论文链接:Path-Level Network Transformation for Efficient Architecture Search
架构搜索

根据一个已有的效果比较好的神经网络结构,找到更好的结构,例如将其中的某一层进行替换,增添一层或者减少一层,改变网络的拓扑结构。
为什么要基于已有的网络?
因为在已有的神经网络上更改拓扑结构可以利用已经训练好的权重,在巨人的肩膀上进步,为了更快的得到更好的结果。
什么是Path-Level?
链式结构如上图,我们称之为Layer-Level
Path-Level如下图:
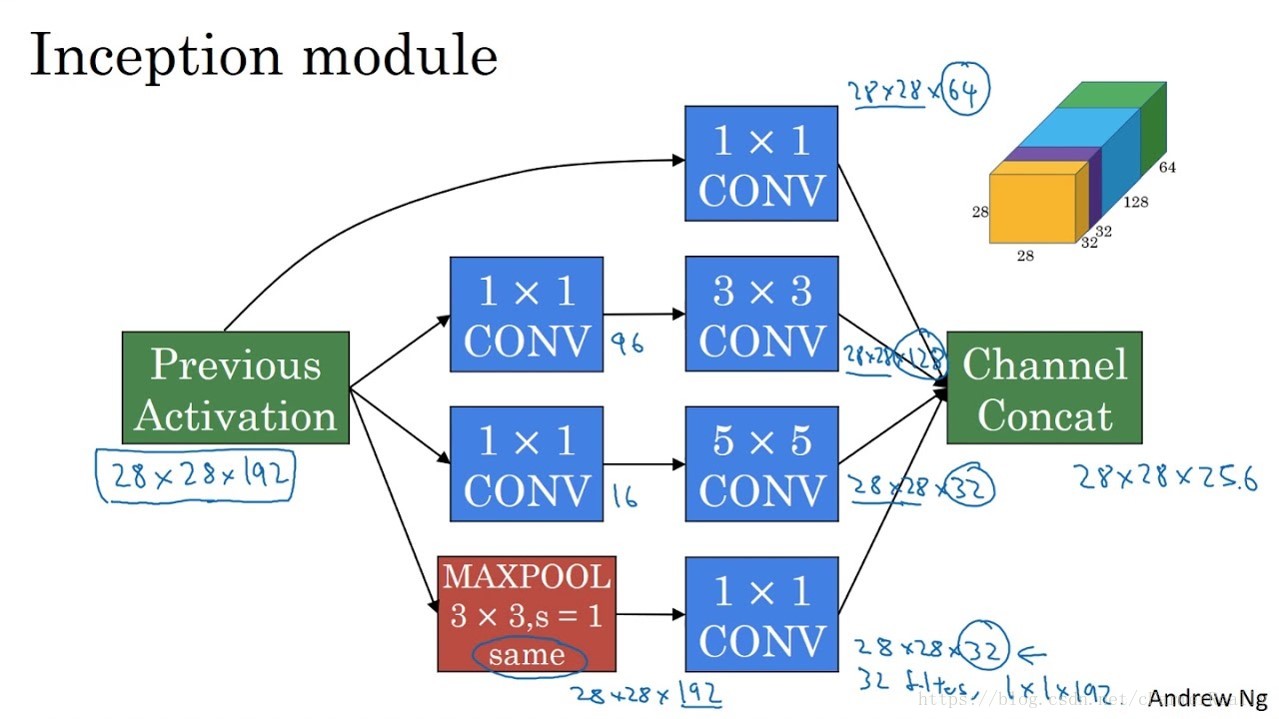
Layer-Level的架构搜索
给定一个层的候选集(例如:卷积层3*3,卷积层1*1,池化层,identity),从候选集中选择一个层进行替换。
identity指的是x->x,什么都不做。
如何选择?
