本文参考6节课掌握python爬虫视频讲座
什么是爬虫
爬虫就是模拟客户端(浏览器)发送网络请求,获取响应,按照规则提取数据的程序。
环境搭建
浏览器的请求
浏览器中右键->检查,点击network,如下:

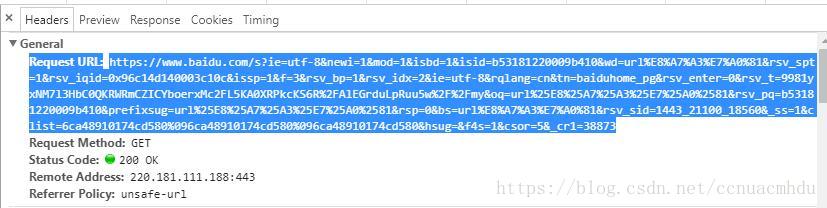
URL
上面的URL=请求的协议(https)+网站域名(www.baidu.com)+资源的路径+参数,可以在在线解码工具进行解码,如下:
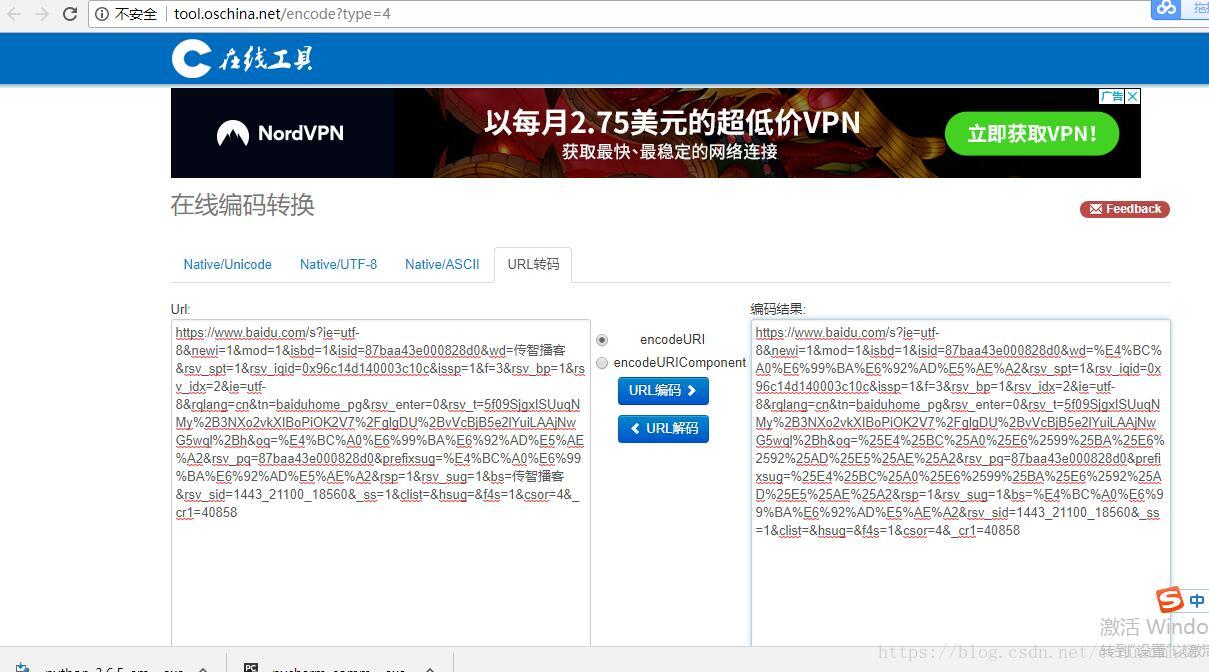
浏览器请求URL地址
浏览器请求URL对应的响应+js+css+图片(elements中的内容)
爬虫程序请求URL地址
elements的内容(包含js,css+图片)和爬虫获取到的URL地址的响应不同,爬虫中需要以当前URL地址对应的响应为准提取数据
当前URL地址对应的响应在哪?
方法一:从network中找到当前的URL地址,点击response
方法二:在页面上右键显示页面源码
两种方法的区别:一般两种方式查看的源码是一样的,但是对于网页更新比较快的网站,比如贴吧,两种方式显示源码不同,因为分别用这两种方法查看源码,这会花费一定时间,在这个时间段里,网页更新了!
