CSDN上写的第一篇博客,初学编程,写的疏漏颇多,还请见谅。
最初是自己想找一些大学公开课的资源,随后发现了有一个叫爱课程的网站www.icourses.cn,上面提供了近千门视频公开课,正符合我的需求,便找了本爬虫的书,开始学习爬取视频。
然而,爬取过程并不顺利。
首先,视频网站的视频链接并不像京东淘宝的图片一样存在于当前页面,你需要进入每个老师的课堂到达视频播放页才能提取到链接。
第二,也是困扰我长达一周多的东西,这个网站的url并不会随着页面的变化而变化,这和书上说的完全不一样啊喂(#`O′),同样的,网页源代码也始终和第一页的代码保持一致,完全得不到后面四十多页的任何信息。当时我换了数个浏览器,百度了无数的内容,自行增添网址后缀,都没有任何效果,绝望的我差点就要放弃了。
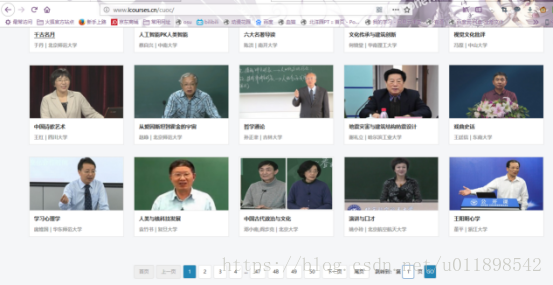
第一页课程
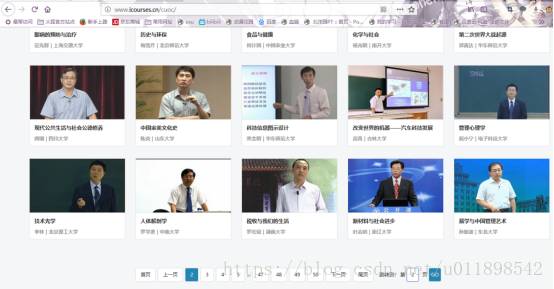
第二页课程
后来,和我一块学习爬虫的同学告诉我,在fiddler中可以看到第二页之后的网页源代码
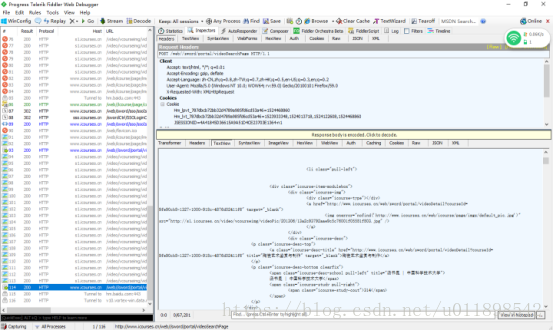
第一页的网页源代码
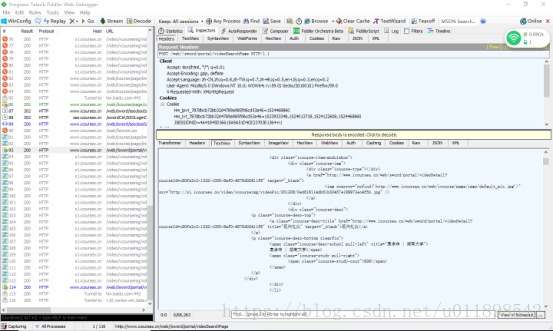
第二页的网页源代码
这让我有了一丝继续下去的希望,至少源代码能看到了,只要把源代码都搞到一个文件里,课堂的链接就都能提取出来了。
但是,很明显,五十页的网页源代码光复制粘贴就觉得很麻烦,这种方法还是显得太笨了。我依旧在思考如何能让代码自动翻页。
在我苦苦追寻答案的几天里,同学已经用上面的笨方法爬取了三十页的视频= =。
偶然的一天我注意到了网页除了有get请求外还有post请求,而post请求是不会有url的变化的,之前书中介绍的post请求都是和模拟登陆有关我都没在意,这一天我打开浏览器按下了f12:

