在这篇文章中,我们探讨了一个机器学习模型能够拥有的保证类型 。 我们认为,现有防御的局限性表明缺乏对机器学习模型的验证。 事实上,为了设计可靠的系统,工程师通常参与测试和验证:
通过测试 ,我们的意思是在几种条件下评估系统并观察其行为,观察缺陷。
通过验证 ,我们的意思是提出一个令人信服的论点,即该系统不会在非常广泛的情况下行事不端。
与此问题正交的是哪些输入值应该经过验证和测试的问题。 我们是否打算仅对“自然发生的”合法投入进行验证或测试该系统,还是打算为其任意的退化投入行为提供保证? 许多软件系统(如编译器)对某些输入有未定义的行为。
我们应该测试还是验证? 在哪些投入?
机器学习从业人员传统上主要依靠测试。 分类器通常通过将分类器应用于从测试集中绘制出的几个示例并测量这些示例的准确性来进行评估。 根据定义,这些测试程序无法找到可能被错误分类的所有可能的以前不可见的例子。
测量测试集错误的验证模拟是统计学习理论[V98]。 统计学习理论保证测试错误率不可能超过某个阈值,但这些保证通常非常保守,以至于工程师在实践中不使用这些保证。
即使应用了统计学习理论,通常也只考虑“自然发生”的输入:保证是用与训练数据相同的分布得出的点表示的。
在等式中引入对手
为了提供安全保证,有必要沿着两条轴进行改进:1)我们必须使用验证而不是测试; 2)我们必须确保模型在攻击者制作的异常输入中安全行事。 从业者想要保证的一个研究得很好的财产是对敌对案例的稳健性 。
测试对抗性示例的鲁棒性的自然方法是简单地评估模型在已经被敌对扰动的测试集上的准确性以创建对抗示例[SZS13]。 这将机器学习中使用的传统测试方法应用于一组新的输入。
不幸的是,测试不足以提供安全保证,因为攻击者可以发送与用于测试过程的输入不同的输入。 例如,经过测试并发现对抗对抗式示例生成[GSS14]的快速梯度符号方法的模型可能容易受到更多计算上昂贵的方法的攻击,如基于数值优化[SZS13]或显着图[PMJ16]的攻击。
一般来说,测试是不够的,因为它提供了系统故障率的下限 ,当提供安全保证时, 上限是必要的。 换句话说,测试标识 n
导致故障的输入,所以工程师至少可以得出结论 n 投入导致失败; 工程师宁愿拥有一种最多变得相当有信心的手段 n输入导致失败。
在机器学习环境中遇到的这些测试限制让人想起在许多其他类型的软件设计中遇到的情况。 在讨论保证程序正确性的方法时,Edsger Dijkstra说:“测试表明存在,而不是缺少缺陷。”
