版权声明:所有资料资源均应用作教育用途,请勿用作商业用途 https://blog.csdn.net/qq_38876114/article/details/86622871
爬虫
python爬虫识一个对于网络资源进行批处理的程序,比方说,现在我想要看汽车之家的最新新闻的合集,或者说我自己做了一个程序,想要临时扩充一下目前的资讯库,需要转载其他人的文章,手动的转赞无疑是非常慢的,这里就可以用到爬虫,下面给出一个小例子来说明一下爬虫的基本工作原理
基本需求
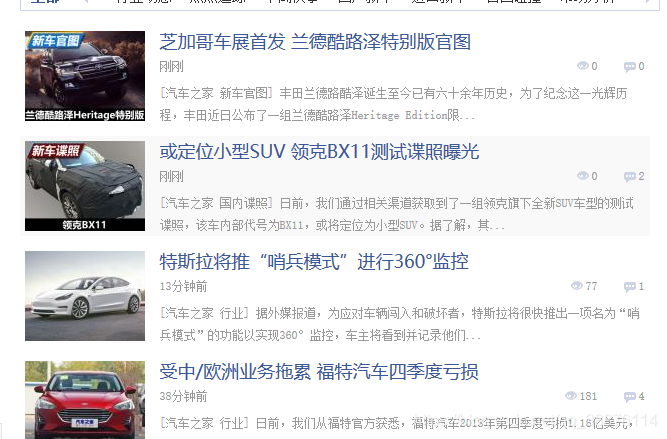
https://www.autohome.com.cn/news/ 对于这个网站,我想要他新闻的标题,链接,图片等等信息
操作
针对上述的问题,我应该怎样操作呢,首先,应该需要获取当前这个网页,然后分析这个网页,提取网页中的信息,查看网页的源码可以看到如下的界面
 我们当然可以通过写一个正则表达式,将这个网页的源码保存为字符串,然后进行正则匹配来得到任意部分的字符串,但是这样肯定不会很简单,并且python强大的工具包早就编写好了相应的工具,这里主要介绍两个包,requests包和beautifulSoup包,安装方法:
我们当然可以通过写一个正则表达式,将这个网页的源码保存为字符串,然后进行正则匹配来得到任意部分的字符串,但是这样肯定不会很简单,并且python强大的工具包早就编写好了相应的工具,这里主要介绍两个包,requests包和beautifulSoup包,安装方法:
pip install requests
pip3 install beautifulsoup4
requests包的功能是发送相应的网络请求,包括常见的get命令等等,可以将某个网页的源代码请求至本地,可以让用户以不同的编码,字符串或者二进制的方式查看
beautifulsoup包主要负责网页源代码的处理,上述得到的源代码是字符串或者流的形式,不适合用高级语言直接处理,python中更好处理的是对象,因此,beautifulsoup模块可以将一个网页源代码转换成为对象的格式,对象包含一些常用方法比如查找,获取属性等等,并且遵循网页的标签化的组织形式,类似于一个树,根节点是网页的根标签,其余节点以子节点的方式组织。
下面利用上述两个包来实现一个非常简单的爬虫来大概理解一下
实现
import requests
from bs4 import BeautifulSoup
#使用requests包中的get方法获得网页的源代码,设置编码格式
response = requests.get(url='http://www.autohome.com.cn/news/')
response.encoding = 'gbk'
#将得到的源代码利用下面的实例化方法转换为树状的对象树,每一个对象代表一个
#html标签,标签可以搜索到子标签
root = BeautifulSoup(response.text,features='html.parser')
#针对上述根节点搜索其标签id=auto-channel-lazyload-article的子节点,如上面源代码图所示
div = root.find(id='auto-channel-lazyload-article')
#得到的div标签下有多个li标签,利用findall方法返回一个对象列表
li_list = div.find_all('li')
#遍历这个对象列表,对每一个li标签进行处理
for li in li_list:
#获得li标签下的a标签
a = li.find('a')
if a:
#a.attrs可以获得a标签的属性字典,依次获得h3标签(标题),img标签(配图)
#需要注意,每个find返回的都是以对象形式存储的标签,可以调用attrs,text,,id,分别获得标签的属性,文本,名称
#(标签相关的规则在xml的基本格式说明中)
print(a.attrs.get('href'))
h3 = a.find('h3')
print(h3.text)
img = a.find('img')
print(img.attrs.get('src'))
#这里我们还可以直接将图片下载下来,向图片链接发送请求获得图片的数据流,写入本地即可
img_res = requests.get(url = 'http:' + img.attrs.get('src'))
img_file_name = h3.text + '.jpg'
with open(img_file_name,'wb') as img_file:
img_file.write(img_res.content)