表
线性表的定义
线性表,从名字上来看,像线连起来的表。每个元素都是连起来的,比如在体育课按照老师定好的队列排队的时候,有一个打头,一个收尾,中间的每个人都知道前面是谁,后面是谁,就像一根线将他们联系在一起,就可以称之为线性表。
这时候我们来看几个关键点,首先元素之间是有顺序的,并且第一个元素无前驱,最后一个元素无后继,其他的元素都有且只有一个前驱和后继,这样才能形成线性表。
我们用数学语言来进行定义,若有线性表(a1,a2,….,ai-1,ai,ai+1,…,an),则称表中ai-1是ai的直接前驱元素,ai+1是ai的直接后继元素,a1没有直接前驱元素,an没有直接后继元素。线性表元素的个数定义为线性表的长度,当n=0时的特殊表我们称之为空表。
我们来举几个例子,每年的星座列表是不是线性表?当然是,因为星座以白羊打头,双鱼收尾,其中的都有且只有一个前驱和后继,所以完全符合线性表的条件。
那么公司的上下级关系是不是线性表?当然不是,因为一个上级会有很多个下级,每个人不只有一个后继和前驱,不符合线性表的条件。
前面我们明确定义了线性表的概念,与这些概念相关的是线性表应该具有的操作集合。
例如,向表中插入一个数据,或者获取表中的某个元素,删除某个元素,获取某个元素的直接前驱后继等操作,当然对于不同的应用,线性表应该有什么操作都是不同的,完全由程序设计者来决定,当然像增删查等必要的操作基本是每个线性表都需要具有的。
顺序存储结构
线性表的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。

说白了,就是在内存中找一块位置,把一定的内存空间占了,然后把相同数据类型的数据元素按顺序存放在这儿。说到这儿,我们可能有人会想起来,和数组怎么那么像呢?对,线性表的每个数据元素类型都相同,所以我们完全可以通过数组来实现线性表的顺序存储结构。
如果我们用数组来实现的话,我们就必须需要两个属性:线性表的长度,需要的数组长度。并且要保证线性表的长度要小于数组的长度,因为我们可能还需要执行插入操作。
java顺序结构线性表的实现

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
上面是我们实现的顺序结构存储的线性表,我们已经发现了插入和删除是最麻烦的,步骤最多,需要很多遍历,我们来分析一下这两个操作的时间复杂度。
如果要插入的或者删除的是最后一个元素,那么不需要移动任何元素,这时候为O(1).
如果要插入的或者删除的是第一个元素,那么所有元素都需要移动,这时候为O(n).
而当执行存储和查询的时候,时间复杂度都为O(1),这也间接的说明了一个问题,它比较适合元素个数不变化的存取操作,而插入和删除很不方便。
线性表顺序结构存储的优缺点
- 优点:可以快速的存取表中任意位置的数据
- 缺点:插入和删除需要移动元素,花费大量时间,并且当数组扩容时,难以确定存储空间的容量,容易造成存储空间的碎片化。-
链式存储结构
前面我们已经证明了,线性表的顺序存储结构有一个很大的缺点,就是插入和删除操作时需要消耗大量时间,能不能想个办法解决一下呢?