很显然, 测试 自然发生的输入对于传统的机器学习应用程序是足够的,但是对于安全保证来说, 验证 异常输入是必需的。 我们应该验证,但到目前为止,我们只知道如何测试 。
当前的机器学习模型非常容易被破坏,因此对异常输入进行测试足以揭示其缺陷。 希望在不久的将来我们能够更好地防范敌对的例子。 测试可能不足以揭示这些模型中的缺陷,我们将需要验证技术来研究新防御的有效性。 正确处理投入空间的保证的发展是ML在对抗环境下的未来的核心,并且它几乎肯定会以形式验证为基础。
ML的理论验证
机器学习模型对敌对案例的鲁棒性的验证尚处于起步阶段。 目前的方法验证分类器将相同的类分配给点的指定邻域内的所有点 x
。 在下面的动画中,我们演示了这种类型的方法,并将其与在同一邻域中测试各个点进行比较。
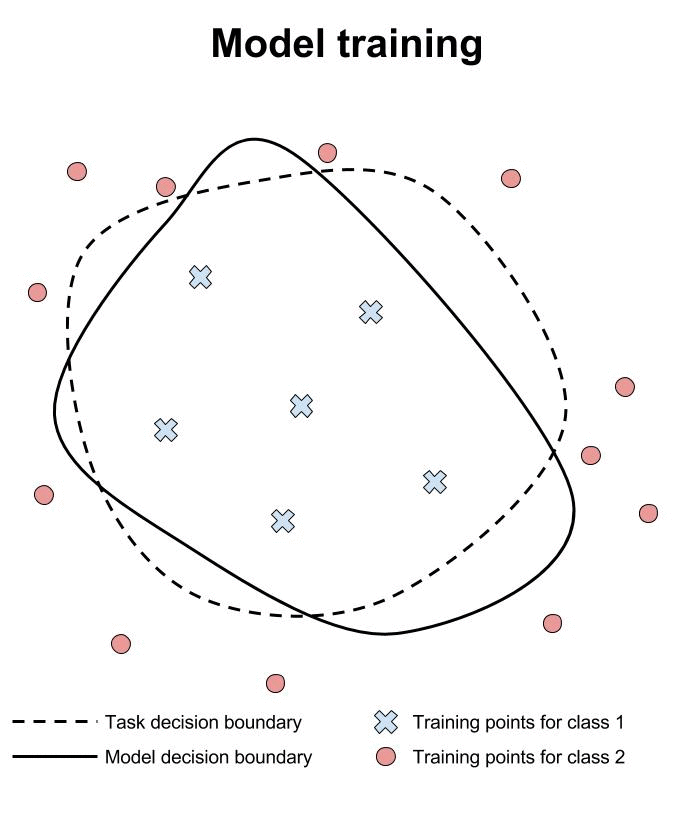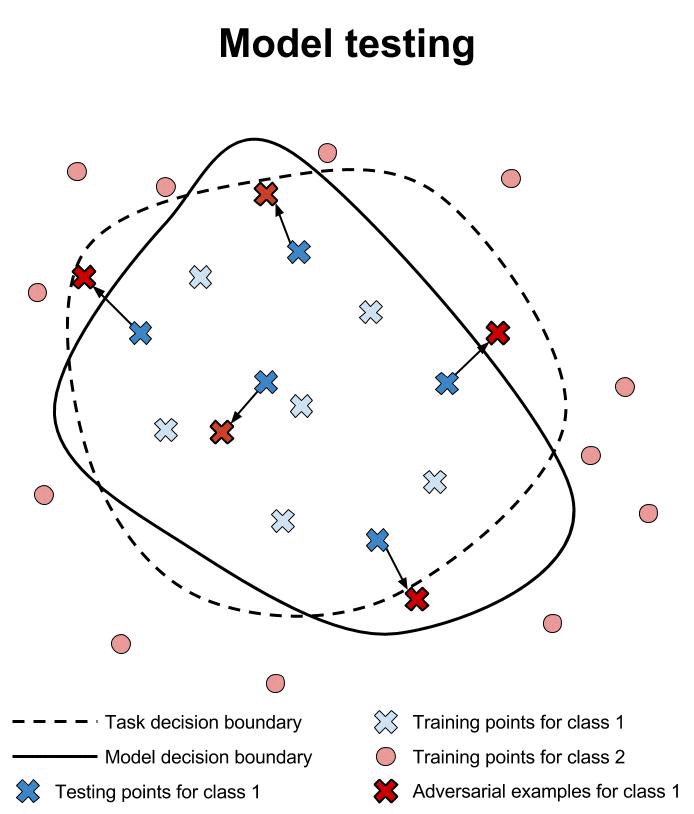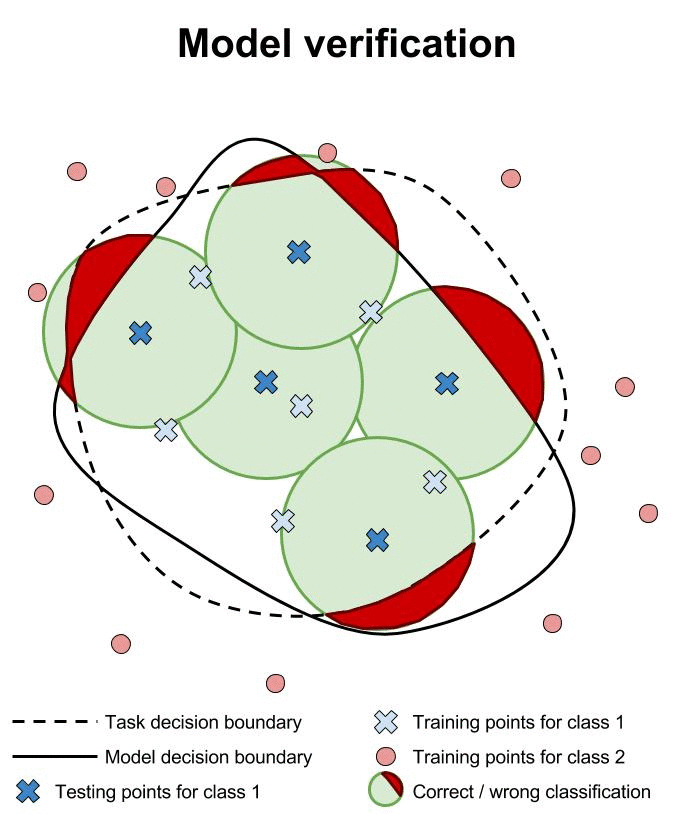
研究人员正在努力构建神经网络的验证系统。 不幸的是,这些系统还不成熟。 Pulina等人 开发了第一个验证系统,用于证明神经网络的输出类别在所需的邻域内保持不变[PT10]。 这第一个系统仅限于一个隐藏层,并且仅在具有少于十几个隐藏单元的网络上进行演示。 另外,使用约束来近似S形激活函数以将问题减少到SAT。
后来,黄等人。 对这种初始方法进行了改进,并提出了适用于现代神经网络体系结构的新验证系统[HKW16]。 该系统扩展到更大的网络,例如ImageNet分类器。 新验证系统的一个局限性在于它依赖于各种假设 - 例如,神经网络中只有一部分隐藏单元与每个输入相关。 这些假设意味着系统不能再提供绝对保证缺乏对抗性的例子,因为违反这些假设的对抗性例子(例如,通过操纵被假定为无关的单位之一)可以逃避检测。
Reluplex [KBD17]是另一种使用LP解算器扩展到更大网络的验证系统。 Reluplex能够通过专门研究整流线性网络[GBB11,JKL09,NH10]及其分段线性结构而变得更加高效。
这些现行的核查制度的范围有限,因为它们仅核实某些特定地点某个指定地区的产出类别保持不变 x
。 这有两个限制:
我们没有办法详尽列举所有 x
