1. Spark SQL
- 用于处理结构化数据,提供SQL语句查询的API接口
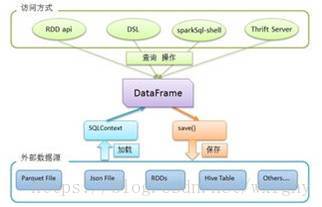
SparkSQL数据类型DataFrames
- 这种数据类型支持结构化的数据文件,Hive中的表,外部数据库和已存在的RDD
- 该接口在Python, R, Java, Scala中都是可用的
SparkSQL数据类型DataSets
- Spark 1.6中添加的新接口
- 不支持Python
SparkSQL特点
- 兼容好
兼容Hive,支持RDD,JSON文件等数据源,支持nosql数据库数据 - 性能高
含有多种性能优化技术 - 扩展强
SQL的语法解析,分析和优化都可自定义
SparkSQL性能优化技术
- 内存列存储In-Memory Columnar Storage
优化空间占用量和读取吞吐率 - 字节码生成bytecode generation
优化所有的SQL表达式,通过scala运行时放射机制实现
SparkSQL运行架构
- SQL语句解析(parse),找出查询项和数据源等
- SQL语句与数据库的数据字典绑定(bind),判断是否可执行
- 对提供的多种执行计划进行优化(optimize)
- 实际执行(execute)
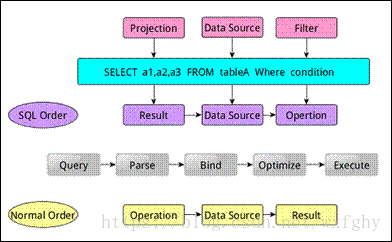
包含sqlContext和hiveContext两个分支
- sqlContext不支持hive查询语句
- hiveContext是SQLContext子类,支持hql查询
SparkSQL代码实现
spark-shell
val rdd1=sc.textFile("/demo.txt")# 读取hdfs文件
val rdd2=rdd1.map(_.split(","))# 按,拆分字符串
# case class生成封装类,仅包含属性和类型,getset方法scala自带
case class stu(sno:Int,dname:String,loc:String)
# 调用封装类stu,将拆分后的字符串转为相应类型装入
val res=rdd2.map(line=>stu(line(0).toInt,line(1),line(2)))
val df=res.toDF# 转换为DataFrames类型
# (1)DSL模式查询,即DataFrames Style
df.select("dname").show # 查询列
df.printSchema # 查看表结构
# (2)SQL模式查询
# 实例化SQLContext装入sparkContext
val sqlctx=new org.apache.spark.sql.SQLContext(sc)
df.registerTempTable("tok")# 临时生成一张表
sqlctx.sql("select * from tok").show# SQL语句查询该表idea中scala编程
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SQLContext
case class stu(sno:Int,dname:String,loc:String)
object demo {
def main(args: Array[String]): Unit = {
var sconf=new SparkConf()
sconf.setMaster("local")
sconf.setAppName("demo")
var sc=new SparkContext(sconf)
val rdd1=sc.textFile("file:///d:/demo.txt").map(_.split(" "))
var res=rdd1.map(line=>stu(line(0).toInt,line(1),line(2)))
val sqlctx=new SQLContext(sc)
//通过sql提供的上下文对象,导入.implicits._
import sqlctx.implicits._
val df=res.toDF()
df.registerTempTable("tok")
sqlctx.sql("select * from tok").show()
sc.stop()
}2. Spark Streaming
- 构建在Spark上的实时计算框架,基于内存的高速执行引擎,结合流式,批处理和交互式查询
Spark Streaming数据的输入和输出
- 支持实时数据的可扩展,高吞吐,高容错的流处理
- 数据源如kafka,flume等
- 数据输出如hdfs,redis,hbase等

Spark Streaming特点
- 高效,高容错,准实时性(秒级别)
- 精简复杂算法的实现
- 集成Spark批处理和交互式查询功能
Spark Streaming运行架构
- Spark Streaming把实时输入数据流以时间片为单位切分成块
- 然后把每块数据作为一个RDD,并使用RDD操作处理每一小块数据
- 每个块都会生成一个Spark Job处理,最终结果也返回多块
DStream(离散流)(可以当做RDD处理)
- Spark Streaming支持一个高层的抽象,叫做离散流(discretized stream)或者DStream
- 连续的数据流
- Kafka, Flume和Kinesis等源获取的输入数据流
- 在其他DStream的基础上通过高阶函数获得
- 在内部,DStream是由一系列RDDs组成
- 支持scala、java或者Python编写Spark Streaming程序
Spark Streaming代码实现
- 在远程虚拟机上通过ncat发送数据包,sparkstreaming监听其字符串
ncat -lk 10.25.34.65 9999进入待发送状态,输入字符串
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object streaming {
def main(args: Array[String]): Unit = {
//1 创建SparkConf对象
val conf=new SparkConf()
conf.setAppName("Spark Streaming")
//设置开启本地cpu资源
conf.setMaster("local[2]")
//2 创建streamingcontext对象,10秒扫描一次,每次经过10秒就会生成一次输出文件
val ctx=new StreamingContext(conf,Seconds(10))
//3 设置监听IP和端口
val ds=ctx.socketTextStream("10.25.34.65",9999)
//4 获取RDD,便于处理wordcount
val res=ds.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_)
res.saveAsTextFiles("file:///d:/streamingout/")//写入本地目录,这是一个根目录的路径
//5 启动streaming
ctx.start()
//6 等待接收数据
ctx.awaitTermination()
//7 关闭sparkstreaming和sparkcontext
ctx.stop(true)
}
}