1. 暴力搜索:遍历每一种可能的选择通过训练后测试结果反馈来选择结果最好的网络结构。
2. 随机搜索:随机选择一种层通过训练后测试结果反馈来选择结果最好的网络结构。
3. 强化学习:在暴力搜索和随机搜索的过程中,我们可能会发现当前层选择卷积层3*3,无论网络后面怎样选择,效果都比选择卷积层1*1和池化层效果好,那么我们此时就可以把这一层固定下来只使用卷积层3*3,但如果我们一直这么贪心选择的话,可能会错过一些即使当前不选择卷积层3*3也可能结果很好的机会,所以我们对此做一个折中,我们以x的概率选择随机搜索,以1-x的概率选择贪心搜索,这样我们搜索的效率就比暴力搜索和随机搜索好了很多。
4. 强化学习 + RNN:
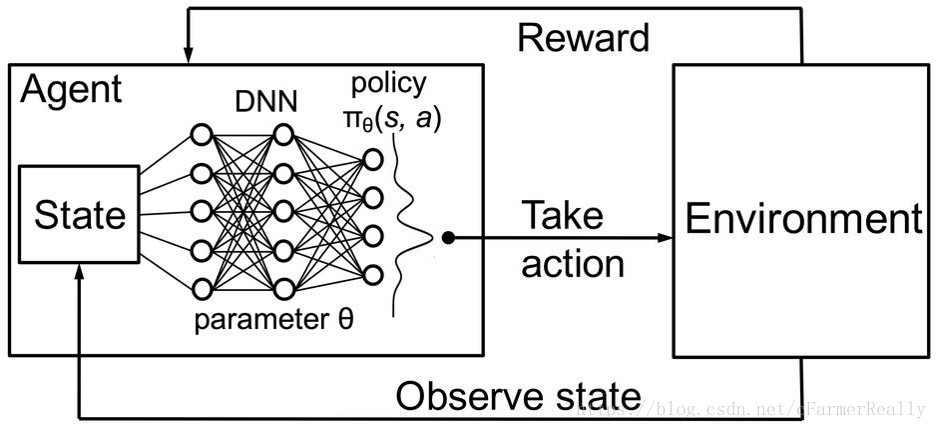
在前面三种搜索策略中,我们都是只考虑了当前的状态,那我们可以试图结合前几层或后几层一起对当前层做出决策,我们使用双向RNN来解决这个问题,每一个节点的输入是前一层的输出和前一层的激活函数返回值,
输出是当前层应该选择哪一层,但利用双向RNN解决架构搜索问题的过程中,我们发现没有label用来训练RNN,所以强化学习其实起到的是一个采样的作用,采样之后,RNN根据采样的每一层的选择和最后的结果一起来决定每一层选择不同选择的概率。
Path-Level的架构搜索
为什么要做Path-Level的架构搜索?
因为已经有一些Multi-Brach Neural Networks取得了很好效果,我们需要提供一种方法可以改变旧网络的拓扑结构,使得我们有机会生成表征能力更强的类似Inception models, ResNets这样优秀的网络或更好的网络。
