前言
本篇博客出于学习交流目的,主要是用来记录自己学习多目标优化中遇到的问题和心路历程,方便之后回顾。过程中可能引用其他大牛的博客,文末会给出相应链接,侵删!
REMARK:本人菜鸟一枚,如有理解错误还望大家能够指出,相互交流。也是第一次以博客的形式记录,文笔烂到自己都看不下去,哈哈哈
这篇学习笔记关于一种基于多目标进化算法的高效用频繁项集挖掘算法。
参考文献:A Multi-Objective Evolutionary Approach for Mining Frequent and High Utility Itemsets
论文中涉及多目标进化算法部分可以参考我写的多目标优化学习笔记,里头有比较详细的理解说明。
正文
论文贡献:不需要指定类似最小支持度或者最小效用值之类的先验参数,只需运行一次
高效用频繁模式挖掘特点:低支持度的项集通常有较高的效用值
论文将频繁度和效用值同时作为目标项集的评价分量,运用多目标优化的方法进行频繁项集挖掘
相关符号表示
事务集表单(Transaction table )
总项集(distinct items)
项集(Itemset)
事务中所有含有
的事务集合(
of
)
最小支持度(minimum support threshold
_
)
权重方程(weight function)
(
表示现实为非负)
事务
中的项目集
的权重
事务
的权重
相关定义
Definition1.项集
的效用值
Definition2.项集
的最终效用值(quality)
MOEA-FHUI算法
算法框架如下图所示
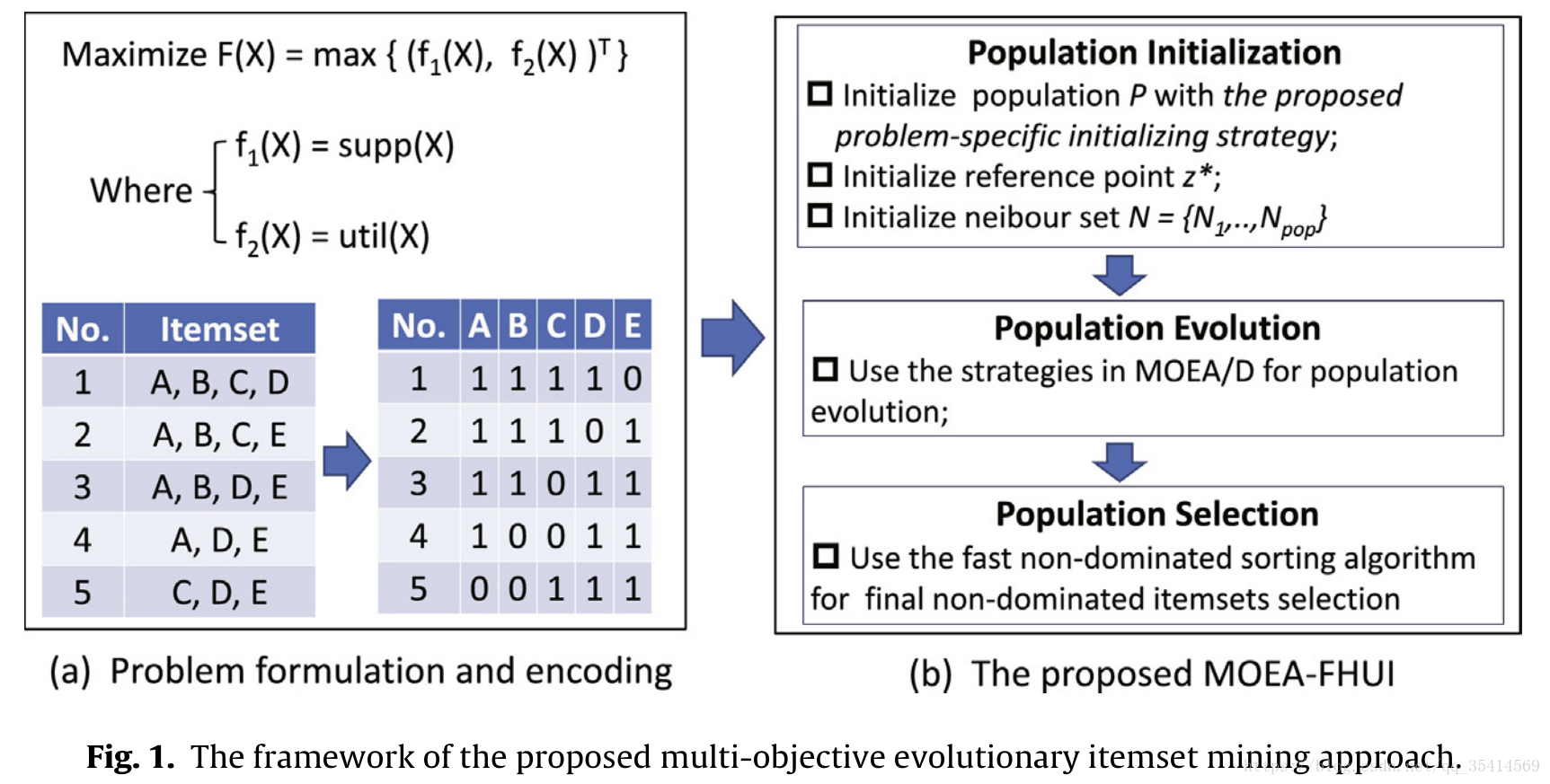
首先,将事务集用one-hot编码(出现位置为1,否则为0)表示,并定义效用值和支持度为评估函数的两个目标分量。这里只用考虑Item,而不用考虑内部效用值,即出现次数;因为之后的评估指标是统计整个
。在这个问题中,由于考虑效用值和频繁度,所以我们考虑两个分量。MOEA/D算法相关可以查看多目标优化学习笔记(三)MOEA/D,这里默认大家都了解了。