首先我们需要思考一下为什么会造成这个情况,仔细思考其实是因为两个相邻元素之间在内存中也是紧挨着的,如果要插入自然要向后移,否则会出现覆盖,要删除,后面的元素自然也要向前移。那么我们应该怎么解决这一情况呢?我们可不可以让逻辑上相邻的两个元素,在内存中其实不是相邻的,而只需前一个元素知道后一个元素的地址,然后连起来就行了?对,这就是我们要讲的链式存储结构。
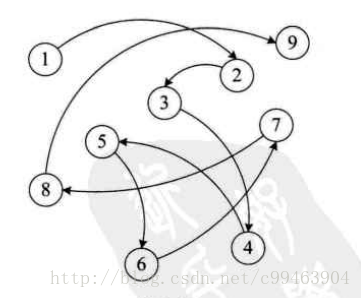
通常讲采用链式存储结构的线性表称为线性链表,从链接方式来看,链表可分为单链表、循环链表和双链表。从实现角度来看,链表分为动态链表和静态链表。
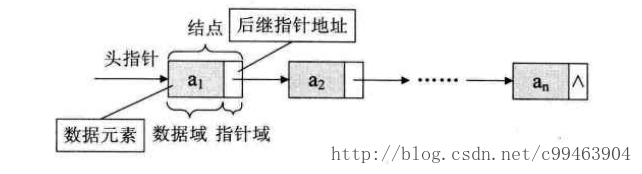
链表用一组任意的存储单元来存储线性表的元素,这组存储单元可以连续也可以不连续,所以现在每个元素中除了要存储数据,还要存储其后继元素的存储地址。我们把存储数据元素信息的域称为数据域,把存储后继元素位置的域称为指针域,这两部分共同组成一个数据元素单元,我们把它叫做结点(Node)。
单链表
每个结点中的指针域只包含下一个结点的位置,叫做单链表。单链表的最后一个结点指向为null。
单链表的java实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
单链表的优缺点
通过代码的编写,我们发现单链表的查找方法时间复杂度为O(n),而插入和删除为O(1)
-
优点:执行插入和删除效率高,不需要事先分配空间,元素个数不受限制,不会浪费空间
-
缺点:查找效率比较低
我们可以得出一些结论,若线性表需要频繁查找,很少进行插入和删除操作时,则使用顺序存储结构。反之,需要大量的插入和删除时,则使用链式存储结构。
循环链表
循环链表是一个首尾相连的链表,将单链表最后一个结点的地址域改为指向表头结点,就得到了单链循环链表,称为循环单链表。
循环单链表和单链表的主要差异就在循环的判断条件上,单链表判断循环结束是看地址域是否为空,而循环单链表则是判断地址域是否是头结点。在前面的单链表中,我们总是用一头结点来指向我们的第一个数据元素,这样非常方便。在单链表中,我们有了头结点,可以很快的访问到第一个元素,访问最后一个元素却需要O(n),循环链表就可以解决这个问题,使访问第一个元素和最后一个元素都是O(1),怎么实现呢?再添加一个指向尾部的结点。
循环单链表的实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
双向链表
我们在单链表中如果要查找上一个结点的话,那就得从头开始循环了,最坏的时间复杂度就是O(n),
你会想这也太麻烦了,我能不能像next直接查找下一个结点一样,设计链表可以直接查找上一个结点呢?当然可以,为了克服上述问题,前辈们设计了双向链表。
双向链表:就是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的每个结点都有两个指针域,一个指向直接后继,一个指向直接前驱。
既然单链表可以有循环链表,那么双向链表当然也可以循环。
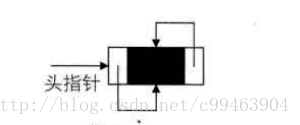
双向循环链表为空时
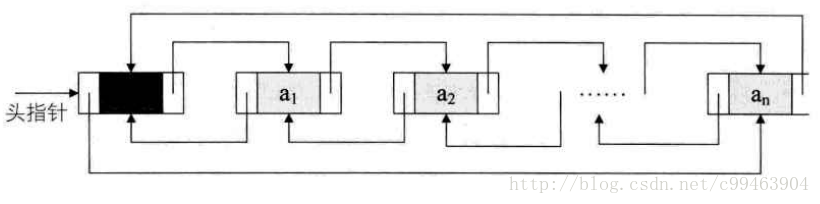
双向循环链表不为空时
双向循环链表的实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
双向循环链表就是典型的用空间换时间。
JAVA API中的表实现
JAVA的类库中,包含着很多数据结构的实现,设计的很精妙,所以说JDK源码就是我们非常好的学习工具。Collection接口中有很多使用我们数据结构来实现的集合类,我们今天就来看看集合中的那些表实现。
Collecation接口中定义了很多集合类中应该有的方法,并且实现了Iterable接口,实现Iterable接口的类可以使用增强for循环。
