- #include
- #include
- using namespace std;
- using namespace cv;
- int main(int argc ,char** args)
- {
- //设置是否启用指令集优化特性
- cv::setUseOptimized(true);
- //获取当前机器的CPU指令集支持特性
- bool opt_status = cv::useOptimized();
- cout<<"当前的指令集优化状态:"<
bool simd = checkHardwareSupport(CV_CPU_SSE);
cout << "当前的指令集优化状态:" << simd << endl;
bool simd1 = checkHardwareSupport(CV_CPU_SSE2);
cout << "当前的指令集优化状态:" << simd1 << endl;
bool simd2 = checkHardwareSupport(CV_CPU_SSE3);
cout << "当前的指令集优化状态:" << simd2 << endl;
bool simd3 = checkHardwareSupport(CV_CPU_SSSE3);
cout << "当前的指令集优化状态:" << simd3 << endl;
bool simd4 = checkHardwareSupport(CV_CPU_MMX);
cout << "当前的指令集优化状态:" << simd4 << endl;
bool simd5 = checkHardwareSupport(CV_CPU_SSE4_1);
cout << "当前的指令集优化状态:" << simd5 << endl;
bool simd6 = checkHardwareSupport(CV_CPU_SSE4_2);
cout << "当前的指令集优化状态:" << simd6 << endl;
bool simd7 = checkHardwareSupport(CV_CPU_AVX);
cout << "当前的指令集优化状态:" << simd7 << endl;
bool simd8 = checkHardwareSupport(CV_CPU_POPCNT);
cout << "当前的指令集优化状态:" << simd8 << endl;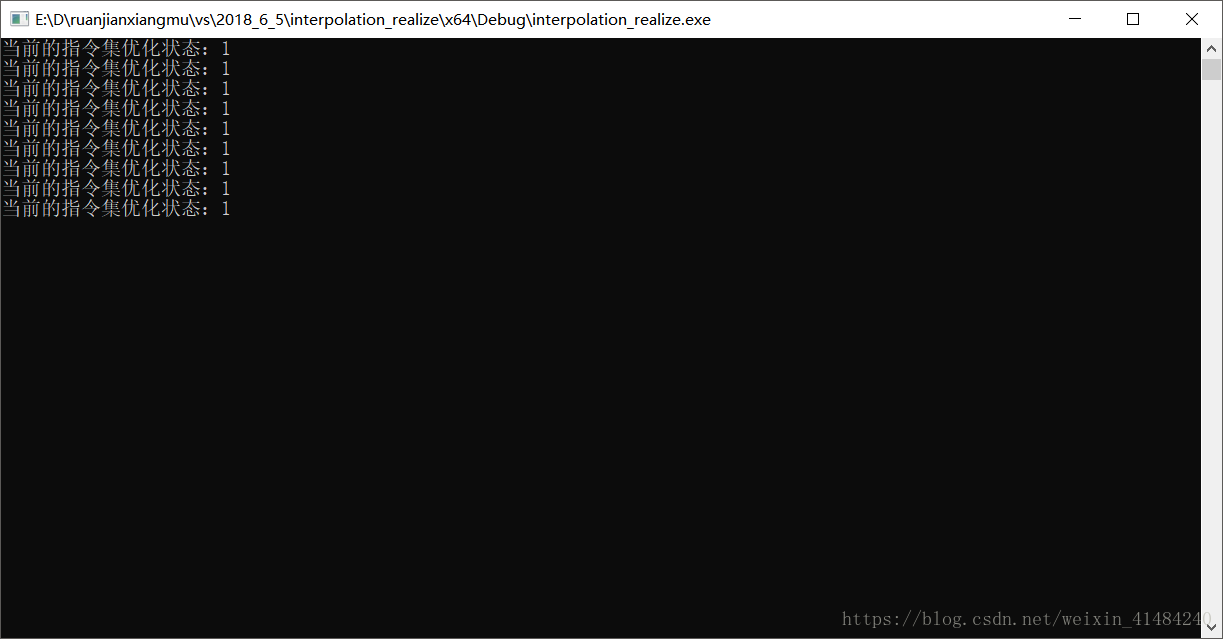
二、
OpenCV的GPU模块只支持NVIDIA的显卡,原因是该部分是基于NVIDIA的CUDA和NVIDIA的NPP模块实现的。而该模块的好处在于使用GPU模块无需安装CUDA工具,也无需学习GPU编程,因为不需要编写GPU相关的代码。但如果你想重新编译OpenCV的GPU模块的话,还是需要CUDA的toolkit。
由于GPU模块的发展,使大部分函数使用起来和之前在CPU下开发非常类似。首先,就是把GPU模块链接到你的工程中,并包含必要的头文件gpu.hpp。其次,就是GPU模块下的数据结构,原本在cv名字空间中的现在都在gpu名字空间中,使用时可以gpu::和cv::来防止混淆。
需要再说明的是,在GPU模块中,矩阵的名字为GpuMat,而不是之前的Mat,其他的函数名字和CPU模块中相同,不同的是,现在的参数输入不再是Mat,而是GpuMat。
还有一个问题就是,对于2.0的GPU模块,多通道的函数支持的并不好,推荐使用GPU模块处理灰度的图像。有些情况下,使用GPU模块的运行速度还不及CPU模块下的性能,所以可以认为,GPU模块相对而言还不够成熟,需要进一步优化。很重要的一个原因就是内存管理部分和数据转换部分对于GPU模块而言消耗了大量的时间。
需要注意的是,在所有使用GPU模块的函数之前,最好需要调用函数gpu::getCudaEnabledDeviceCount,如果你在使用的OpenCV模块编译时不支持GPU,这个函数返回值为0;否则返回值为已安装的CUDA设备的数量。
还有一点就是使用GPU模块,需要在用CMake编译OpenCV时使其中的WITH_CUDA和WITH_TBB的宏生效,为ON。
由于我对GPU部分的熟悉程度还不行,先拿来一段sample自带的一段求矩阵转置的程序来做例子,代码如下:
- #include <iostream>
- #include "cvconfig.h"
- #include "opencv2/core/core.hpp"
- #include "opencv2/gpu/gpu.hpp"
- #include "opencv2/core/internal.hpp" // For TBB wrappers
