卷积

示意图
A:卷积核矩阵,M卷积核的数量,也是输出的channel,K为卷积核的大小,K可以理解为k*k(卷积核的长、宽)。
B:输入图像矩阵,K为对应卷积核大小的矩阵块。N为输出矩阵特征的长和宽。
N=((image_h + 2*pad_h – kernel_h)/stride_h+ 1)*((image_w +2*pad_w – kernel_w)/stride_w + 1)
image_h:输入图像的高度
image_w:输入图像的宽度
pad_h:在输入图像的高度方向两边各增加pad_h个单位长度(因为有两边,所以乘以2)
pad_w:在输入图像的宽度方向两边各增加pad_w个单位长度(因为有两边,所以乘以2)
kernel_h:卷积核的高度
kernel_w:卷积核的宽度
stride_h:高度方向的滑动步长;
stride_w:宽度方向的滑动步长。C:输出特征图,M为通道数,N为输出矩阵特征的长和宽。共有M个输出图像。(在Caffe中是使用src/caffe/util/im2col.cu中的im2col和col2im来完成矩阵的变形和还原操作)。
举个例子:
假设有两个卷积核为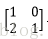
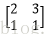
输入图像矩阵为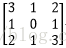
故N=[(3+2*0-2)/1+1]*[ (3+2*0-2)/1+1]=2*2=4。
A矩阵(M*K)为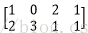
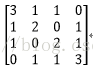
C=A*B=
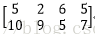
C中的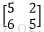
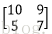
反卷积
经过上面的解释与推导,对卷积有基本的了解,但是在图像上的deconvolution究竟是怎么一回事,可能还是不能够很好的理解,因此这里再对这个过程解释一下。
目前使用得最多的deconvolution有2种,上文都已经介绍。
方法1:full卷积, 完整的卷积可以使得原来的定义域变大
方法2:记录pooling index,然后扩大空间,再用卷积填充
目前使用得最多的deconvolution有2种,上文都已经介绍。
方法1:full卷积, 完整的卷积可以使得原来的定义域变大
方法2:记录pooling index,然后扩大空间,再用卷积填充
图像的deconvolution过程如下,
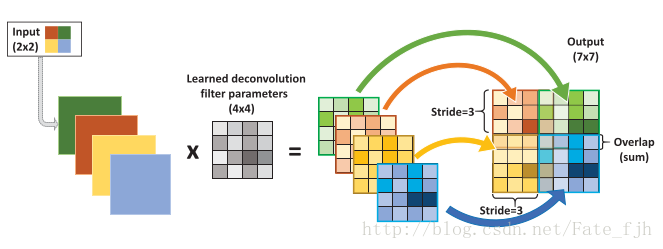
输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7
即输入为2x2的图片经过4x4的卷积核进行步长为3的反卷积的过程
1.输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图
2.将4个特征图进行步长为3的fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
可以看出翻卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小
得到 out = (in - 1) * s + k
上图过程就是, (2 - 1) * 3 + 4 = 7
参考:
https://blog.csdn.net/xiaoyezi_1834/article/details/50786363
https://blog.csdn.net/q295684174/article/details/79064580