2.4. 编译和加载
介绍模块作者如何将源代码编译成能够装载到内核中的可执行模块。
2.4.1. 编译模块
首先,要看模块是如何构造的。模块的构造过程和用户空间应用程序的构造过程不同。内核是一个大的、独立的程序,为了将它的各个片段放在一起,要满足很多详细而明确的要求。和先前的内核版本相比,构造过程有所不同;新的构造系统使用起来更加简单,并可产生更加正确的结果,但看起来和先前的方法有很大的不同。
在构造内核模块之前,有一些先决条件首先应该得到满足。首先,应该确保具备正确版本的编译器、模块工具和其它必要的工具。在开始构造模块之前,需要查看该文件并确保已安装正确的工具。如果利用错误的工具版本来构造内核及其模块,将导致许多细微的、复杂的问题。还需注意,和使用老工具一样,使用太新的工具也偶尔会导致问题;内核源码对编译器作了大量假定,因此新的编译器版本可能导致问题的出现。
如果尚未准备内核树,或者尚未配置并构造内核,则应该首先完成这些工作。如果在自己的文件系统中没有2.6内核树,则无法构造可装载的模块。尽管并不是必需的,但最好运行和模块对应的内核。
在准备好这些之后,为自己的模块创建Makefile,则非常简单。对给出的hello world模块实例来说,下面一行代码就可以了:
obj-m := hello.o
上面这行并不是Makefile文件的常见形式。问题的答案是内核构造系统处理了其余的问题。上面的赋值语句说明了有一个模块需要从目标文件hell.o中构造,而从该目标文件中构造的模块名称为hello.ko。
如果要构造的模块名称为module.ko,并由两个源文件(file1.c和file2.c),则正确的Makefile可以如下编写(多个文件的模块编译):
obj-m := module.o
module-objs := file1.o file2.o
为了让这种类型的Makefile文件正常工作,必须在大的内核构造系统环境中调用它们。如果内核源码树保存在~/kernel-2.6 目录中,则用来构造模块的make命令是(在包含模块源代码和Makefile的目录中输入):
make -C ~/kernel-2.6 M='PWD' modules
这个命令首先改变目录到-C选项指定的位置(内核源码目录),其中保存有内核的顶层Makefile文件。M=选项让该Makefile在构造modules目标之前返回到模块源代码目录。然后,modules目标指向obj-m变量中设定的模块。
用下面的方法来编写Makefile:
ifeq ($(KERNELRELEASE),)
KERNELDIR ?= /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KERNELDIR) M=$(PWD) clean
else
obj-m := hello_world.o
endif
分析:
在一个典型的构造过程中,这个 Makefile要被读取 2 次,当Makefile从命令行调用时,它注意到 KERNELRELEASE 变量没有设置。注意到,已安装的模块目录中存在一个符号链接,指向内核的构造树,这个Makefile就可以定位内核的源代码目录。如果实际运行的内核并不是要构造的内核,可以在命令行提供KERNELDIR=选项或设置KERNELDIR环境变量,也可以修改用来设置KERNELDIR的行。在找到内核源码树后,这个Makefile调用all:目标,这个目标使用先前描述过的方法第二次运行make命令,以便运行内核构造系统。在第二次读取该Makefile文件时,KERNELRELEASE变量非空,它设置了obj-m,而内核的Makefile负责真正构造模块。
一个真正的Makefile应该包含通常用来清楚无用文件的目标、安装模块的目标等等。
2.4.2. 加载和卸载模块
构造模块之后,将模块装入内核。insmod完成这项工作,insmod程序将模块的代码和数据装入内核,然后使用内核的符号表解析模块中任何未解析的符号。与链接器ld不同,内核不会修改模块的磁盘文件,而仅仅修改内存中副本。insmod可以接受一些命令行选项,并且可以在模块链接到内核之前给模块中的整型和字符串型变量赋值。因此,一个良好设计的模块可以在装载时进行配置,这比编译时的配置为用户提供更多的灵活性,但有些情况下仍然要使用编译时的配置。
内核是如何支持insmod工作的,实际上它依赖于定义在kernel/module.c中的一个系统调用。函数sys_init_module给模块分配内核内存以便装载模块,然后,该系统调用将模块正文复制到内存区域,并通过内核符号表解析模块中的内核引用,最后调用模块的初始化函数。
asmlinkage long sys_init_module(void __user *umod, unsigned long len, const char __user *uargs)
{
struct module *mod;
int ret = 0;
/* Must have permission */
