前面介绍了基本的数据爬取,图片爬取的相关案例前面文章也有涉及,关于有些案例网站不能登录的问题,可以再找些别的网站,因为道理既然明白了,其实什么网站都一样,它有反爬机制,自然有应对它的办法,下面案例我也会给大家一个案例网站作为参考学习,关注我持续更新!
一.案例网站
网站链接:评论自取
页面参照:
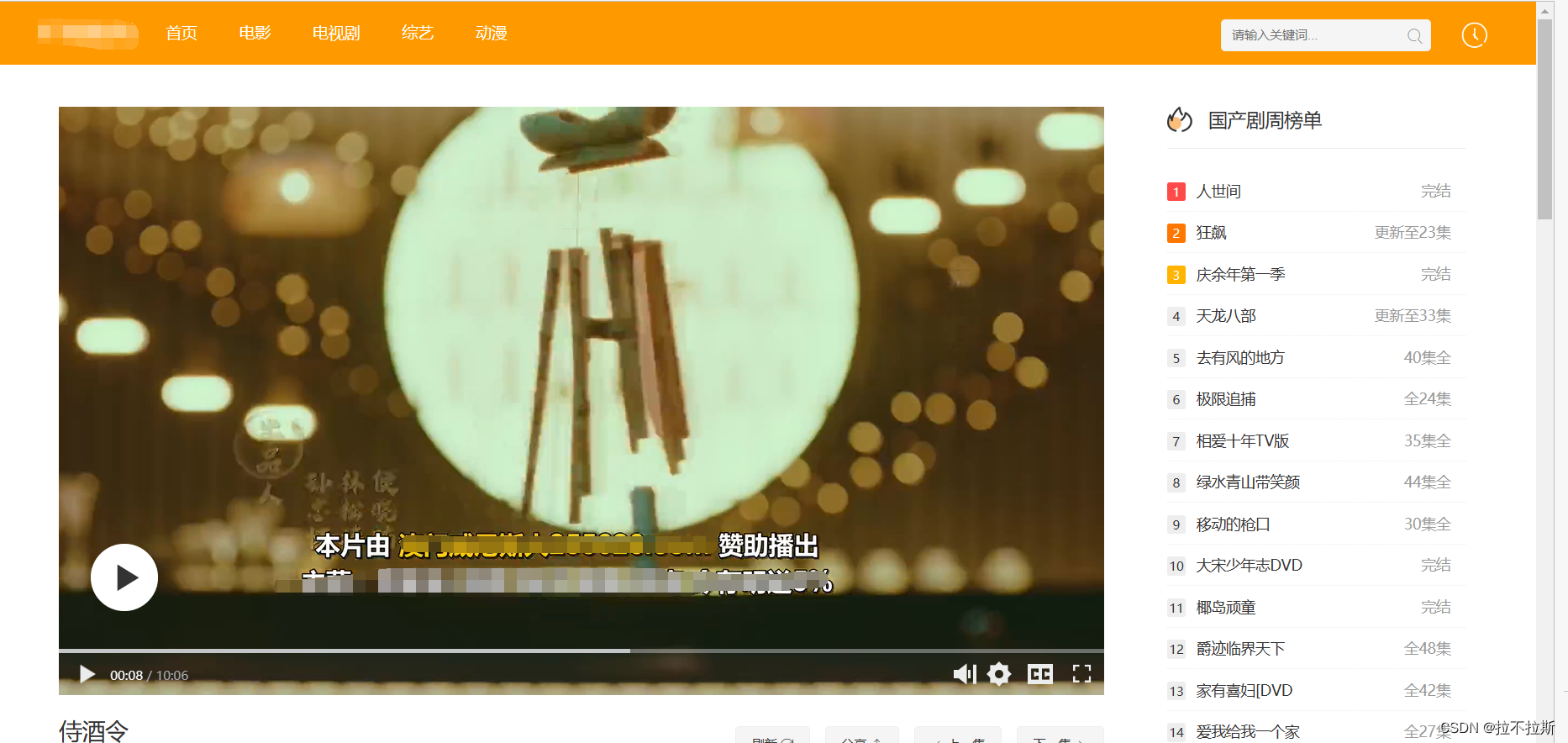
二.思路分析
1.获取m3u8文件
— m3u8文件将视频切片为一个个片段,时长不定,一般较短,可以通过获取m3u8文件获取对应ts文件链接,进而进行片段视频的下载,不过后续要使用第三方工具进行视频的整合,将一个个片段视频还原为整个视频。
2.进行ts视频下载
获取到的m3u8通过python函数,进行字符串处理,进行进行一个个片段视频的下载,视频以二进制格式存储,因此下载时,应使用.content方法进行下载;最后MP4格式进行持久化存储。
三.步骤分析及成果展示
