在目前的机器学习研究中,从少量的训练数据中进行学习还是一个非常大的挑战。例如在视觉、文本的处理上,传统的有监督的深度学习方法不能够从有限的数据中有效的学习新的概念。
本文受到利用深度神经网络来学习图像、文本特征的启发,通过拓展的外部信息加强记忆神经网络的效果,提出了一种针对one-shot学习的神经网络模型-Matching Net (MN).该模型可以将一个小的标注集合以及一个未标注的测试样例映射到它对应的标签,在这个过程中避免了对于新的标签类别进行调整的需求。
该方法在ImageNet数据集的one-shot准确率从87.6%提升到了93.2%,在Omniglot数据集上的效果从88.0%提升到了93.8%
1 Motivation
humans learn new concepts with very little supervision(one-shot learning)
data augmentation and regularization alleviate but do not solve over-fitting
non-parametric models allow novel examples to be rapidly assimilated
(training examples need to be slowly learnt by the model into its parameters)
2 Innovation
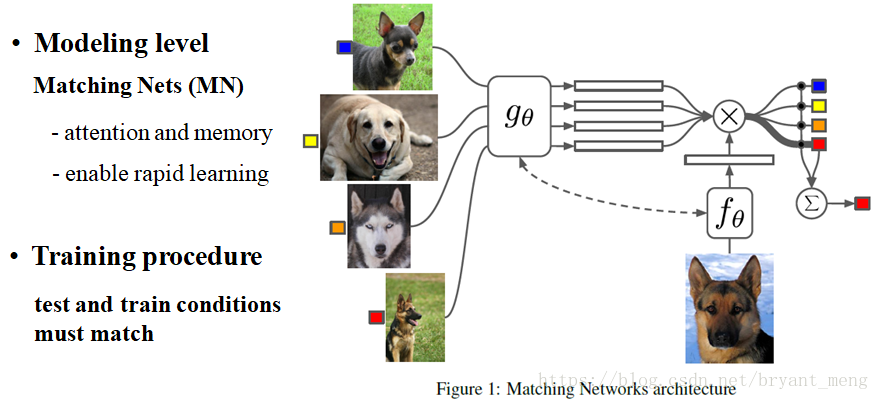
3 Method
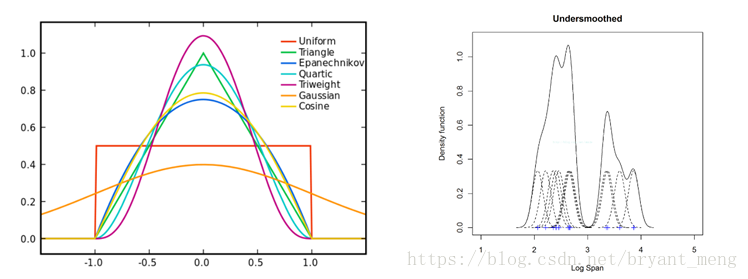