认识HTTP、HTTPS
HTTP:超文本传输协议
以明文的形式传输,效率高,不安全
HTTPS:HTTP+SSL(安全套接字层)
传输之前数据先加密,之后解密获取内容,效率较低,但安全
get请求和post请求的区别
get请求没有请求体,post有,get请求把数据放在URL地址中
post请求常用于登录
post请求携带的数据量比get请求大,多,常用于传输大文本的时候
HTTP协议之请求
1、请求行
2、请求头
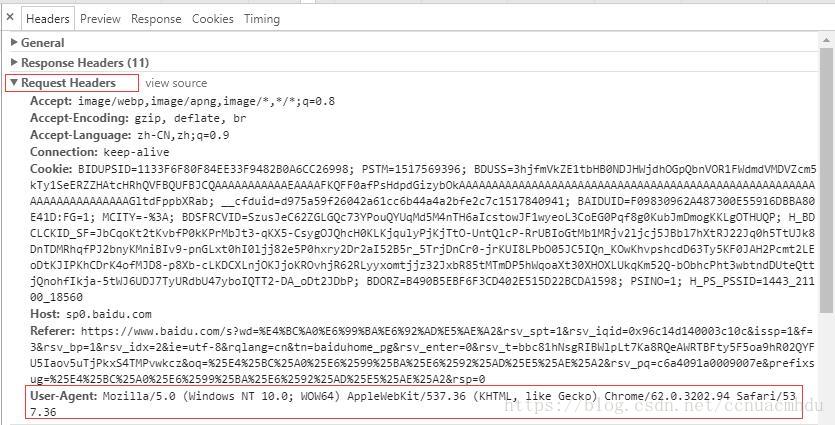
(1)User-Agent:对方浏览器能够通过这个User-Agent知道当前请求对方资源的是什么浏览器(是爬虫请求还是直接网请求,是手机版还是电脑版)
下面用电脑模拟手机请求:
注意这里的User-Agent和刚才不一样了:
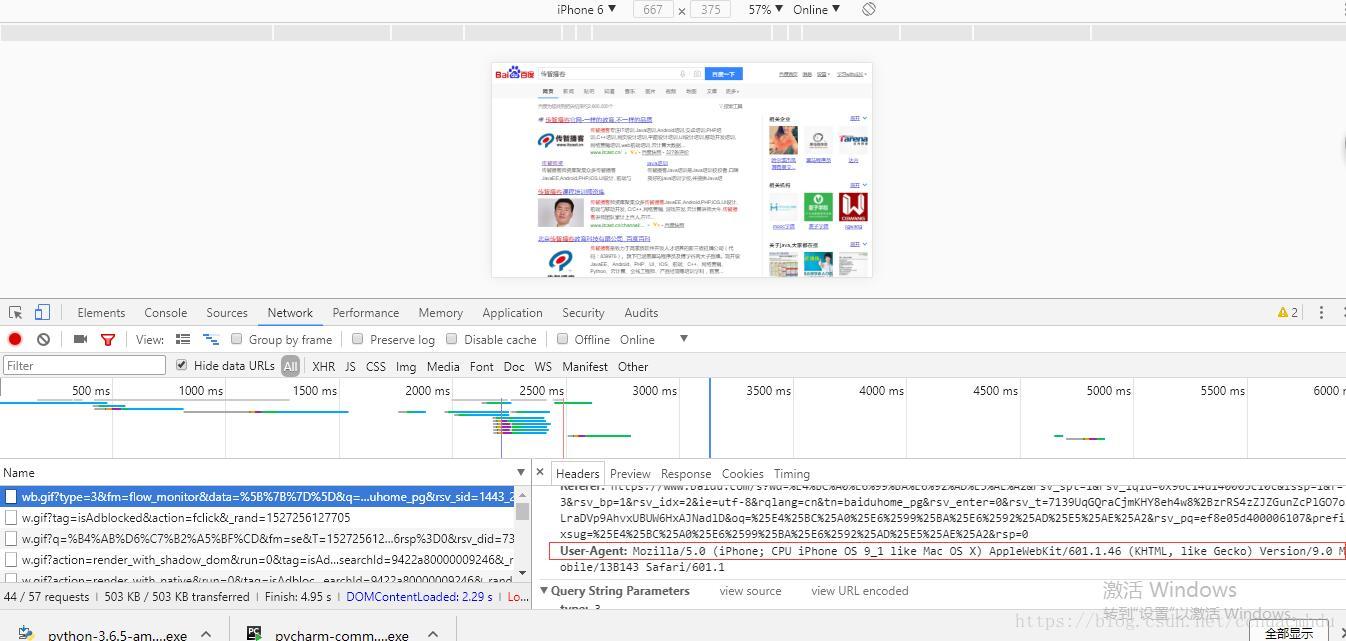
(2)Accept-Language:zh-CN,zh;q=0.9
这里表示更愿意接收哪些类数据,q对应接收这一类数据的愿意程度
(3)Cookie
(4)浏览器可以根据Cookie判断对方是不是爬虫
3、请求体(携带数据)
HTTP协议之响应
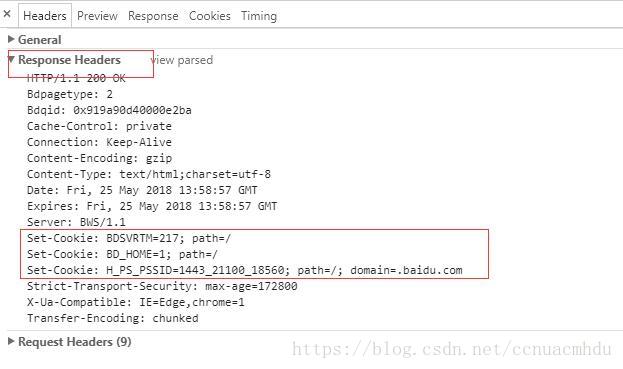
1、响应头
Set-Cookie:对方服务器通过该字段设置Cookie到本地(当然也能通过js设置)
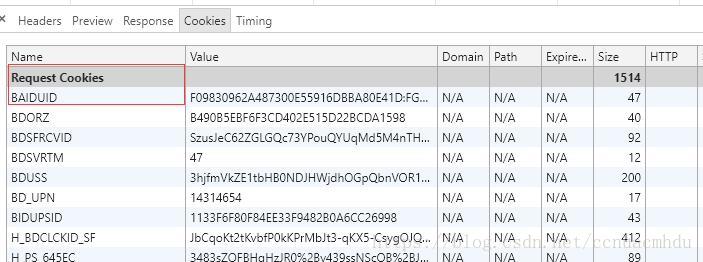
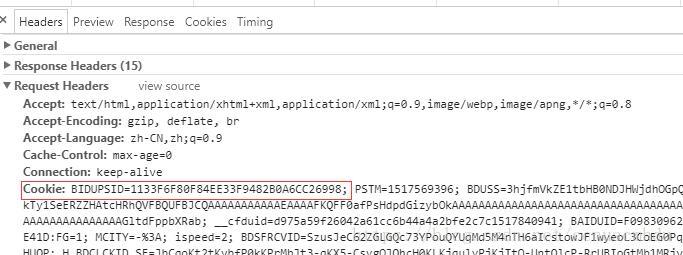
2、响应体
URL地址对应的响应
requests模块学习
准备:pip install requests