这里给大家说出我自己的方法,可以先用抓包工具获取视频元素,可以发现大多数都是在video标签;此时可以查看网页源代码中是否有video标签,一般不会有,大家可以试试,这样自己才能理解的更加深刻。
故视频是通过ajax进行加载的,所以可以在"<script.>"标签中搜索video,这时候可能会有收获;再者,可以通过抓包工具进行搜索,
此案例采取第二种,因为本案例第一种行不通
m3u8文件一般格式(加密格式后续文章讲解解密)
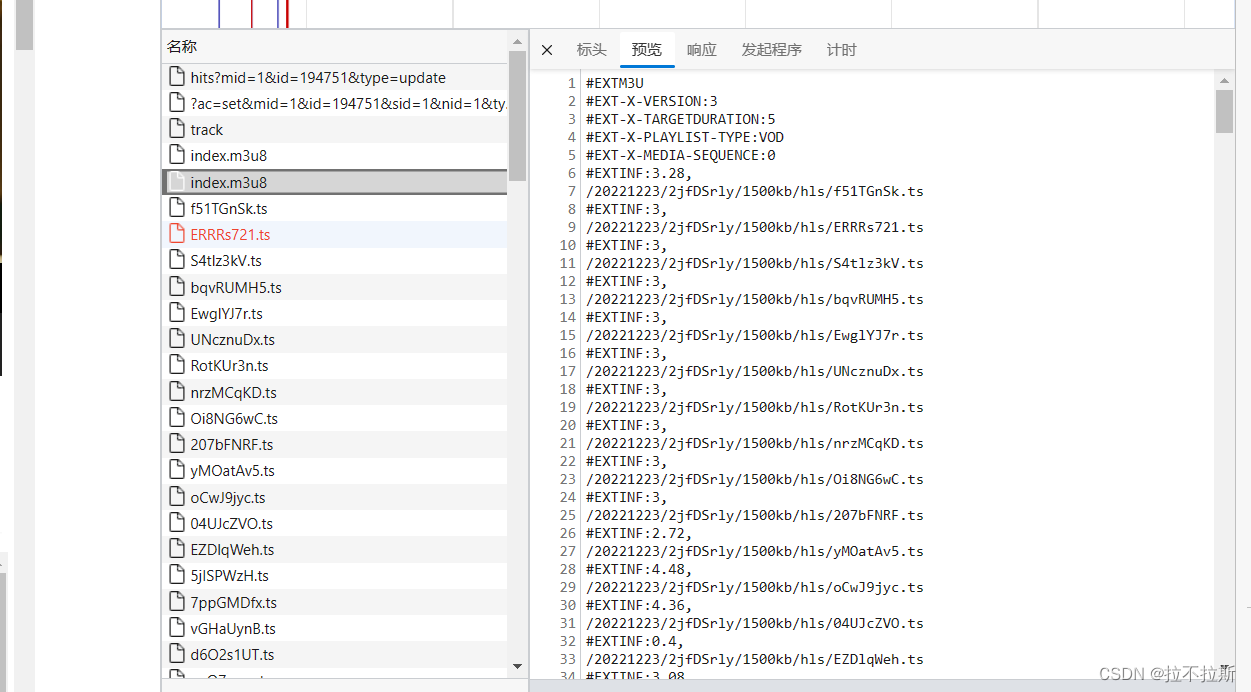
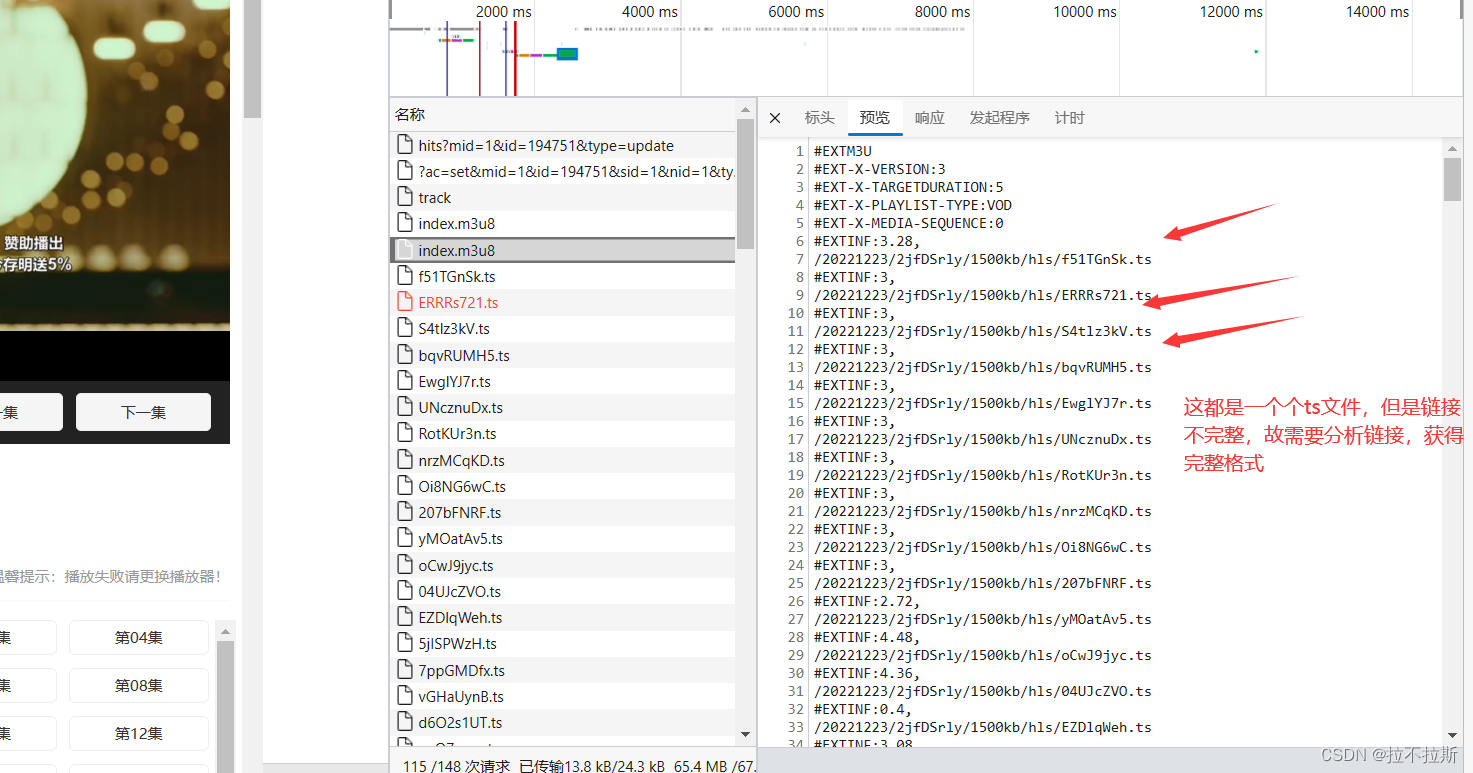
可以发现,ts文件的链接并不完整,但是可以分析:
分析已经在图片中给出:
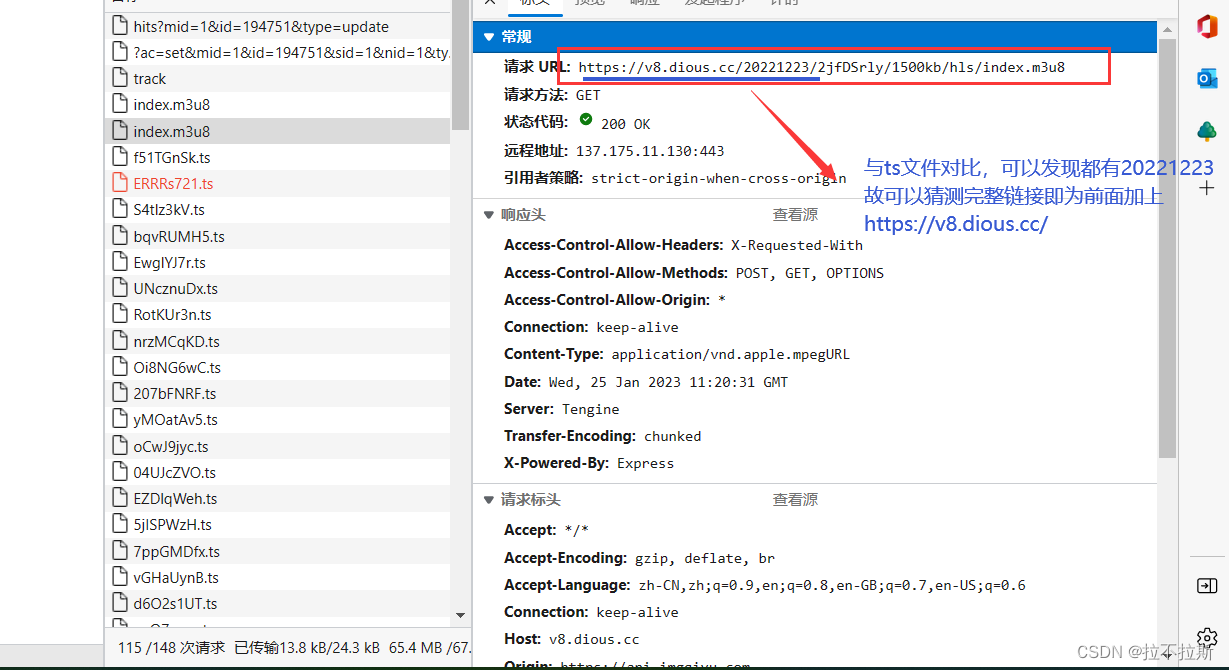
成果展示:
pycharm打开是乱码
找到根路径进行打开
1.ts

大家可以自己试着把获得的片段视频进行合成,下面给出代码
四.完整代码展示(动动你的小手三连吧,码字不易,求求啦!)
import requests
url="https://v8.dious.cc/20221223/2jfDSrly/1500kb/hls/index.m3u8"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.52"
}
n=1
response=requests.get(url=url,headers=headers)
with open("侍酒令第一集.txt","wb") as fp:
fp.write(response.content)
with open("侍酒令第一集.txt",mode="r",encoding="utf-8") as fp:
for line in fp:
line=line.strip()
if line.startswith("#"):
continue
last_tspath="https://v8.dious.cc"+line
resp3=requests.get(last_tspath)
f=open(f"{
n}.ts",mode="wb")
f.write(resp3.content)
n+=1