设置好算法的pop(权值向量的个数)、邻集大小、个体重组率和突变率等参数。
Step1:种群初始化
1)用特殊问题策略进行初代种群的生成;
为了避免随机初始化产生许多无用的解,作者设计了一个初始化策略:
1.生成的个体必须是在交易集中的存在的,否则是无意义的;
2.通过交叉变异得到的子个体的生成尽可能有效并且多样;
从 中得到两类数据集,一类是transaction-itemset,即出现在 中的每条transaction;另一类是meta-itemset,只包含一个item。
对每个meta-itemset计算 ,然后计算支持度总和 ,于是对每个meta-itemset我们可以得到 ;同理,对于每个transaction-itemset我们可以计算的到 。
然后根据这两个指标从 进行随机选择子样本,从meta-itemsets中选 ,从transaction-itemsets中选 。
2)计算
,在这个问题中
;即效用值和频繁度两个分量考虑
3)计算每个个体
到权值向量
的欧式距离;
4)更新邻集;
Step2:种群进化
运用MOEA/D的种群更新算法;相比较传统高效用频繁项集挖掘算法,MOEA/D用切比雪夫值作为评估,而不用指定最小效用值和最小支持度。
Step3:获得最终解
达到停止条件,遗传算法的最终解;为了选择出感兴趣的项集,对最终生成的种群进行快速非支配排序(原文使用ENS),最终
作为最终解。
评价指标
Hypervolume值
常用来衡量多目标优化算法的好坏,权衡收敛性和多样性,Hypervolume值越大,结果越优。
Coverage值
常用于评价推荐系统的多样性,公式如下:
是项的总数目, 是不同项在推荐列表上的数目,Coverage值越高,说明推荐列表结果越多样。
总结
该算法只需要运行一次即可等到频繁项集,并且不需要设置最小支持度最小效用值等参数(需要设置遗传算法的一些参数)
PS.在算法比较中,对于一些项集没有权重的情况,文中提到了一种生成权重的方法。