(pycharm导入这个包,file->setting->project)
发送get,post请求,获取响应
response=requests.get(url) #发送get请求,请求URL地址对应的响应
response=response.post(url,data={请求的字典})#发送post请求,请求URL地址对应的响应(需要请求体,下面图中的Form Data)以百度翻译为例,来进行请求
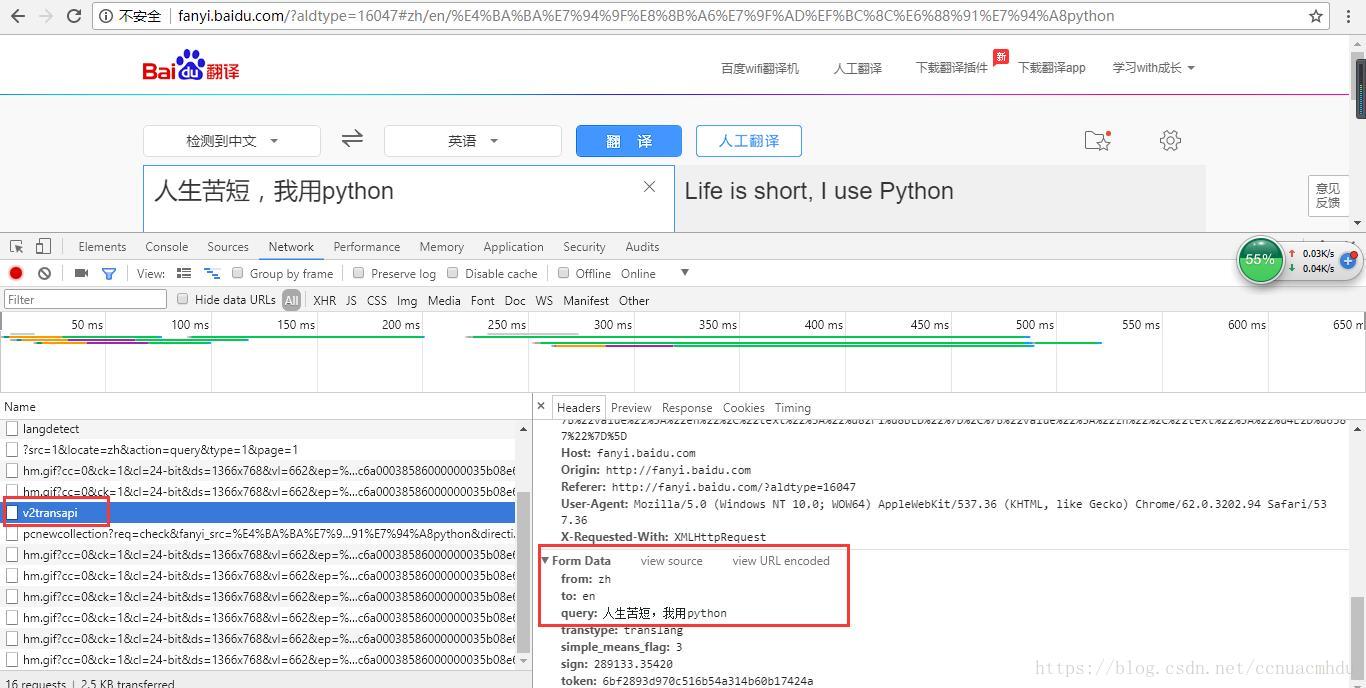
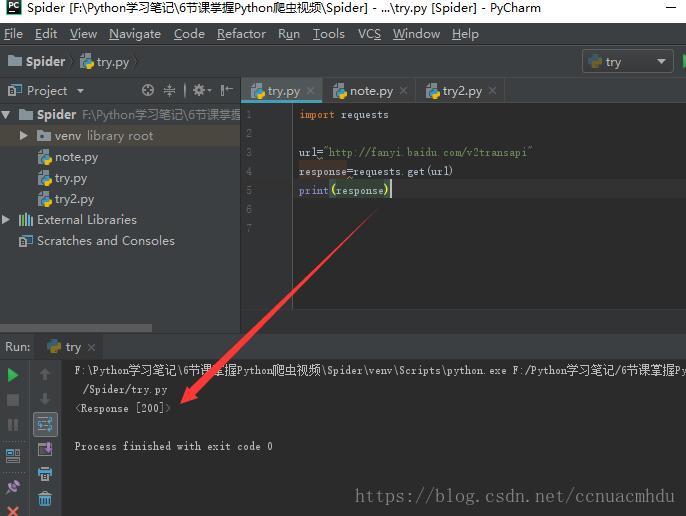
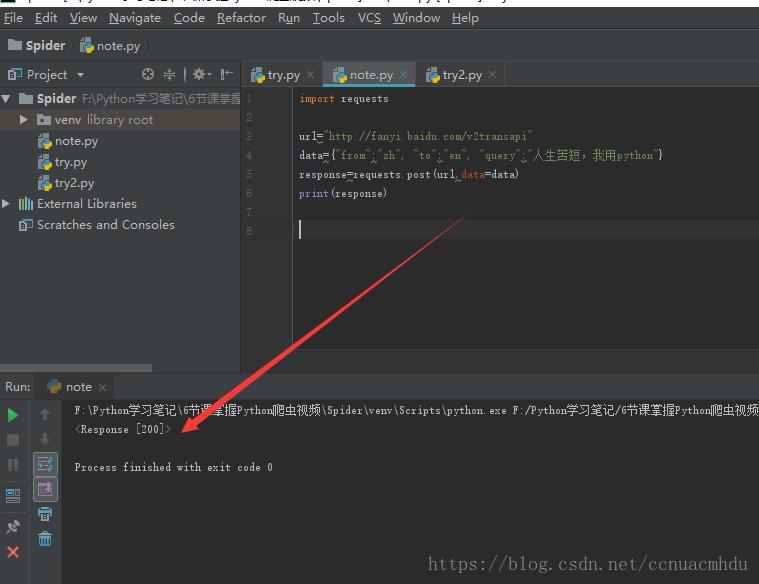
response的方法
response.text:该方式往往出现乱码,出现乱码使用response.encoding=”utf-8”
response.content.decode():把响应的二进制字节流转换为str类型
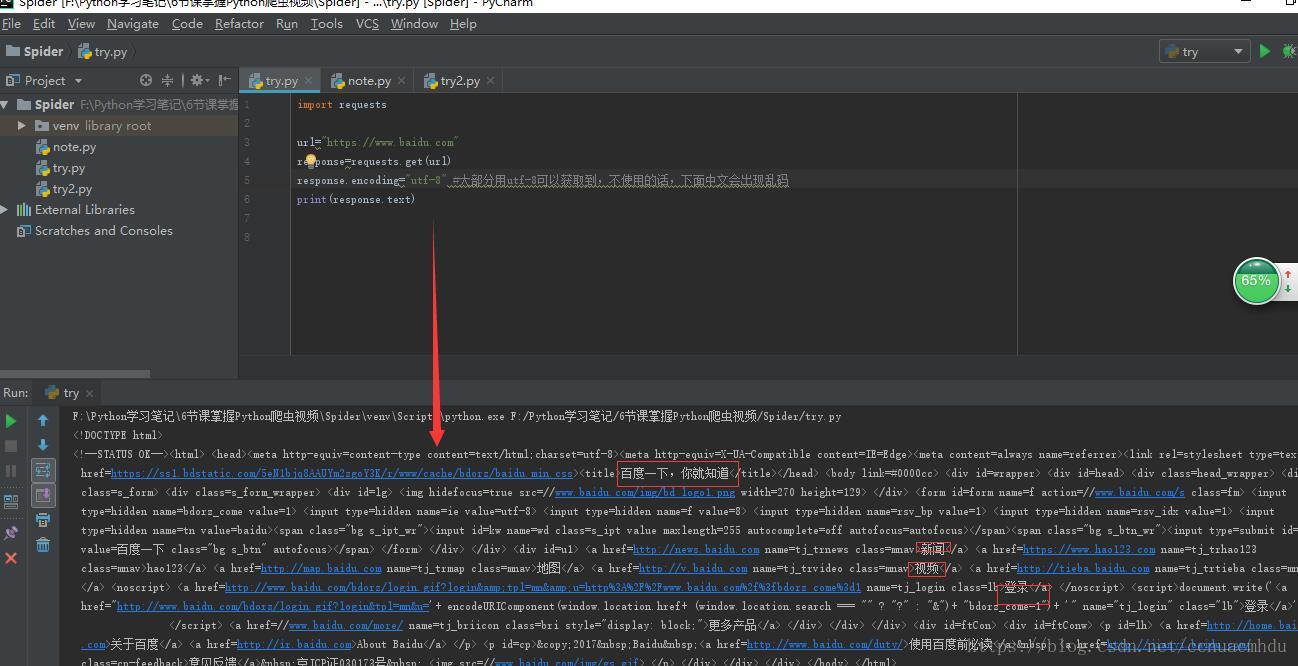
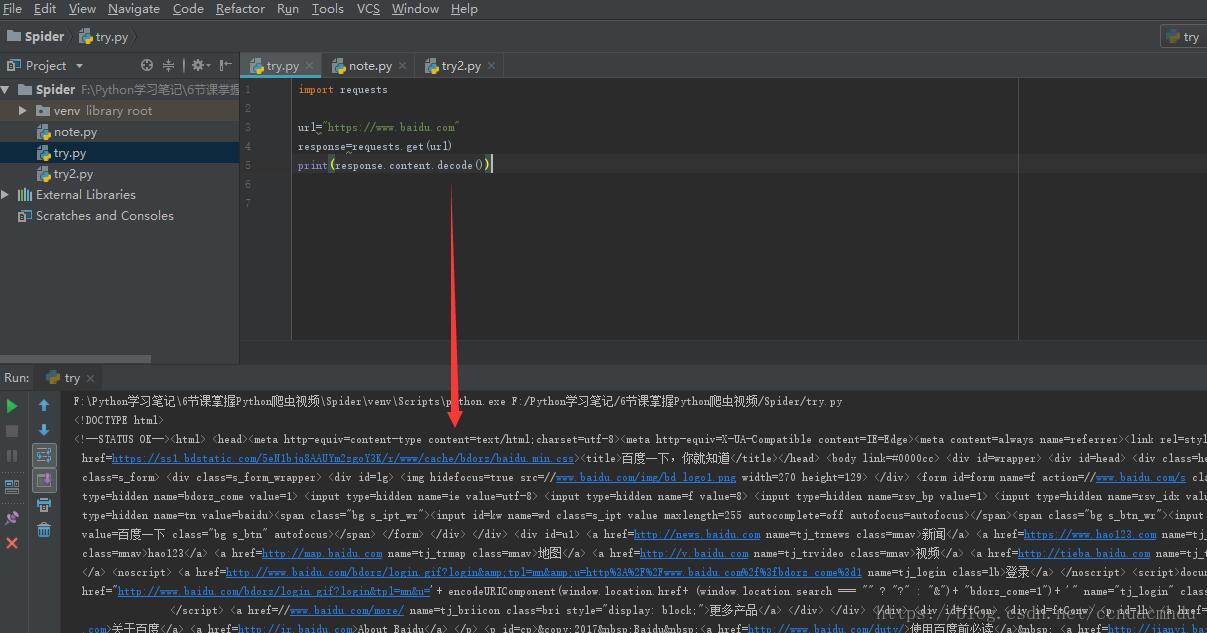
import requests
url="https://www.baidu.com"
response=requests.get(url)
print(response.request.url) #请求响应的地址,一般和请求地址一样,但如果页面发生了跳转则可能不一样
print(response.url) #请求的地址
print(response.request.headers) #类似上面
print(response.headers) #类似上面

