深度学习近一段时间以来在图像处理和NLP任务上都取得了不俗的成绩。通常,图像处理的任务是借助CNN来完成的,其特有的卷积、池化结构能够提取图像中各种不同程度的纹理、结构,并最终结合全连接网络实现信息的汇总和输出。RNN由于其记忆功能为处理NLP中的上下文提供了途径。
在短文本分析任务中,由于句子句长长度有限、结构紧凑、能够独立表达意思,使得CNN在处理这一类问题上成为可能。论文Convolutional Neural Networks for Sentence Classification(论文作者Yoon Kim)即在这一类问题上做了尝试。首先来看看论文中介绍的模型结构及原理:
CNN模型结构如下:
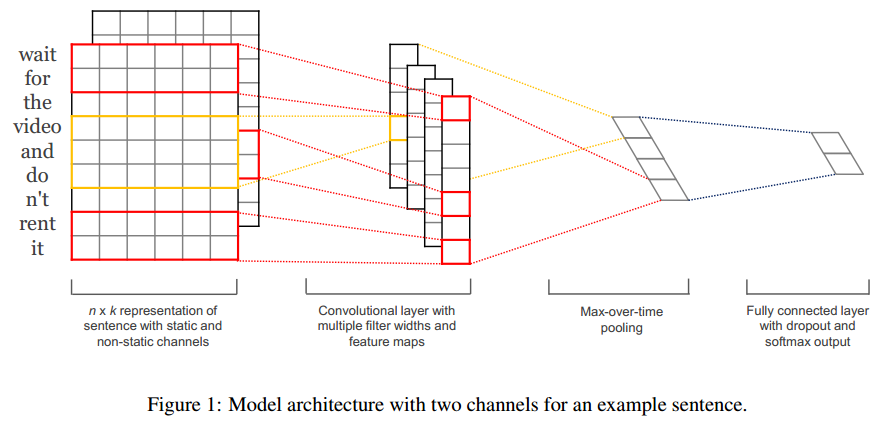
一共包括4部分:
1、 输入层:
如图所示,输入层是句子中的词语对应的wordvector依次(从上到下)排列的矩阵,假设句子有 n 个词,vector的维数为 k ,那么这个矩阵就是 n × k 的(在CNN中可以看作一副高度为n、宽度为k的图像)。
这个矩阵的类型可以是静态的(static),也可以是动态的(non static)。静态就是word vector是固定不变的,而动态则是在模型训练过程中,word vector也当做是可优化的参数,通常把反向误差传播导致word vector中值发生变化的这一过程称为Fine tune。(这里如果word vector如果是随机初始化的,不仅训练得到了CNN分类模型,还得到了word2vec这个副产品了,如果已经有训练的word vector,那么其实是一个迁移学习的过程)
对于未登录词的vector,可以用0或者随机小的正数来填充。
2、 第一层卷积层:
输入层通过卷积操作得到若干个Feature Map,卷积窗口的大小为 h ×k ,其中 h 表示纵向词语的个数,而 k 表示word vector的维数。通过这样一个大型的卷积窗口,将得到若干个列数为1的Feature Map。(熟悉NLP中N-GRAM模型的读者应该懂得这个意思)。
3、 池化层:
接下来的池化层,文中用了一种称为Max-over-timePooling的方法。这种方法就是简单地从之前一维的Feature Map中提出最大的值,文中解释最大值代表着最重要的信号。可以看出,这种Pooling方式可以解决可变长度的句子输入问题(因为不管Feature Map中有多少个值,只需要提取其中的最大值)。最终池化层的输出为各个Feature Map的最大值们,即一个一维的向量。
4、 全连接+softmax层:
池化层的一维向量的输出通过全连接的方式,连接一个Softmax层,Softmax层可根据任务的需要设置(通常反映着最终类别上的概率分布)。
训练方案:
在倒数第二层的全连接部分上使用Dropout技术,Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了,它是防止模型过拟合的一种常用的trikc。同时对全连接层上的权值参数给予L2正则化的限制。这样做的好处是防止隐藏层单元自适应(或者对称),从而减轻过拟合的程度。