实现Iterable接口的集合必须提供Iterator方法,该方法返回一个Iterator对象,Iterator也是java.util包中的一个接口,Iterator接口主要是为了遍历集合,将当前的位置在对象内部存储起来,然后就可以进行遍历。当一个增强for循环在循环一个实现Iterable接口的对象时,其实增强for循环内部就是使用的Iterator对象在进行遍历。
好了,说了这么多,我们扯得有点远,我们这次最大的目的是来看看jdk中的表实现,它由java.util包中的List接口指定,它下面有很多实现类,例如ArrayList类就是顺序结构线性表的实现,存取指定位置元素比较方便,而插入和删除效率就很低。LinkedList类则是双链表的实现,存取指定位置元素效率比较低,而插入和删除的效率则高于ArrayList。
尽管前面我们已经知道了顺序结构线性表和链表的差别,这里我们再来看一下ArrayList和LinkedList的差别。
-
不论是对于ArrayList还是LinkedList而言,在后端添加N个元素的操作运行时间都是O(n).
-
如果从集合前面添加N个元素的话,,LinkedList的运行时间是O(n),而ArrayList每添加一个就是O(n),添加n个则是O(n^2)
-
对于通过get()计算集合中n个数的和的方法,ArrayList的运行时间是O(n),LinkedList则为O(n^2),但是如果使用迭代器的话,那么任意的List集合运行时间都是O(n),因为迭代器会记录当前
位置。
小例子:remove方法对LinkedList的使用
我们来做一个例子,将一个表中的所有偶数都删除,我们当然不可能使用ArrayList,因为每次操作都是O(n),所以我们要使用LinkedList..
我们先来一种我们正常思考的算法。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
怎么解决这两个问题呢?我们用我们前面提到的迭代器。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
ArrayList的实现
我们前面实现的顺序结构存储的线性表其实就是ArrayList的内部实现,如果有什么模糊的地方可以去前面看看源代码,这里我们来实现点更接近ArrayList的功能,那就是迭代器。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
当然ArrayList内部采用的是内部类来实现迭代器,这样有一个很明显的优点就是可以直接操作当前的集合对象,而不用别人再来传递,并且可以获得当前集合的所有属性来操作。
LinkedList的实现
JDK中的LinkedList是一个双向链表,并且没有循环。我们前面也实现了,具体可以看看前面的代码。
至于LinkedList迭代器的实现,我想大家有了前面的基础,会很容易的实现。
表
线性表的定义
线性表,从名字上来看,像线连起来的表。每个元素都是连起来的,比如在体育课按照老师定好的队列排队的时候,有一个打头,一个收尾,中间的每个人都知道前面是谁,后面是谁,就像一根线将他们联系在一起,就可以称之为线性表。
这时候我们来看几个关键点,首先元素之间是有顺序的,并且第一个元素无前驱,最后一个元素无后继,其他的元素都有且只有一个前驱和后继,这样才能形成线性表。
我们用数学语言来进行定义,若有线性表(a1,a2,….,ai-1,ai,ai+1,…,an),则称表中ai-1是ai的直接前驱元素,ai+1是ai的直接后继元素,a1没有直接前驱元素,an没有直接后继元素。线性表元素的个数定义为线性表的长度,当n=0时的特殊表我们称之为空表。
我们来举几个例子,每年的星座列表是不是线性表?当然是,因为星座以白羊打头,双鱼收尾,其中的都有且只有一个前驱和后继,所以完全符合线性表的条件。
那么公司的上下级关系是不是线性表?当然不是,因为一个上级会有很多个下级,每个人不只有一个后继和前驱,不符合线性表的条件。
前面我们明确定义了线性表的概念,与这些概念相关的是线性表应该具有的操作集合。
例如,向表中插入一个数据,或者获取表中的某个元素,删除某个元素,获取某个元素的直接前驱后继等操作,当然对于不同的应用,线性表应该有什么操作都是不同的,完全由程序设计者来决定,当然像增删查等必要的操作基本是每个线性表都需要具有的。