定义如何拓宽网络 Net2WiderNet
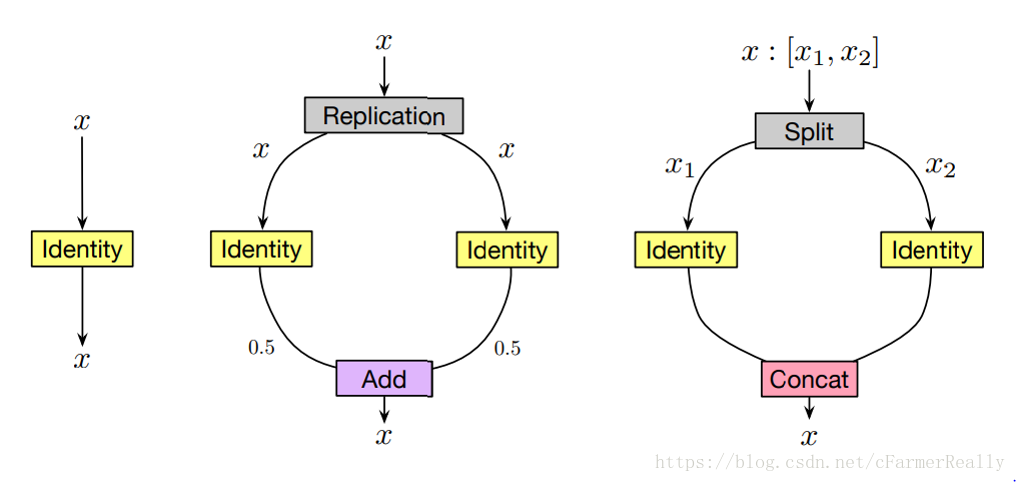
我们定义两种操作,Replication-Add和Split-Concat:
1. Replication-Add是指将x复制成2份,分别操作后把结果除以2再相加,保证输入和输出和之前的维度相同。
2. Split-Concat是指将x按照维度切成两份,分别操作后再把结果相接,保证输入和输出和之前的维度相同。
定义如何加深网络 Net2DeeperNet
利用Net2DeeperNet在当前层后面加一个identity层(实现细节可以看论文中的相关链接Net2Net)
定义Path-Level的架构搜索的数据结构
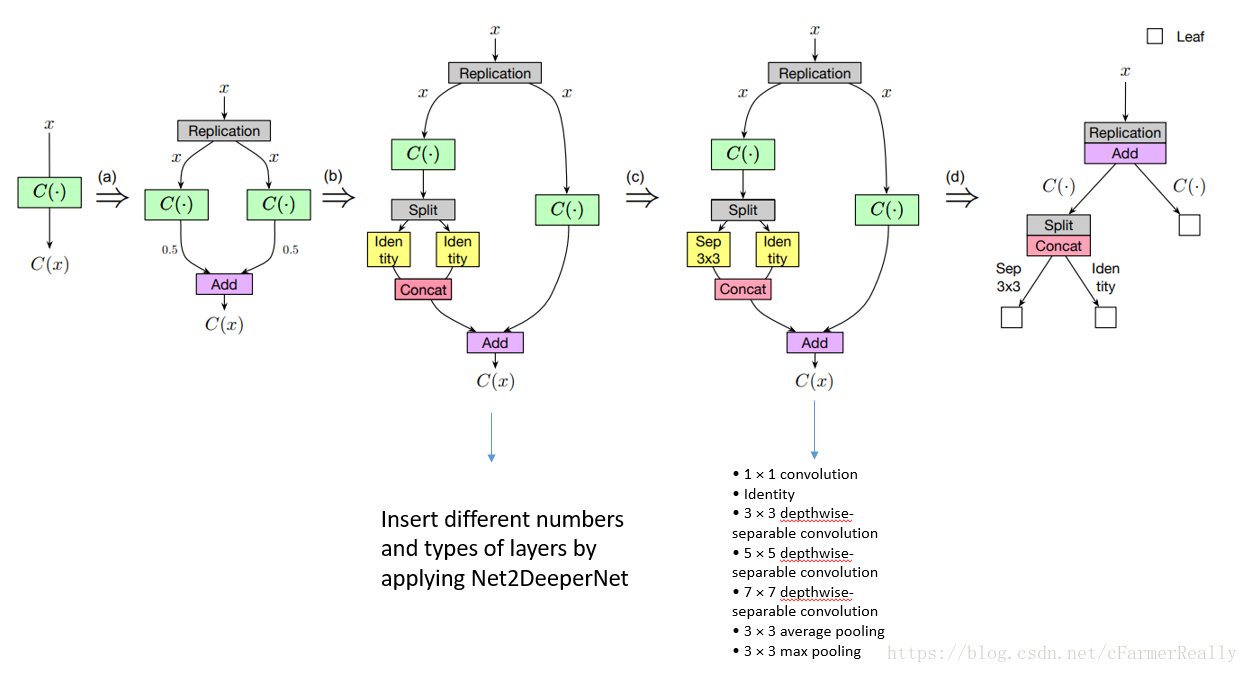
如图,a过程是Net2Wider的过程,b过程是Net2Deep后再Net2Wider的过程,c过程是对其中的层替换的过程,d过程是把c过程定义成了我们的树结构,我们定义我们的树结构中,节点:分配和合并策略,边:层
由此,我们可以把整个过程看做是一个在树上搜索的过程。
定义Path-Level的搜索策略
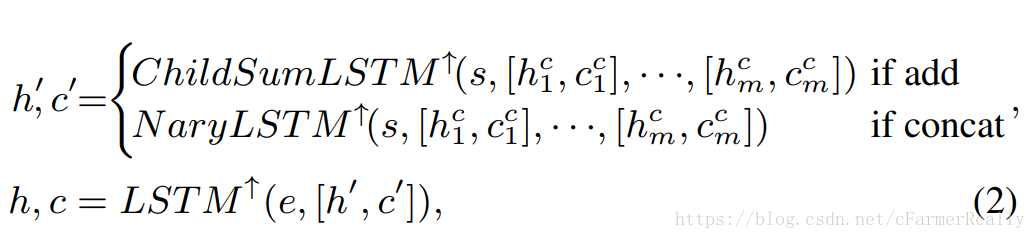
s表示分配和合并策略
e表示连个两个节点的边(i.e conv层)
h, c表示从边学到给节点的信息
h’, c’表示从节点学到给边的信息