非参数估计方法(核密度估计KDE-Kernel Density Estimation)是一种从数据样本本身出发研究数据分布特征的方法,是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。
3.1 matching network
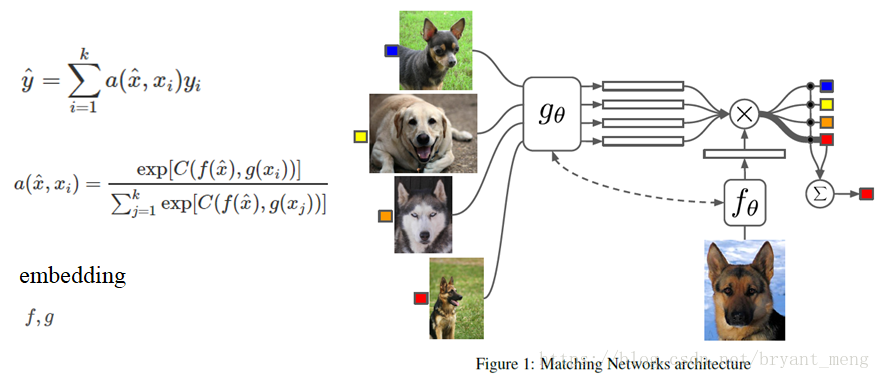
a是attention机智
g(x)和f(x)在3.1.3和3.1.4中有讲解
如下

- T: task, distribution over possible label sets, typically as uniformly
- L: label sets, eg:{dogs, cats, pigs}, each label set is small, eg: 5 examples
- S: support set, sample from label sets
- B: batch, sample from label sets
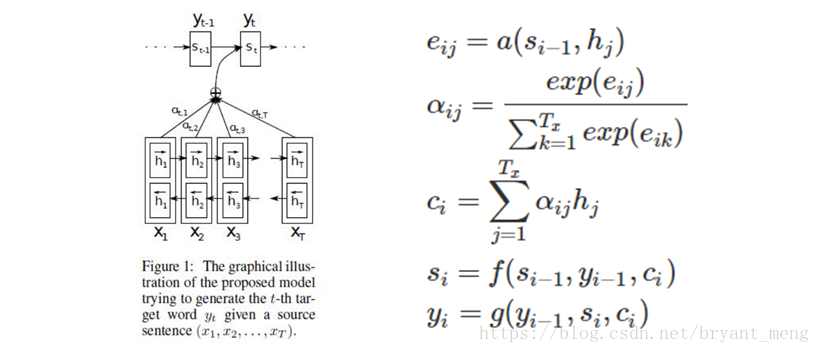
3.1.1 Sequence to sequence with attention
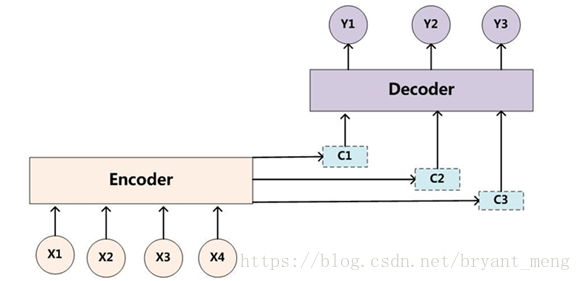
细节一点如下(双向RNN+attention)
3.1.2 Memory networks
LSTM
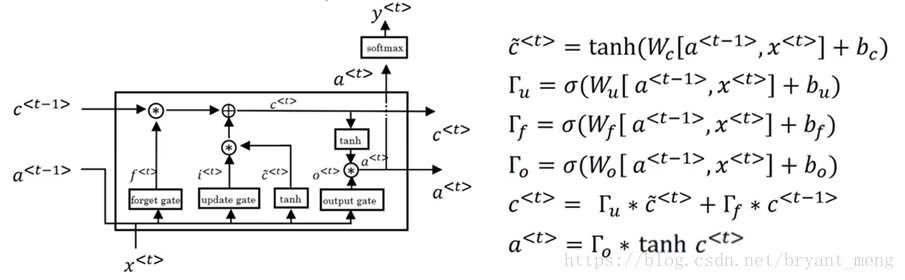
文章中是bidirectional LSTM,下图中框框换成LSTM结构就行
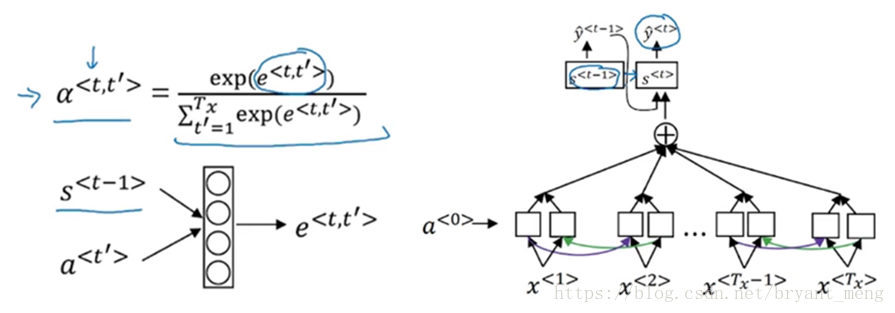
3.1.3 g(x)
【平价数据】One Shot Learning
总结的非常好
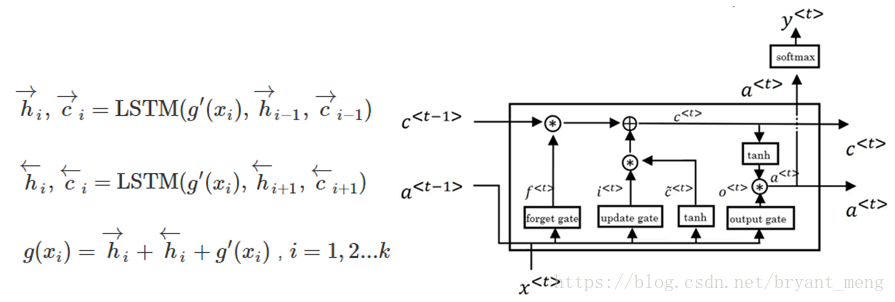
左边公式中的h即为右边图中的a