顺序存储结构
线性表的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。
说白了,就是在内存中找一块位置,把一定的内存空间占了,然后把相同数据类型的数据元素按顺序存放在这儿。说到这儿,我们可能有人会想起来,和数组怎么那么像呢?对,线性表的每个数据元素类型都相同,所以我们完全可以通过数组来实现线性表的顺序存储结构。
如果我们用数组来实现的话,我们就必须需要两个属性:线性表的长度,需要的数组长度。并且要保证线性表的长度要小于数组的长度,因为我们可能还需要执行插入操作。
java顺序结构线性表的实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
上面是我们实现的顺序结构存储的线性表,我们已经发现了插入和删除是最麻烦的,步骤最多,需要很多遍历,我们来分析一下这两个操作的时间复杂度。
如果要插入的或者删除的是最后一个元素,那么不需要移动任何元素,这时候为O(1).
如果要插入的或者删除的是第一个元素,那么所有元素都需要移动,这时候为O(n).
而当执行存储和查询的时候,时间复杂度都为O(1),这也间接的说明了一个问题,它比较适合元素个数不变化的存取操作,而插入和删除很不方便。
线性表顺序结构存储的优缺点
- 优点:可以快速的存取表中任意位置的数据
- 缺点:插入和删除需要移动元素,花费大量时间,并且当数组扩容时,难以确定存储空间的容量,容易造成存储空间的碎片化。-
链式存储结构
前面我们已经证明了,线性表的顺序存储结构有一个很大的缺点,就是插入和删除操作时需要消耗大量时间,能不能想个办法解决一下呢?
首先我们需要思考一下为什么会造成这个情况,仔细思考其实是因为两个相邻元素之间在内存中也是紧挨着的,如果要插入自然要向后移,否则会出现覆盖,要删除,后面的元素自然也要向前移。那么我们应该怎么解决这一情况呢?我们可不可以让逻辑上相邻的两个元素,在内存中其实不是相邻的,而只需前一个元素知道后一个元素的地址,然后连起来就行了?对,这就是我们要讲的链式存储结构。
通常讲采用链式存储结构的线性表称为线性链表,从链接方式来看,链表可分为单链表、循环链表和双链表。从实现角度来看,链表分为动态链表和静态链表。
链表用一组任意的存储单元来存储线性表的元素,这组存储单元可以连续也可以不连续,所以现在每个元素中除了要存储数据,还要存储其后继元素的存储地址。我们把存储数据元素信息的域称为数据域,把存储后继元素位置的域称为指针域,这两部分共同组成一个数据元素单元,我们把它叫做结点(Node)。
单链表
每个结点中的指针域只包含下一个结点的位置,叫做单链表。单链表的最后一个结点指向为null。
单链表的java实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
单链表的优缺点
通过代码的编写,我们发现单链表的查找方法时间复杂度为O(n),而插入和删除为O(1)
-
优点:执行插入和删除效率高,不需要事先分配空间,元素个数不受限制,不会浪费空间
-
缺点:查找效率比较低
我们可以得出一些结论,若线性表需要频繁查找,很少进行插入和删除操作时,则使用顺序存储结构。反之,需要大量的插入和删除时,则使用链式存储结构。
循环链表
循环链表是一个首尾相连的链表,将单链表最后一个结点的地址域改为指向表头结点,就得到了单链循环链表,称为循环单链表。
循环单链表和单链表的主要差异就在循环的判断条件上,单链表判断循环结束是看地址域是否为空,而循环单链表则是判断地址域是否是头结点。在前面的单链表中,我们总是用一头结点来指向我们的第一个数据元素,这样非常方便。在单链表中,我们有了头结点,可以很快的访问到第一个元素,访问最后一个元素却需要O(n),循环链表就可以解决这个问题,使访问第一个元素和最后一个元素都是O(1),怎么实现呢?再添加一个指向尾部的结点。
循环单链表的实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
双向链表