类似于Layer-Level的思想,但我们利用lstm来决定用哪一层,用Tree-lstm来决定我们该使用什么分配合并策略,最终完成Layer-Level的搜索,我们不难发现Tree的结构是节点和边交替出现的,所以Tree-lstm的输入是前一个lstm的输出,Tree-lstm的输出是后一个lstm的输入。
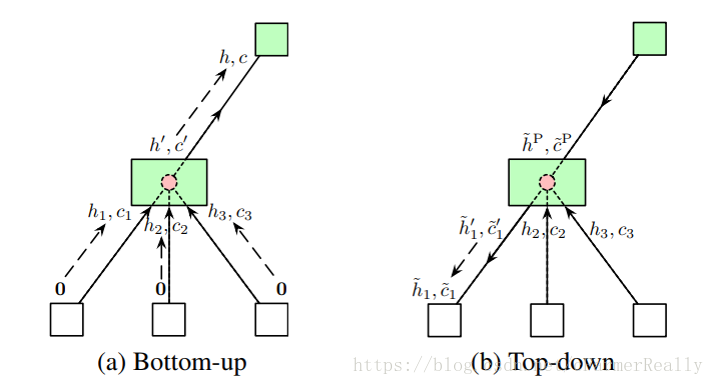
在搜索过程当中一共有三种情况:
1. 当前节点没有叶子节点时,我们考虑是否要把它利用Net2Deeper加深有一个叶子节点。
2. 当前节点只有一个叶子节点,我们考虑是否要把它扩宽并考虑扩多宽。
3. 考虑当前边应该是什么边(层)。
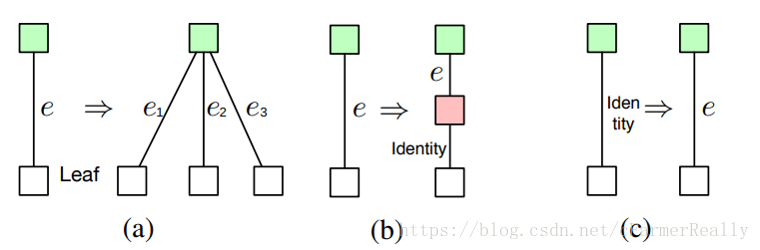
于是,利用如上操作,我们理论上可以生成任何网络结构。
例子
下面这个结构是论文的作者在实验cifar10时找到的一个结构
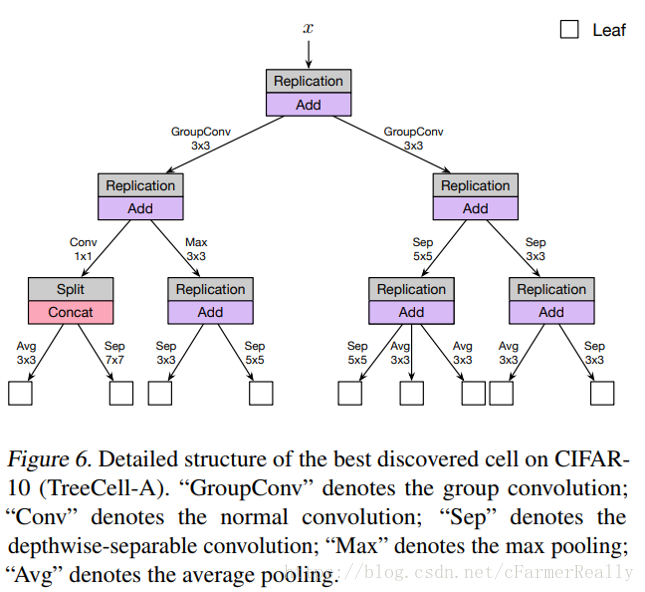
总结
- 这篇论文的实验效果显示和主流的架构搜索算法相比,效果相当但GPU机时大大减少。
- 计算力更小可能是因为Net2Net可以基于已经效果很好的网络去做, search的算法比较好可以更快的搜索到更好的结构。
- 效果相当可能是因为path-level可以生成multi-branch的网络结构表征能力更强所以效果也可以很好。
- 总的来说,这篇论文综合现有的比较主流的技术,提出了最终比较好的解决方案。
附
文中没有详细解读Net2Net,Tree-lstm以及Layer-Level中的算法的详细实现,我会在之后的文章中一一解读,并会在之后带来关于如何tune超参数的一些理解。