果不其然!网页是向一个videoSearchPage的地方发送了post请求然后再返回来的!继续打开fiddler我查到了发送请求所需的参数
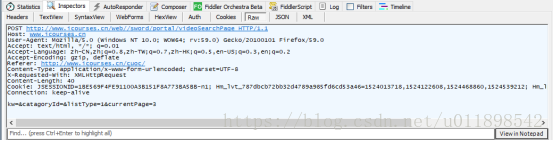
紧接着我按照书中的教程写出了爬取页面的代码:
# -*- coding: utf-8 -*-
"""
Created on Wed Apr 11 15:57:56 2018
@author: 好读秒
"""
import re
import urllib.request
import urllib.parse
a = 31
for a in range(31,35):
url = "http://www.icourses.cn/web//sword/portal/videoSearchPage"
postdata = urllib.parse.urlencode({
'JSESSIONID':"EC283676A72516765DCB5844584D7A23-n1",
'Hm_lvt_787dbcb72bb32d4789a985fd6cd53a46':'1523326195,1523433916',
'Hm_lpvt_787dbcb72bb32d4789a985fd6cd53a46':'1523433987',
'currentPage':f'{a}',
'listType':'1'
}).encode('utf-8')
req = urllib.request.Request(url,postdata)
req.add_header("User-Agent",'Mozilla/5.0(Windows NT 6.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0')
data = urllib.request.urlopen(req).read()
data = str(data)
ptn = re.compile('<li class="pull-left.*?<div.*?</div>.*?href="(.*?)".*?</a>.*?<a.*?href=.*?title=', re.S)
data2 = re.findall(ptn, data)
fhandle = open("d:/1/7.txt",'a')
fhandle.write(str(data2))
fhandle.close()
不知为何如果一次性爬多了网络会超时,我最多5页5页的爬取,并把这些课堂链接保存到记事本里。
事情完成了一半,接下来的任务就是爬取记下来的链接中的视频了。
其实使用urllib.request就能把视频扒下来(大概),在这里我想练一下scrapy框架。
开始创建一个scrapy工程(scrapy安装就不说了):
在cmd中进入到你想要创建的目录中,输入scraoy startproject icourses:

打开创建好的工程,首先编写items.py,用来表示我要爬取的内容,对于我来说只需要视频名称(老师名)和视频地址就够了:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class IcoursesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
mp4name = scrapy.Field()
mp4url = scrapy.Field()
然后编写pipelines.py文件,用来设置爬取下来的东西的储存位置:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import urllib.request
class IcoursesPipeline(object):
def process_item(self, item, spider):
num = [1,2,3,4,5,6,7,8]
for i in range(0,len(item["mp4url"])):
thisurl = item['mp4url'][i]
url = thisurl + '.mp4'
num[i] = i
name = item['mp4name']
thisname = name + [num[i]]
urllib.request.urlretrieve(url, filename="d:/1/mp4/"+str(thisname)+".mp4")
return item
然后设置settings.py文件,去掉前面的注释符号就可以啦:
ITEM_PIPELINES = {
'icourses.pipelines.IcoursesPipeline': 300,
}
重头戏就是下面的主程序了,首先在工程内创建一个爬虫:

这是创建了一个basic模板的爬虫,还有其他模板书上没细讲,我也就放弃了。
之后开始修改创建的icourse.py文件:
# -*- coding: utf-8 -*-
import scrapy
import re
from icourses.items import IcoursesItem
from scrapy.http import Request
class IcourseSpider(scrapy.Spider):
name = 'icourse'
allowed_domains = ['icourse.cn']
f= open(r"d:/1/7.json","r")
s = f.readlines()
f.close()
start_urls = ['']
def parse(self, response):
item = IcoursesItem()
pattern ='(http://res2.icourses.cn/video/mobile/.*?).mp4'
item['mp4url'] = re.compile(pattern).findall(str(response.body))
item['mp4name']=response.xpath("//a[@class='teacher-infor-name']/text()").extract()
yield item
首先start_url内填上自己想要爬取的网页,我本来是想直接读出记事本的内容填进去,没想到总是出错,于是我就把网页直接复制进去了,网页太多,就不写出来了
其次xpath我还有很多地方搞不清楚,比如这里的老师我可以用他爬出来,但是视频链接怎么也搞不到,只能使用正则表达式,但是正则表达式我学的也不好,比如视频链接中有res1的内容:,也有res2的内容:,我写的正则表达式只能匹配到res2中的东西,按照书上使用匹配符号之类的都行不通,还是学的不精啊。
最后运行爬虫,还是在cmd中进入到工程目录,输入:
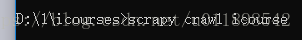
等着就行了,建议还是开着日志,否则出错了还得自己去找,太麻烦。
下载速度只有40k/s,下了整整一周才把后20页下完,还仅仅是res2内容的:
中间遇到的无数的bug就不多说了,希望有人能看到这个东西并且有所收获吧。
以上