if (!capable(CAP_SYS_MODULE))
return -EPERM;
/* Only one module load at a time, please */
if (mutex_lock_interruptible(&module_mutex) != 0)
return -EINTR;
/* Do all the hard work */
mod = load_module(umod, len, uargs);
if (IS_ERR(mod)) {
mutex_unlock(&module_mutex);
return PTR_ERR(mod);
}
/* Now sew it into the lists. They won't access us, since
strong_try_module_get() will fail. */
stop_machine_run(__link_module, mod, NR_CPUS);
/* Drop lock so they can recurse */
mutex_unlock(&module_mutex);
blocking_notifier_call_chain(&module_notify_list,
MODULE_STATE_COMING, mod);
/* Start the module */
if (mod->init != NULL)
ret = mod->init();
if (ret < 0) {
/* Init routine failed: abort. Try to protect us from
buggy refcounters. */
mod->state = MODULE_STATE_GOING;
synchronize_sched();
if (mod->unsafe)
printk(KERN_ERR "%s: module is now stuck!\n", mod->name);
else {
module_put(mod);
mutex_lock(&module_mutex);
free_module(mod);
mutex_unlock(&module_mutex);
}
return ret;
}
/* Now it's a first class citizen! */
mutex_lock(&module_mutex);
mod->state = MODULE_STATE_LIVE;
/* Drop initial reference. */
module_put(mod);
unwind_remove_table(mod->unwind_info, 1);
module_free(mod, mod->module_init);
mod->module_init = NULL;
mod->init_size = 0;
mod->init_text_size = 0;
mutex_unlock(&module_mutex);
return 0;
}
总结:
有且只有系统调用的名字前带有sys_前缀,而其它任何函数都没有这个前缀。
需要进一步了解modprobe命令。modprobe和insmod类似,modprobe也用来将模块装载到内核中。和insmod的区别在于,modprobe会考虑要装载的模块是否引用了一些当前内核不存在的符号。如果有这类引用,modprobe会在当前模块搜索路径中查找定义了这些符号的其它模块。如果modprobe找到了这些模块(要装载的模块所依赖的模块),会同时将这些模块装载到内核。如果在这种情况下使用insmod,则该命令会失败,并在系统日志文件中记录“unresolved symbols(未解析的符号)”消息。
可以使用rmmod命令从内核中移除模块。注意:如果内核认为模块仍然在使用状态,或者内核被配置为禁止移除模块,则无法移除该模块。配置内核并使得内核在模块忙的时候仍然能强制移除模块也是可能的。
lsmod命令列出当前装载到内核中的所有模块,还提供其它一些信息,比如其它模块是不是在使用某个特定的模块等。
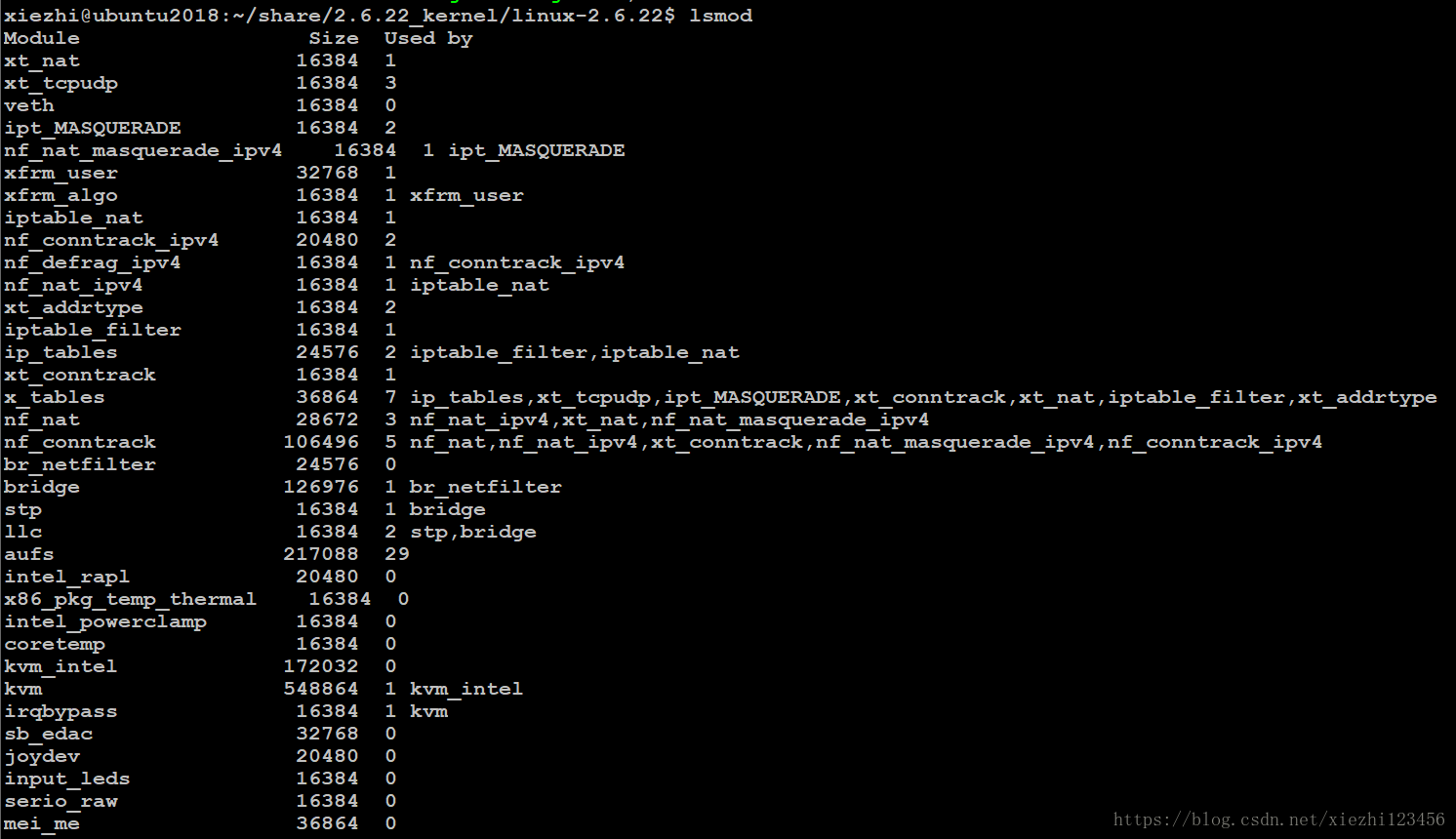
lsmod通过读取/proc/modules虚拟文件来获得这些信息。
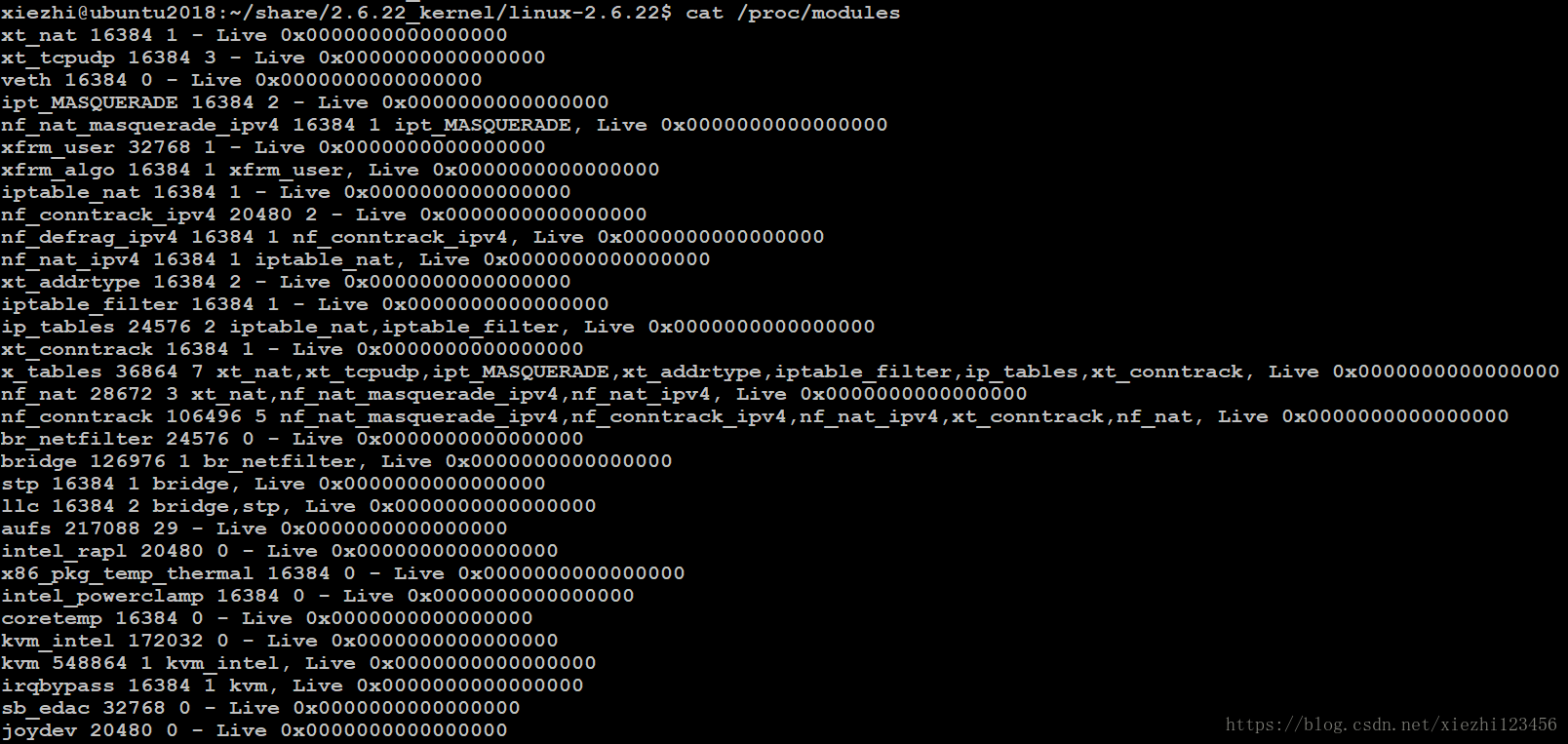
有关当前已装载模块的信息也可以在sysfs虚拟文件系统的/sys/module目录下找到。
test@ubuntu2018:/sys/module/8250$ ls
parameters uevent
test@ubuntu2018:/sys/module/8250/parameters$ ls -al
total 0
drwxr-xr-x 2 root root 0 Jul 4 16:59 .
drwxr-xr-x 3 root root 0 Jul 4 15:54 ..
