一、思维理解
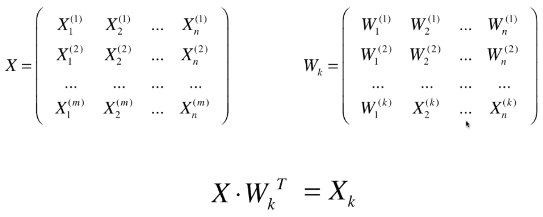
- X:原始数据集;
- Wk:原始数据集 X 的前 K 个主成分;
- Xk:n 维的原始数据降维到 k 维后的数据集;
- 将原始数据集降维,就是将数据集中的每一个样本降维:X(i) . WkT = Xk(i);
- 在人脸识别中,X 中的每一行(一个样本)就是一张人脸信息;
- 思维:其实 Wk 也有 n 列,如果将 Wk 的每一行看做一个样本,则第一行代表的样本为最重要的样本,因为它最能反映 X 中数据的分布,第二行为次重要的样本;在人脸识别中,X 中的每一行是一个人脸的图像,则 Wk 的每一行也可以理解为一个人脸图像,Wk 中的每一行代表的人脸图像就是特征脸。
- 之所以称 Wk 的每一行代表的人脸图像为特征脸,因为每一个特征脸对应一个主成分,它相当于表达了原始数据 X 中人脸数据所对应的特征。
二、特征脸
1)人脸数据集
- 获取
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import fetch_lfw_people faces = fetch_lfw_people() faces.keys() # 输出:dict_keys(['data', 'images', 'target', 'target_names', 'DESCR']) faces.data.shape # 输出:(3882, 2914) faces.images.shape # 输出:(3882, 62, 47)
- fetcg_lfw_people:在 sklearn 中的封装的人脸识别数据集;
- faces:字典类型,其中 “target_names” 为每一个人脸样本对应的真实的人的姓名;
- (3882, 2914):数据集中共有 3882 张人脸,每张人脸有 2914 个特征;
- (3882, 62, 47):其中 62 * 47 = 2914,表示每张人脸都是 62 X 47 像素的图片;
- 从数据集 faces 中随机去除 36 张人脸样本,并绘制
-
随机抽取
# 对数据集faces.data 做乱序处理 random_indexes = np.random.permutation(len(faces.data)) X = faces.data[random_indexes] example_faces = X[:36] example_faces.shape # 输出:(36, 2914)
-
绘制 n * n 张子图
def plot_faces(faces): fig, axes = plt.subplots(6, 6, figsize=(10, 10), subplot_kw={'xticks':[], 'yticks':[]}, gridspec_kw=dict(hspace=0.1, wspace=0.1)) for i, ax in enumerate(axes.flat): ax.imshow(faces[i].reshape(62, 47), cmap='bone') plt.show() plot_faces(example_faces)

2)特征脸
- faces.data 的所有主成分
from sklearn.decomposition import PCA # svd_solver='randomized':表示随机求取 pca,因为数据量较大,使用随机方式求解快些 # 此处没有指定 n_components,要求取所有主成分 pca = PCA(svd_solver='randomized') pca.fit(X) pca.components_.shape # 输出:(2914, 2914)
- svd_solver='randomized':表示随机求取 pca,使用随机方式求解速度更快;
- 绘制前 36 个特征脸
plot_faces(pca.components_[:36,:])

- 现象:排在前面的特征脸看上去相等笼统,从前到后,人脸样子越来越清晰;
- 要点一:通过特征脸,可以直观的看出在人脸识别的过程中,我们是怎么看到每一张人脸相应的特征的;
- 要点二:每一个人脸都是所有特征脸的线性组合,二特征脸依据重要程度,顺次的排列;
- 其它
faces2 = fetch_lfw_people(min_faces_per_person=50)
-
min_faces_per_person=30:数据集 fetch_lfw_people 中,同一个人名(target_names中的人名)至少用 30 个人脸图像,将这部分图像提取出来;