Spark SQL 简介
Spark SQL官方介绍
●官网
Spark SQL是Spark用来处理结构化数据的一个模块。
Spark SQL还提供了多种使用方式,包括DataFrames API和Datasets API。但无论是哪种API或者是编程语言,它们都是基于同样的执行引擎,因此你可以在不同的API之间随意切换,它们各有各的特点。
●Spark SQL 的特点
1.易整合
可以使用java、scala、python、R等语言的API操作。
2.统一的数据访问
连接到任何数据源的方式相同。
3.兼容Hive
支持hiveHQL的语法。
兼容hive(元数据库、SQL语法、UDF、序列化、反序列化机制)
4.标准的数据连接
可以使用行业标准的JDBC或ODBC连接。
SQL优缺点
●SQL的优点
表达非常清晰, 比如说这段 SQL 明显就是为了查询三个字段,条件是查询年龄大于 10 岁的
难度低、易学习。
●SQL的缺点
复杂分析,SQL嵌套较多:试想一下3层嵌套的 SQL维护起来应该挺力不从心的吧
机器学习较难:试想一下如果使用SQL来实现机器学习算法也挺为难的吧
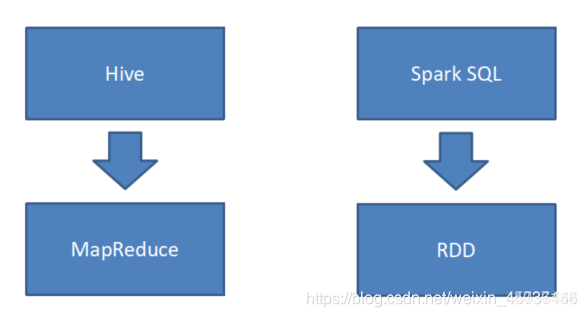
Hive和SparkSQL
Hive是将SQL转为MapReduce
SparkSQL可以理解成是将SQL解析成’RDD’ + 优化再执行
Spark SQL数据抽象
DataFrame
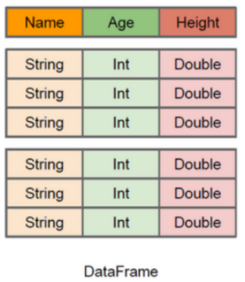
●什么是DataFrame
DataFrame是一种以RDD为基础的带有Schema元信息的分布式数据集,类似于传统数据库的二维表格 。
DataSet
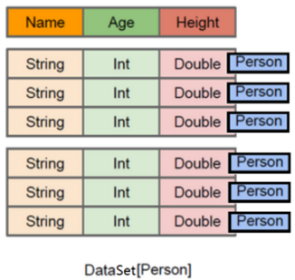
●什么是DataSet
DataSet是保存了更多的描述信息,类型信息的分布式数据集。
与RDD相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表。
与DataFrame相比,保存了类型信息,是强类型的,提供了编译时类型检查,
调用Dataset的方法先会生成逻辑计划,然后被spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行!
DataSet包含了DataFrame的功能,
Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
DataFrame其实就是Dateset[Row]
RDD、DataFrame、DataSet的区别
●结构图解


RDD[Person]
以Person为类型参数,但不了解 其内部结构。
DataFrame
提供了详细的结构信息schema列的名称和类型。这样看起来就像一张表了
DataSet[Person]
不光有schema信息,还有类型信息
Spark SQL 体验
入口-SparkSession
●在spark2.0版本之前
SQLContext是创建DataFrame和执行SQL的入口
HiveContext通过hive sql语句操作hive表数据,兼容hive操作,hiveContext继承自SQLContext。
●在spark2.0之后
SparkSession 封装了SqlContext及HiveContext所有功能。通过SparkSession还可以获取到SparkConetxt。
SparkSession可以执行SparkSQL也可以执行HiveSQL.

