什么是Python3网络爬虫?
定义:
网络爬虫(Web Spider),又被称为网页蜘蛛,是一种按照一定的规则,自动地抓取网站信息的程序或者脚本。
简介:
网络蜘蛛是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从 网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
爬虫流程:
①先由urllib的request打开Url得到网页html文档
②浏览器打开网页源代码分析元素节点
③通过Beautiful Soup或则正则表达式提取想要的数据
④存储数据到本地磁盘或数据库(抓取,分析,存储)
网络爬虫的第一步就是根据URL,获取网页的HTML信息。在Python3中,可以使用urllib.request和requests进行网页爬取。
- urllib库是python内置的,无需我们额外安装,只要安装了Python就可以使用这个库。
- requests库是第三方库,需要我们自己安装。
requests库强大好用,所以本文使用requests库获取网页的HTML信息。requests库的github地址:https://github.com/requests/requests
(1) requests安装
在cmd中,使用如下指令安装requests:
pip install requests
1
或者:
easy_install requests
1(2) 简单实例
requests库的基础方法如下:
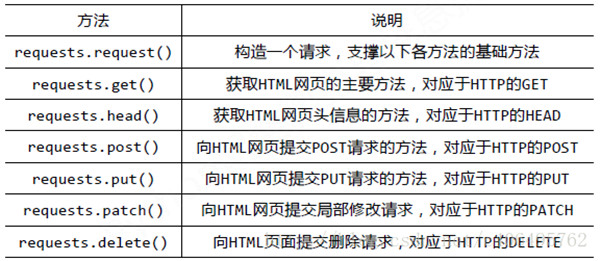
requests中文文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
requests库的开发者为我们提供了详细的中文教程,查询起来很方便。本文不会对其所有内容进行讲解,摘取其部分使用到的内容,进行实战说明。
首先,让我们看下requests.get()方法,它用于向服务器发起GET请求,不了解GET请求没有关系。我们可以这样理解:get的中文意思是得到、抓住,那这个requests.get()方法就是从服务器得到、抓住数据,也就是获取数据。让我们看一个例子(以 www.gitbook.cn为例)来加深理解:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://gitbook.cn/'
req = requests.get(url=target)
print(req.text)
requests.get()方法必须设置的一个参数就是url,因为我们得告诉GET请求,我们的目标是谁,我们要获取谁的信息。运行程序看下结果:
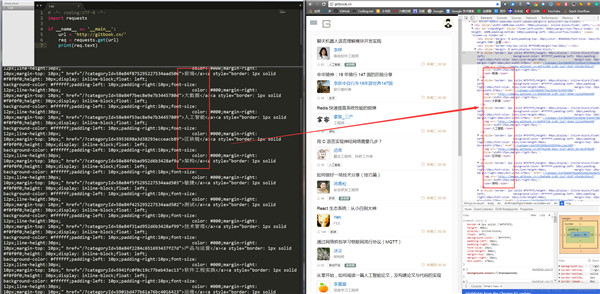
左侧是我们程序获得的结果,右侧是我们在www.gitbook.cn网站审查元素获得的信息。我们可以看到,我们已经顺利获得了该网页的HTML信息。这就是一个最简单的爬虫实例