简介:基于PCA的人脸识别算法,也叫基于特征脸的人脸识别算法。
它将人脸识别过程作为一个分类问题进行数学建模,其核心思想是将单张人脸图像看作是一个向量,由此对所有训练集图像进行主成分分析,形成一个投影矩阵,利用这个矩阵可以将训练集和测试集图像向低维投影,使每个图像都得到一个低维向量的表达。这个对于测试集的每一个图像的低维向量表达,可以找到其在训练集当中能够的最近邻低维向量对应的人脸图像,这个人脸图像就是人脸识别的结果
步骤 :
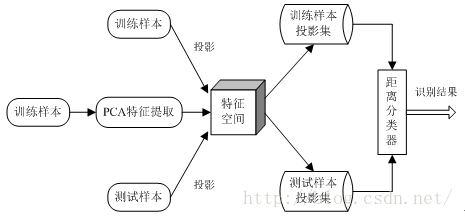
步骤:训练样本、特征提取、构造特征空间、投影计算
原理:通过消除数据的相关性,找到一个空间,使得各个类别的数据在该空间上能够很好地分离
把一个人脸图片看做一个特征向量,80*80的图片就是6400维的向量。特征脸就相当于是一个模版,以特征脸和原图做个点乘得到一个特征值。如果人脸的特征维度d很大,例如256x256的人脸图像,d就是65536了。那么协方差矩阵C的维度就是dxd=65536x65536。对这个大矩阵求解特征值分解是很费力的。那怎么办呢?如果人脸的样本不多,也就是N不大的话,我们可以通过求解C′=ΦTΦC′=ΦTΦ矩阵来获得同样的特征向量。可以看到这个C′=ΦTΦC′=ΦTΦ只有NxN的大小


假设在图像集合f(m,n)中,每张图像可以用堆叠的方式表示成一个维列向量:
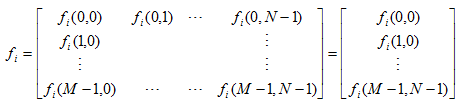
其表示方法为:从图像矩阵的第一列开始取,依次取到最后一列,每一列首尾相连,构成一个维列向量。将每一幅人脸图像表示
列向量以后,然后依次将每一个图像列向量转置成行向量,构成一个人脸样本矩阵,该样本矩阵即图像集合:

由式(2)可知样本矩阵有L行,其中每一行的数据就代表一张人脸样本图像,L表示训练样本的总个数。
训练样本的协方差矩阵为:
式中mf是所有训练样本的平均值向量,也即是所有样本的平均脸。(3)式中的[Cf]阵为阶实对称方阵,则其一定存在个相互正交的属于各个特征值的特征向量,即有:

将上述特征值进行降序排列,并取每个特征值对应的特征向量构成一个正交矩阵,也即是一个维的正交空间。按照文献中的说明,此处的矩阵[Cf]的维数很大,求解其特征值和特征向量比较复杂,这个时候需要对(3)式进行变形,简化求解,其变形结果如下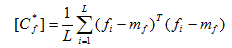
此时,对(5)式中的矩阵进行特征值和特征向量的求解,将求解出的特征向量和特征值经过SVD奇异值分解,得到原训练样本的特征向量,这样就可以构造出最终的人脸投影空间。

其中vi就是(5)中协方差矩阵的特征向量,p是特征向量的个数。将特征向量转化为矩阵,矩阵就可以表示图像,也即是所谓的特征脸,如下:
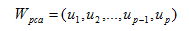 接下来就可以通过K-L变换式进行投影计算了,得出各个样本在空间Wpca上的投影特征了:
接下来就可以通过K-L变换式进行投影计算了,得出各个样本在空间Wpca上的投影特征了:
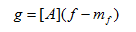
其中[A]就是空间Wpca,其实(8)式中不用(f-mf)也行,直接换成f就可以,即表示将原人脸样本在空间Wpca上进行投影,将投影后的特征系数存在矩阵g中,如果没有记错的话,g中每一行表示一个人脸样本的特征系数(或者每一列表示一个人脸样本的特征稀疏,这个与个人的计算方法有关,主要是看矩阵的转置或者不转置)。
到这里PCA人脸识别的主要步骤已经介绍完了,剩下的就是识别过程了,这个比较容易理解,首先将训练样本在空间[A]上进行投影,得到投影样本的特征系数,然后将测试样本也在空间[A]上进行投影,得到每个测试杨样本的投影特征系数,此时,只需将测试某个样本的特征系数与训练样本投影特征系数进行欧式距离度量,看要测试的那个样本与训练集中哪个样本的欧式距离最近,就可以将该测试样本归为与之距离最近那个样本的类别。比如:训练样本a1属于S1类(S1类中包含很多样本,a1只是其中的一个样本),如果测试样本b1和a1的距离最近,那么就将b1归为S1类。如此下来,对所有的样本进行分类,就可以得到PCA人脸识别率了。