创建DataFrame
创读取文本文件
在本地创建一个文件,有id、name、age三列,用空格分隔,然后上传到hdfs上
vim /root/person.txt
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40
上传数据文件到HDFS上:
hadoop fs -put /root/person.txt /
2.在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
打开spark-shell
/export/servers/spark/bin/spark-shell
创建RDD
val lineRDD= sc.textFile(“hdfs://node01:8020/person.txt”).map(_.split(" ")) //RDD[Array[String]]
3.定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)
4.将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt)) //RDD[Person]
5.将RDD转换成DataFrame
val personDF = personRDD.toDF //DataFrame
6.查看数据和schema
personDF.show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 29|
| 3| wangwu| 25|
| 4| zhaoliu| 30|
| 5| tianqi| 35|
| 6| kobe| 40|
+---+--------+---+
personDF.printSchema
7.注册表
personDF.createOrReplaceTempView(“t_person”)
8.执行SQL
spark.sql(“select id,name from t_person where id > 3”).show
9.也可以通过SparkSession构建DataFrame
val dataFrame=spark.read.text(“hdfs://node01:8020/person.txt”)
dataFrame.show //注意:直接读取的文本文件没有完整schema信息
dataFrame.printSchema
读取json文件
1.数据文件
使用spark安装包下的json文件
more /export/servers/spark/examples/src/main/resources/people.json
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
2.在spark shell执行下面命令,读取数据
val jsonDF= spark.read.json(“file:////export/servers/spark-on-yarn/examples/src/main/resources/people.json”)
3.接下来就可以使用DataFrame的函数操作
jsonDF.show
//注意:直接读取json文件有schema信息,因为json文件本身含有Schema信息,SparkSQL可以自动解析
读取parquet文件
1.数据文件
使用spark安装包下的parquet文件
more /export/servers/spark/examples/src/main/resources/users.parquet
2.在spark shell执行下面命令,读取数据
val parquetDF=spark.read.parquet(“file:///export/servers/spark/examples/src/main/resources/users.parquet”)
3.接下来就可以使用DataFrame的函数操作
parquetDF.show
//注意:直接读取parquet文件有schema信息,因为parquet文件中保存了列的信息
创建DataSet
1.通过spark.createDataset创建Dataset
val fileRdd = sc.textFile(“hdfs://node01:8020/person.txt”) //RDD[String]
val ds1 = spark.createDataset(fileRdd) //DataSet[String]
ds1.show
2.通RDD.toDS方法生成DataSet
case class Person(name:String, age:Int)
val data = List(Person(“zhangsan”,20),Person(“lisi”,30)) //List[Person]
val dataRDD = sc.makeRDD(data)
val ds2 = dataRDD.toDS //Dataset[Person]
ds2.show
3.通过DataFrame.as[泛型]转化生成DataSet
case class Person(name:String, age:Long)
val jsonDF= spark.read.json(“file:///export/servers/spark/examples/src/main/resources/people.json”)
val jsonDS = jsonDF.as[Person] //DataSet[Person]
jsonDS.show
4.DataSet也可以注册成表进行查询
jsonDS.createOrReplaceTempView(“t_person”)
spark.sql(“select * from t_person”).show
DSL,SQL两种查询风格
准备工作
读取文件并转换为DataFrame或DataSet
val lineRDD= sc.textFile(“hdfs://node01:8020/person.txt”).map(_.split(" "))
case class Person(id:Int, name:String, age:Int)
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
val personDF = personRDD.toDF
personDF.show
//val personDS = personRDD.toDS
//personDS.show
DSL风格
SparkSQL提供了一个领域特定语言(DSL)以方便操作结构化数据
1.查看name字段的数据
personDF.select(personDF.col(“name”)).show
personDF.select(personDF(“name”)).show
personDF.select(col(“name”)).show
personDF.select(“name”).show
2.查看 name 和age字段数据
personDF.select(“name”, “age”).show
3.查询所有的name和age,并将age+1
personDF.select(personDF.col(“name”), personDF.col(“age”) + 1).show
personDF.select(personDF(“name”), personDF(“age”) + 1).show
personDF.select(col(“name”), col(“age”) + 1).show
personDF.select(“name”,“age”).show
//personDF.select(“name”, “age”+1).show
personDF.select( “age”,$“age”+1).show
4.过滤age大于等于25的,使用filter方法过滤
personDF.filter(col(“age”) >= 25).show
personDF.filter($“age” >25).show
5.统计年龄大于30的人数
personDF.filter(col(“age”)>30).count()
personDF.filter($“age” >30).count()
6.按年龄进行分组并统计相同年龄的人数
personDF.groupBy(“age”).count().show
SQL风格
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用spark.sql() 来执行SQL查询,结果将作为一个DataFrame返回
如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:
personDF.createOrReplaceTempView(“t_person”)
spark.sql(“select * from t_person”).show
1.显示表的描述信息
spark.sql(“desc t_person”).show
2.查询年龄最大的前两名
spark.sql(“select * from t_person order by age desc limit 2”).show
3.查询年龄大于30的人的信息
spark.sql("select * from t_person where age > 30 ").show
4.使用SQL风格完成DSL中的需求
spark.sql(“select name, age + 1 from t_person”).show
spark.sql(“select name, age from t_person where age > 25”).show
spark.sql(“select count(age) from t_person where age > 30”).show
spark.sql(“select age, count(age) from t_person group by age”).show
总结
1.DataFrame和DataSet都可以通过RDD来进行创建
2.也可以通过读取普通文本创建–注意:直接读取没有完整的约束,需要通过RDD+Schema
3.通过josn/parquet会有完整的约束
4.不管是DataFrame还是DataSet都可以注册成表,之后就可以使用SQL进行查询了! 也可以使用DSL!