在样本处理上使用minibatch方式来降低一次模型拟合计算量,使用shuffle_batch的方式来降低各批次输入样本之间的相关性(在机器学习中,如果训练数据之间相关性很大,可能会让结果很差、泛化能力得不到训练、这时通常需要将训练数据打散,称之为shuffle_batch)。
论文作者也公布了自己的实现程序(下载戳这里),同时有一位同行对上述论文给出了解读并基于上述程序做了对比实验(论文解读戳这里)。本人上面的分析也是基于原始论文和解读,算是锦上添花吧。
实验流程及结果:
参考上述论文和源程序,本人对其在中文短文本分类问题上进行了实验。
实验要求:
Python环境
安装结巴分析的python版本
安装numpy、pandas等一系列科学计算相关库,windows下借助Anaconda进行安装比较方便
安装theano,这个参考各种安装、使用教程吧。
语料库:使用的是搜狗语料库,搜索SogouC.reduced可找到下载连接。
文本预处理:
使用jieba分词后将一些实词汉词提取出来,同时,由于CNN输入窗口的大小是一定的,对于长度小于N的句子,使用Pad with zeroes的方式,对于长度大于N的句子,将其切分为若干段长度小于等于N的句子。使用军事和教育两个题材的预料进行处理后,样本总数量大致在2W的样子。
训练调参:
模型结构与trikc均与原文一直,在处理word vector size时,采用原始论文采用的300时,效果不是太理想,将该参数调低,采用szie=50、size=100,最终效果还算可以。同时,feature_map的数量要比word vector size值大一些,以尽可能提取更为丰富的句子信息。
下面是训练过程中的一些结果:
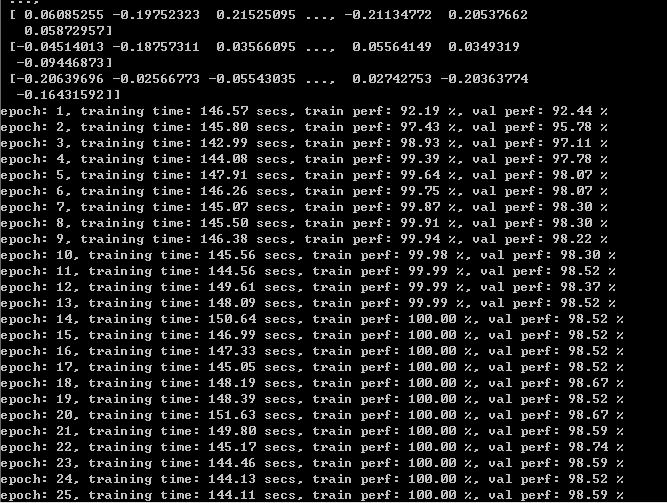
word vector size=50& feature_maps size = 100
来看看训练得到的wordvector在语义空间的映射效果如果,以该词对应的向量空间的余弦积的形式衡量词之间的相似性:
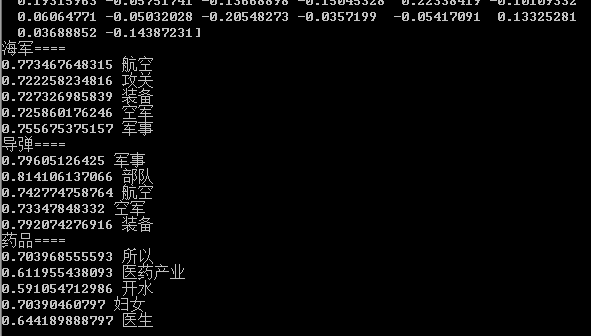
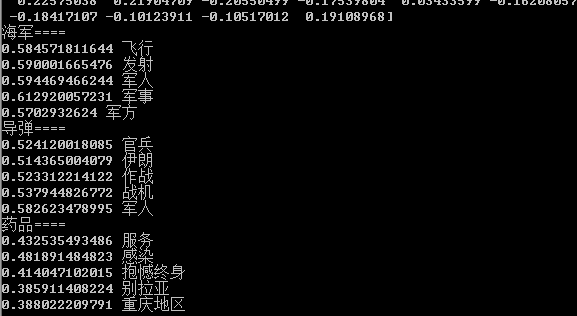
左:word vector size=50 & feature_maps size= 100 右:word vector size=100& feature_maps size = 100
军事题材类的词,语义表达的效果较好,而医疗卫生相关的则效果一般。如果原始预料集更大,可能效果还会进一步提升的。同时,也可以考虑使用word2vec模型训练得到word vector,在使用上述模型训练CNN分类模型,同时更新word vector。
本文同时在知加发表,欢迎围观。
最后,进过本人使用的实验代码可从github下载(Theano),对作者的原始代码做了比较详尽的注释,同时增加汉语的分词预处理模块和后面的word vector展现模块。
个人采用Tensorflow实现的版本:github (Tensorflow版本),欢迎一起交流学习~~~