第六课、训练神经网络
1.梯度下降算法:Mini-bash SGD

2.训练神经网络时需要考虑的内容:

3.常用的非线性激活函数
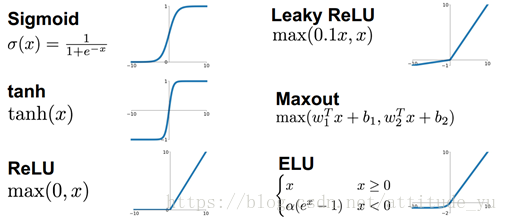
4.Sigmoid激活函数
缺点:
a.当神经元输出进入饱和区时,反向传播过程的梯度趋近于0,在链式法则的作用下,将会使得权重无法更新
b.神经元的输出在非0中心
c.exp()指数运算增加了计算复杂度
5.ReLU激活函数
优点:
a.神经元输出为正时,没有饱和区
b.计算复杂度低,效率高
c.在实际应用中,比sigmoid、tanh更新更快
d.相比于sigmoid更加符合生物特性
缺点:
a.神经元输出为负时,进入了饱和区
b.神经元的输出在非0中心
c.使得数据存在Active ReLU、Dead ReLU(当wx+b<0时,将永远无法进行权值更新,此时的神经元将死掉)的问题
解决ReLU对应问题的非线性激活函数:Leaky ReLU,ELU
6.数据预处理:
零中心化、归一化、PCA、白化
7.权重初始化,使用Xvaier初始化的原因
小的权重参数适用于浅层网络,而不适用于深层网络。因为,假设使用tanh激活函数,神经元输出会因为小的权重参数而迅速减小,在传递过程中,每层的输入近似于0,同时输出也就近似于0。可推导,大的权重参数也是不适用于深层网络,神经元输出会进入饱和区,在反向传播过程中各层的梯度将会接近0。所以,使用Xvaier初始化。


8.批量归一化
利用均值、方差对批量数的每一个维度进行归一化(单位高斯化)。将数据转化为单位高斯数据,当使用tanh的激活函数时,进行单位高斯归一化更具有灵活性,其可控制神经元输出的饱和程度。当然,在神经网络中,这并不一定是一个好的选择。
经常讲批量归一化层插入到全连接层或卷积层之前。
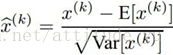
可将其恢复为恒等映射:
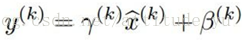
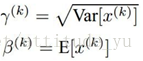
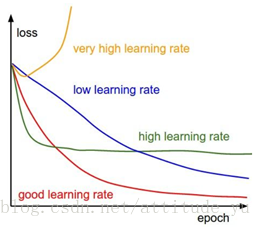
9.超参数的最优化,在交叉验证中寻找参数
a.粗略搜索:先选择几个分散值(理想情况下,此值应该足够宽),再确定参数的优化区间。一般学习速率是最重要的,需要首先确定它,然后再去确定正则化、模型大小等
b.随机搜索
c.网格搜索
d.监测和可视化损失曲线,选择最优的学习速率