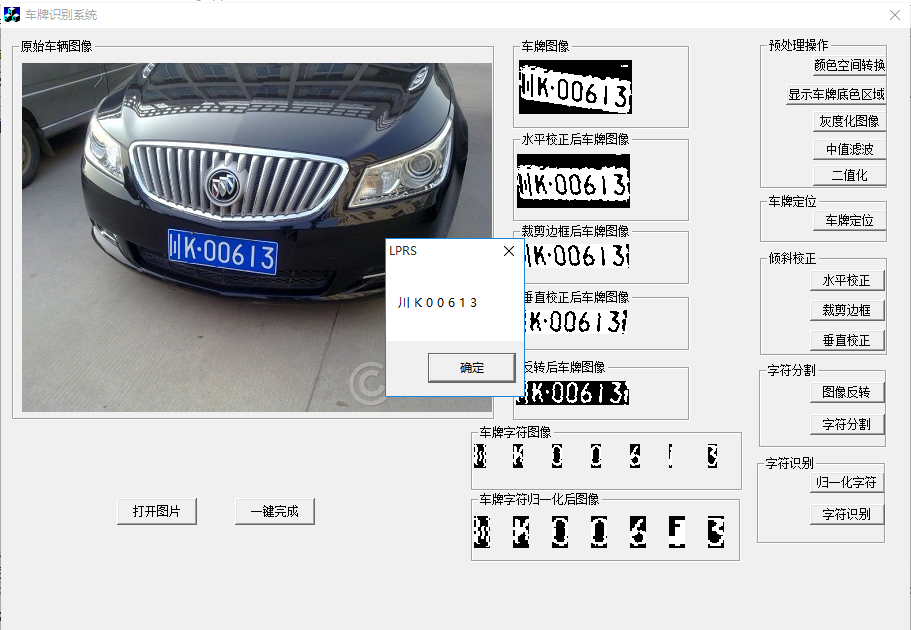
关于实现车牌定位和字符分割的算法,大家可以去网上找相关的论文,本文的重点是介绍利用机器学习的KNN算法实现简单的字符识别。
KNN算法全称k-NearestNeighbor,是机器学习分类领域最简单的算法之一。它的主要思想是将待预测的样本和已知分类的样本集中每一个样本进行“距离计算”,选择前K个“距离”最短的样本,在这K个样本中,分类次数出现最多的那个分类就被视为待预测样本的所属分类。
“距离计算”因样本而不同,车牌字符识别中的样本当然是字符图像。每一张字符图像都是长宽相同的二值图像,本文是16*32的二值图像。这样每一张字符图像都和16*32的二维数组一一对应,并且数组的取值只能为0或1。为了方便比较,我们将16*32的二维数组排成长度为512的一维数组,则“距离计算”的公式如下。
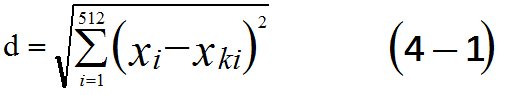
其中xi为待识别字符图像对应的一维数组的第i个值,xki为字符样本集第k个样本对应的一维数组的第i个值。
本文的字符集包含了省份简称、英文字母、数字,一共有3500张图像。其中英文字符“A”的所有图像如下。
KNN算法有一个很明显的缺点就是要想预测样本的分类,就要把样本和已知分类的样本集中的所有样本进行比较,这样算法的时间复杂度就比较高。还有算法的实际效果很大程度上也取决于已知分类的样本集质量。本文系统的字符识别的正确率只有80%左右,并且每次都要等待大约6、7秒才出结果。
车牌字符识别算法目前已经很成熟了,大家如果有兴趣,可以在网上找一找大牛做的,小编只是抛砖引玉。