获取网页源码的正确打开方式
下面三种方式总有一个可以获得网页正确解码的字符串
1.response.content.decode(),默认utf-8
2.response.content.decode(“gbk”)
3.response.text
发送带request的Headers请求
这里用的是手机版的页面
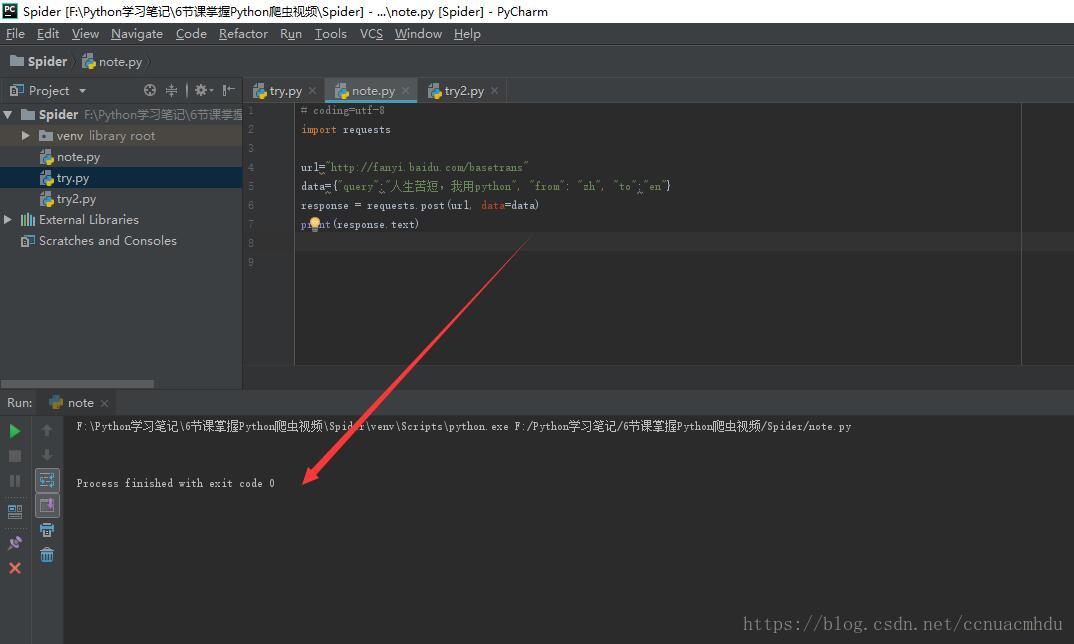
上图发现没有给出回应,可能对方服务器判断出来是一个爬虫,这时,我们可以多带一些headers里面的键值对(爬虫尽可能去模仿浏览器发请求,大部分带上user-agent就可以了,如果不行,多带一些,再不行,把cookie也带上)
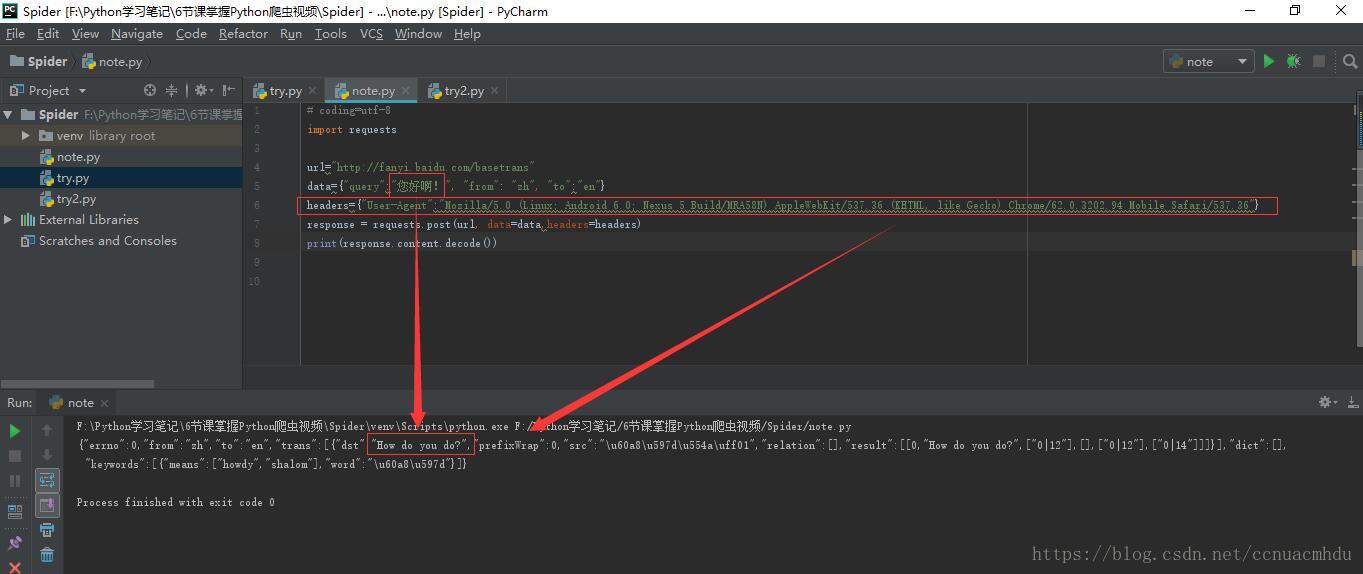
再比如,对百度首页进行爬取,下面的代码可以获取到的网页的源码很多(要比不带上headers的时候获取到的源码多得多)
import requests
url="https://www.baidu.com"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
response=requests.get(url,headers=headers)
print(response.content.decode())
retrying模块学习
先导入模块:pip install retrying
在pycharm中对应的工程中导入该模块
超时参数
requests.get(url,headers=headers,timeout=3)#3秒必须返回响应,否则报错# coding="utf-8"
import requests
from retrying import retry