-rw-r--r-- 1 root root 4096 Jul 4 17:00 nr_uarts
-r--r--r-- 1 root root 4096 Jul 4 17:00 probe_rsa
-rw-r--r-- 1 root root 4096 Jul 4 17:00 share_irqs
-rw-r--r-- 1 root root 4096 Jul 4 17:00 skip_txen_test
2.4.3. 版本依赖
要记住,在缺少modversions的情况下, 其模块代码必须针对要链接的每个版本的内核重新编译。模块和特定内核版本定义的数据结构和函数原型紧密关联,一个模块看到的接口可能从一个版本到另一个版本发生重大的变化。
内核不会假定一个给定的模块是针对正确的内核版本构造的。在构造过程中,可以将自己的模块和当前内核树中的一个文件链接;该目标文件包含了大量有关的内核信息,包括目标内核版本、编译器版本以及一些重要配置变量的设置。在视图装载模块时,这些信息可用来检查模块和正在运行的内核的兼容性。如果有任何不匹配,就不会装载该模块,同时可看到如下信息:
# sudo insmod hello.ko
Error inserting './hello.ko': -1 Invalid module format
查看系统日志文件,将看到导致模块装载失败的具体原因。
如果要为某个特定的内核版本编译模块,则需要该特定版本对应的构造系统和源代码树。修改Makefile中KERNELDIR变量可实现这个目的。
在不同的发布之前,内核接口经常会发生变化。如果打算编写一个能够和多个内核版本一起工作的模块,则必须使用宏以及#ifdef来构造并编译自己的代码。通过检查KERNEL_VERSION和 LINUX_VERSION_VODE而使用预处理条件,能够解决大部分基于内核版本的依赖性问题。不应该胡乱使用#ifdef条件语句将整个驱动代码变得杂乱无章。最好的一个方法是将所有相关的预处理条件语句集中放在一个特定的文件里。一般而言,依赖于特定版本(或平台)的代码应该隐藏在低层宏或者函数之后,之后,高层代码可直接调用这些函数,而无需关注低层细节。用这种方式编写的代码便于阅读,同时更为健壮。
2.4.4. 平台依赖
每种计算机平台都有自己的独特特性,内核设计者可以充分利用这些特性来达到目标平台上目标文件最有性能。对于应用程序开发人员,必须将程序代码和预编译过的库链接并且遵循参数传递规则。而内核开发者则不同,根据不同需求将某些寄存器指定为特定用途。而且内核代码可以针对某个CPU家族的某种特定处理器进行优化,从而充分利用目标平台的特性。和应用程序以二进制形式的发布不同,内核需要发布源代码,针对目标平台定制编译后才能达到对某个特定计算机集合的优化。
例如,x86架构可划分为几个不同的处理器类型。老的80386处理器仍然被支持着,尽管从现代标准来讲,它的指令集相对受限。这种架构上更为现代的处理器已经引入了大量新的能力,包括进入内核的更快指令、进程间锁定指令、数据复制指令等等。更新的处理器使用正确的模式还能够处理36位或者更大的物理地址,从而允许处理器寻址高于4GB的物理内存。其它处理器家族也存在类似的增强。根据不同的配置选项,内核可以使用这些附加的功能。
如果模块和某个给定内核工作,它也必须和内核一样了解目标处理器。这样vermagic.o可再次帮助我们。在装载模块时,内核会检查处理器相关的配置选项以便确保模块匹配于运行中的内核。如果模块在不同选项下编译,则不会装载该模块。
如果打算编写一个驱动程序用于一般性的发布,则最好考虑好如何支持可能不同处理器变种。最好的办法是用GPL兼容许可证来发布自己的驱动程序,并将其贡献给内核主分支。如果不打算这么做,以源代码形式以及一组用于编译的脚本发布自己的驱动程序是最好的办法。许多供应商已发布了一些工具使得这个工作变得更加容易。如果必须以二进制方式发布自己的驱动程序,则需要检查目标发行版提供不同的内核,并为每个内核提供模块的一个版本。作为常规,以源代码形式发布自己的作品是最容易被其他人接受的方式。