1、文本挖掘与文本分类的概念
简言之,文本挖掘就是从非结构化的文本中寻找知识的过程。其7个主要领域如下:
- 搜索和信息检索(IR):存储和文本文档的检索,包括搜索引擎和关键字搜索。
- 文本聚类:使用聚类方法,对词汇、片段、段落或文件进行分组和归类。
- 文本分类:对片段、段落或文件进行分组和归类,在使用数据挖掘分类方法的基础上,经过训练地标记示例模型。
- Web挖掘:在互联网上进行数据和文本挖掘,并特别关注网络的规模和相互联系。
- 信息抽取(IE):从非结构化文本中识别与提取有关的事实和关系;从非结构话或半结构化文本中抽取出结构化数据的过程。
- 自然语言处理(NLP):将语言作为一种有意义、有规则的符号系统,在底层解析和理解语言的任务;目前的技术主要从语法、语义的角度发现语言最本质的结构和所表达的意义。
- 概念提取:把单词和短语按语义分成意义相似的组。
2、文本分类项目
中文语言的文本分类技术与流程:
- 预处理:去除文本的噪声信息,例如HTML标签、检测句子边界等。
- 文本分词:使用中文分词器为文本分词,并去除停用词。最终完全解决中文分词的算法是基于概率图模型的条件随机场(CRF)。目前,文本的结构化表示简单分为四大类:词向量空间模型、主题模型、依存句法的树表示、RDF的图表示,它们都是以分词为基础的。使用结巴分词
- 构建词向量空间:统计文本词频,生成文本的词向量空间。人工输入的停用词(常用词、语气助词等)
- 权重策略---TF-IDF方法:使用TF-IDF发现特征词,并抽取为反映文档主题的特征。
- 分类器:使用算法训练分类器。
- 评价分类结果:分类器的测试结果分析。
向量空间模型把文本表示一个向量,该向量的每个特征表示为文本中出现的词。它将文本中的词和模式串转换位数字,而整个文本集也都转换为维度相等的词向量矩阵。
TF-IDF(词频逆文档频率):其含义是如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。对词计数进行归一化,将词频信息变为概率分布,这就是文档的TF信息。如何体现生成的词袋中的词频信息呢?由于词袋收集了所有文档中的词,这些词的词频是针对所有文档的词频,因此,词袋的统计基数是文档数。所以IDF权重为log(D/j) ,包含词语的文件数目
分类器:常用的文本分类方法有kNN最近邻算法、朴素贝叶斯算法和SVM。一般而言,kNN最近邻算法的原理最简单,分类精度尚可,但是速度最慢;朴素贝叶斯算法对于短文本分类的效果最好,精度很高;支持向量机算法的优势是支持线性不可分的情况,精度上取中。


kNN:如果一个样本在特征空间中的k个最邻近(最相似)的样本中的大多数都属于某个类别,则该样本也属于这个类别。

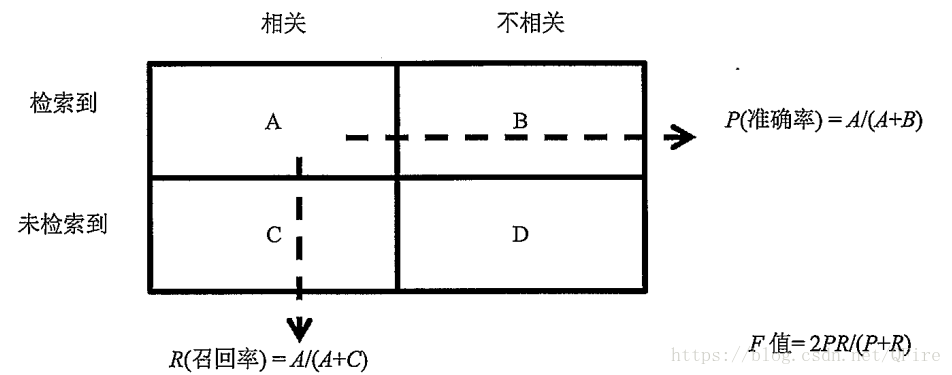
分类结果评估:召回率(查全率),准确率(查准率),F-Score(常用的评价标准)