3.1.4 f(x)
加了attention,[h,r]处

3.1.5 Pointer networks
4 Experiments
4.1 Omniglot
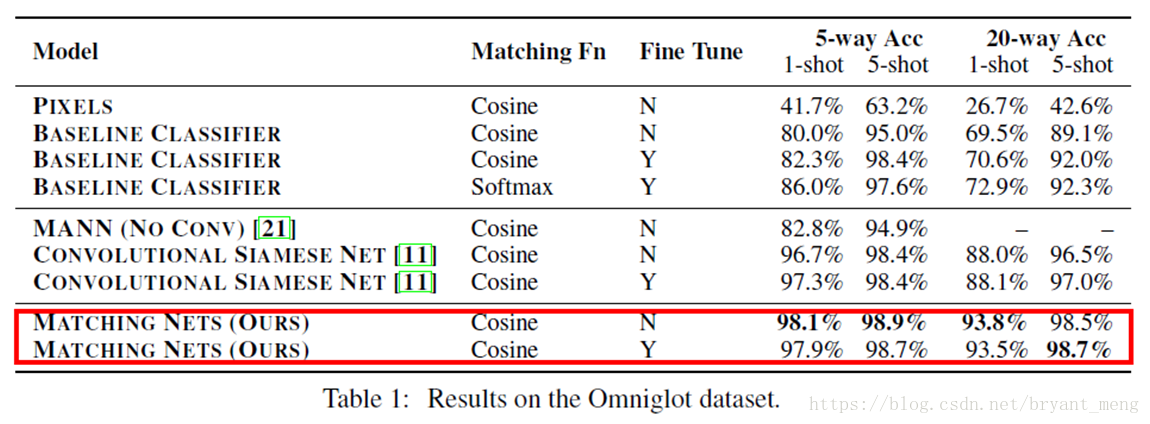
Full Contextual Embedding(FCE)对Omniglot没什么影响
5-shot > 1-shot
20-way > 5-way
4.2 MNIST
像Siamese Nets那样直接从Omniglot迁移到MNIST效果如下:
- 63% Baseline classifier
- 70% Siamese Nets
- 72% Matching Nets
其中baseline classifier 结构如下
4层CNN
input: 28*28
每层都是
3x3x64 fiters
BN
Relu
2x2 maxpooling
28 →14→ 7→ 3 →1
最后结果为1x1x64
4.3 miniImageNet
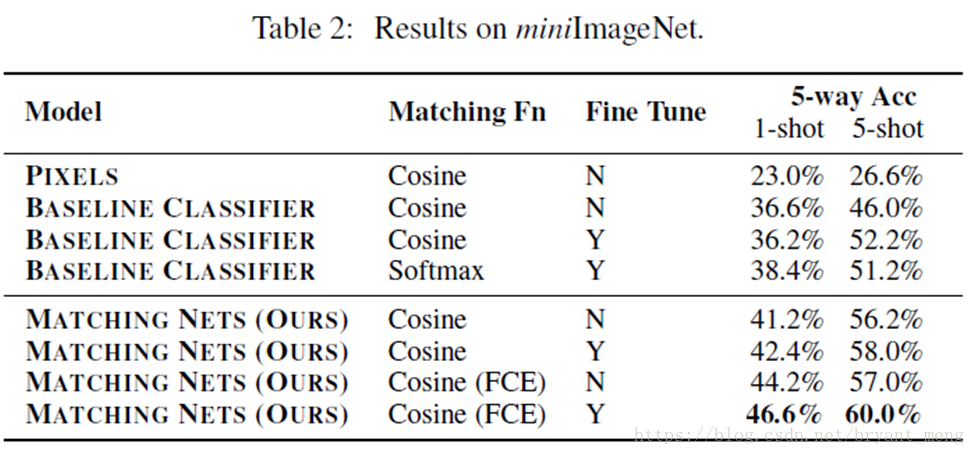
- 100classes from ImageNet
80 train
20 test
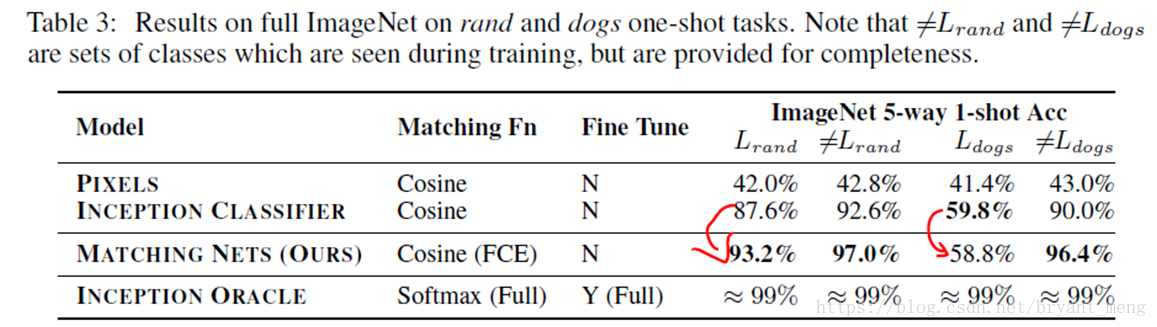
4.4 rand and dogs
dogs setup
train: ImageNet-118(狗) classes
test: 118(狗) classesrand setup
train: ImageNet-118(随机) classes
test: 118(随机) classes
5 Conclusion
- one-shot learning is much easier if you train the network to do one-shot learning
- non-parametric structures in a neural network make it easier for networks to remember and adapt to new training sets in the same tasks.
结合以上两点,产生matching network
缺点
- as the support set S grows in size, the computation for each gradient update becomes more expensive
- when the label distribution has obvious biases (such as being fine grained), our model suffers
参考
[1] 论文引介 | Matching Networks for One Shot Learning
[2] 非参数估计:核密度估计KDE
[4] 核概率密度估计
[5] 统计学习方法:核函数(Kernel function)
[6] 上海交通大学公开课:数学之旅
[7] 专家坐堂:机器学习对核函数的理解
[8] 如何理解线性赋范空间、希尔伯特空间, 巴拿赫空间,拓扑空间
[11] Matching Networks for one Shot Learning 阅读笔记
[12] paper-notes/matching_networks.md
[13] Github-AntreasAntoniou/MatchingNetworks
[14] Github-cnichkawde/MatchingNetwork
[15] Pointer Networks