- using namespace std;
- using namespace cv;
- using namespace cv::gpu;
- struct Worker { void operator()(int device_id) const; };
- int main()
- {
- int num_devices = getCudaEnabledDeviceCount();
- if (num_devices < 2)
- {
- std::cout << "Two or more GPUs are required\n";
- return -1;
- }
- for (int i = 0; i < num_devices; ++i)
- {
- DeviceInfo dev_info(i);
- if (!dev_info.isCompatible())
- {
- std::cout << "GPU module isn't built for GPU #" << i << " ("
- << dev_info.name() << ", CC " << dev_info.majorVersion()
- << dev_info.minorVersion() << "\n";
- return -1;
- }
- }
- // Execute calculation in two threads using two GPUs
- int devices[] = {0, 1};
- parallel_do(devices, devices + 2, Worker());
- return 0;
- }
- void Worker::operator()(int device_id) const
- {
- setDevice(device_id);
- Mat src(1000, 1000, CV_32F);
- Mat dst;
- RNG rng(0);
- rng.fill(src, RNG::UNIFORM, 0, 1);
- // CPU works
- transpose(src, dst);
- // GPU works
- GpuMat d_src(src);
- GpuMat d_dst;
- transpose(d_src, d_dst);
- // Check results
- bool passed = norm(dst - Mat(d_dst), NORM_INF) < 1e-3;
- std::cout << "GPU #" << device_id << " (" << DeviceInfo().name() << "): "
- << (passed ? "passed" : "FAILED") << endl;
- // Deallocate data here, otherwise deallocation will be performed
- // after context is extracted from the stack
- d_src.release();
- d_dst.release();
- }
1、OpenCV提供的开发包中提供的库没有开启gpu和ocl模块功能,虽然有***gpu.lib/***gpu.dll文件,但不能用。如果调用gpu::getCudaEnableDeviceCount()将会return 0;要开启该功能需要重新编译opencv的库。
2、 参考http://docs.opencv.org/modules/gpu/doc/introduction.html和http://blog.csdn.net/quanquanyu/article/details/8917765文章,需要在编译之前安装:CMake用于生成vs工程,Tbb, Qt(gui), cuda tool kit, python 等程序。
3、用CMake生成vs工程时,要打开cuda功能,其他功能可以任选,要让cmake找到你的tbb、qt、cuda和python的位置。
4、有时候要编译静态库,这时需要更改vs工程。对于不同目录下的更改设置不同。对于输出是.EXE的工程,要修改Use of MFC为 use MFC in a Static Library, 在C/C++中的Runtime Library中修改为/Mt(d debug or release),而对于输出是.dll的工程则需要把输出的改为.lib并修改configuration Type为 Static Library(.lib)