我们在单链表中如果要查找上一个结点的话,那就得从头开始循环了,最坏的时间复杂度就是O(n),
你会想这也太麻烦了,我能不能像next直接查找下一个结点一样,设计链表可以直接查找上一个结点呢?当然可以,为了克服上述问题,前辈们设计了双向链表。
双向链表:就是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的每个结点都有两个指针域,一个指向直接后继,一个指向直接前驱。
既然单链表可以有循环链表,那么双向链表当然也可以循环。
双向循环链表为空时
双向循环链表不为空时
双向循环链表的实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
双向循环链表就是典型的用空间换时间。
JAVA API中的表实现
JAVA的类库中,包含着很多数据结构的实现,设计的很精妙,所以说JDK源码就是我们非常好的学习工具。Collection接口中有很多使用我们数据结构来实现的集合类,我们今天就来看看集合中的那些表实现。
Collecation接口中定义了很多集合类中应该有的方法,并且实现了Iterable接口,实现Iterable接口的类可以使用增强for循环。
实现Iterable接口的集合必须提供Iterator方法,该方法返回一个Iterator对象,Iterator也是java.util包中的一个接口,Iterator接口主要是为了遍历集合,将当前的位置在对象内部存储起来,然后就可以进行遍历。当一个增强for循环在循环一个实现Iterable接口的对象时,其实增强for循环内部就是使用的Iterator对象在进行遍历。
好了,说了这么多,我们扯得有点远,我们这次最大的目的是来看看jdk中的表实现,它由java.util包中的List接口指定,它下面有很多实现类,例如ArrayList类就是顺序结构线性表的实现,存取指定位置元素比较方便,而插入和删除效率就很低。LinkedList类则是双链表的实现,存取指定位置元素效率比较低,而插入和删除的效率则高于ArrayList。
尽管前面我们已经知道了顺序结构线性表和链表的差别,这里我们再来看一下ArrayList和LinkedList的差别。
-
不论是对于ArrayList还是LinkedList而言,在后端添加N个元素的操作运行时间都是O(n).
-
如果从集合前面添加N个元素的话,,LinkedList的运行时间是O(n),而ArrayList每添加一个就是O(n),添加n个则是O(n^2)
-
对于通过get()计算集合中n个数的和的方法,ArrayList的运行时间是O(n),LinkedList则为O(n^2),但是如果使用迭代器的话,那么任意的List集合运行时间都是O(n),因为迭代器会记录当前
位置。
小例子:remove方法对LinkedList的使用
我们来做一个例子,将一个表中的所有偶数都删除,我们当然不可能使用ArrayList,因为每次操作都是O(n),所以我们要使用LinkedList..
我们先来一种我们正常思考的算法。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
怎么解决这两个问题呢?我们用我们前面提到的迭代器。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
ArrayList的实现
我们前面实现的顺序结构存储的线性表其实就是ArrayList的内部实现,如果有什么模糊的地方可以去前面看看源代码,这里我们来实现点更接近ArrayList的功能,那就是迭代器。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
当然ArrayList内部采用的是内部类来实现迭代器,这样有一个很明显的优点就是可以直接操作当前的集合对象,而不用别人再来传递,并且可以获得当前集合的所有属性来操作。
LinkedList的实现
JDK中的LinkedList是一个双向链表,并且没有循环。我们前面也实现了,具体可以看看前面的代码。
至于LinkedList迭代器的实现,我想大家有了前面的基础,会很容易的实现。