headers={"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Mobile Safari/537.36"}
@retry(stop_max_attempt_number=3) #让这个函数最多执行3次,3次都请求不成功(有的网页不让访问,或比较卡),就返回None
def _parse_url(url):
print("*"*100) #用于检测如果请求三次都失败,则打印出三次
response = requests.get(url,headers=headers,timeout=5)
return response.content.decode()
def parse_url(url):
try:
html_str = _parse_url(url)
except:
html_str = None
return html_str
if __name__ == '__main__':
url="http://www.baidu.com"
"""
url="www.baidu.com"
#如果把地址换成这个,没有带协议,那么星花会被打印三次,并且下面这行代码应该改成print(parse_url(url)),不能取前100了,因为请求不成功返回的是None
"""
print(parse_url(url)[:100])带有Cookie的请求
(1)放在headers里面
import requests
url="https://www.baidu.com/"
#把Cookie放在headers里面
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Cookie":"BIDUPSID=1133F6F80F84EE33F9482B0A6CC26998; PSTM=1517569396; BDUSS=3hjfmVkZE1tbHB0NDJHWjdhOGpQbnVOR1FWdmdVMDVZcm5kTy1SeERZZHAtcHRhQVFBQUFBJCQAAAAAAAAAAAEAAAAFKQFF0afPsHdpdGizybOkAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGltdFppbXRab; __cfduid=d975a59f26042a61cc6b44a4a2bfe2c7c1517840941; BAIDUID=F09830962A487300E55916DBBA80E41D:FG=1; ispeed=2; MCITY=-218%3A; ispeed_lsm=0; H_PS_645EC=feb3eTciyAjU3x2%2Fqm00GcXEu2JCsrDAQP2gNM4Y9jsp9WKkSjxTekYk8dMvj1TraU9a; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BD_HOME=1; H_PS_PSSID=1443_21100_18560; BD_UPN=12314753; sug=3; sugstore=1; ORIGIN=0; bdime=0"}
response=requests.get(url,headers=headers)
#在当前目录下建立或查找文件1.html,想其中写入爬取到的信息
with open("1.html","w",encoding="utf-8") as f:
f.write(response.content.decode())(2)单独传Cookie
import requests
url="https://www.baidu.com/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
cookie="BIDUPSID=1133F6F80F84EE33F9482B0A6CC26998; PSTM=1517569396; BDUSS=3hjfmVkZE1tbHB0NDJHWjdhOGpQbnVOR1FWdmdVMDVZcm5kTy1SeERZZHAtcHRhQVFBQUFBJCQAAAAAAAAAAAEAAAAFKQFF0afPsHdpdGizybOkAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGltdFppbXRab; __cfduid=d975a59f26042a61cc6b44a4a2bfe2c7c1517840941; BAIDUID=F09830962A487300E55916DBBA80E41D:FG=1; ispeed=2; MCITY=-218%3A; ispeed_lsm=0; H_PS_645EC=feb3eTciyAjU3x2%2Fqm00GcXEu2JCsrDAQP2gNM4Y9jsp9WKkSjxTekYk8dMvj1TraU9a; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BD_HOME=1; H_PS_PSSID=1443_21100_18560; BD_UPN=12314753; sug=3; sugstore=1; ORIGIN=0; bdime=0"
#对cookie进行切割,转换为字典
cookie_dict={i.split("=")[0]:i.split("=")[-1] for i in cookie.split("; ")}
#print(cookie_dict)
response=requests.get(url,headers=headers,cookies=cookie_dict)#Cookie单独作为参数传进去
#在当前目录下建立或查找文件1.html,想其中写入爬取到的信息
with open("1.html","w",encoding="utf-8") as f:
f.write(response.content.decode())(3)
import requests
url="url"#这个url不知如何获得,去network中抓包?
headers={"User-Agent":"User-Agent"}
data={"username":"username","password":"password"}
session=requests.session()#session的方法与requests的方法一样
session.post(url,headers=headers,data=data)#服务器设置在本地的Cookie存到session里面
url="url"
response=session.get(url,headers=headers,data=data)#这会带上之前保存在session中的Cookie
#在当前目录下建立或查找文件1.html,想其中写入爬取到的信息
with open("1.html","w",encoding="utf-8") as f:
f.write(response.content.decode())