分类器应该近似于常数的点(我们无法想象所有未来自然发生的输入)
周围的社区 x
我们目前使用的是有些武断和保守的; 我们倾向于使用 Lp由于人类观察者认为,对于一个足够小的标准球,所有封闭点应该具有相同的类别,但是实际上,常量类别的区域应该更大并且具有不同的,不规则的,不太容易指定的形状。
总之,验证机器学习模型首先要求我们定义一组合法输入,即我们希望模型正确分类的一组输入。 这套法律输入通常比大多数基准中包含的“测试集”大得多。 然后研究人员将不得不设计验证技术,以有效地保证对整套法律输入所做的机器学习预测的正确性。 机器学习中经常遇到的挑战 - 例如需要推广到新的投入 - 可能使这成为一个特别困难的目标,正如本文中引用的努力[PT10,HKW16,KBD17]所表明的那样。 如果是这样的话,其他社区开发的技术可以通过更接近测试的程序对机器学习模型进行部分验证:一个很好的例子就是模糊测试在计算机安全领域的积极影响。
对抗环境中有没有“免费午餐”定理?
值得考虑的是没有验证系统可能存在的可能性,因为没有机器学习模型将永远是完全健壮和准确的。 特别是,在接近新的,以前看不见的合法投入的情况下推广投入的挑战 x
似乎很难克服。
在传统的机器学习环境中,机器学习系统在新的测试点上的预期能力有多明确的理论限制。 例如,“无免费午餐”定理[W96]指出,当对所有可能的数据集进行平均时, 所有监督分类算法在新测试点上具有相同的准确度。
一个重要的开放理论问题是,“不免费午餐”定理是否可以延伸到对抗环境。 如果我们假设攻击者通过对测试集进行小扰动来操作,那么“无免费午餐”定理的前提是,平均值被用于所有可能的数据集,包括小扰动不应该被分类器忽略的数据集,否更久适用。
根据这个问题的解决方案,攻击者和维权者之间的军备竞赛可能会有两种不同的结果。 由于与预测新测试点的正确值相关的固有统计困难,攻击者可能从根本上具有优势。 如果我们幸运的话,防御者可能对广泛的问题类有一个基本的优势,为设计和验证具有鲁棒性保证的算法铺平了道路。
有兴趣的读者可以在[PMS16]中找到关于这个问题的初步讨论。 该分析描述了模型准确性和对抗性努力的稳健性之间的权衡。 它表明,在存在能够找到增加学习者损失的分布的对手的情况下,学习者从移动到更丰富的假设类别中受益。 更丰富的假设类被非正式地定义为一个更复杂的假设类别,它可以为任何分布提供较低的最低损失。 因此,在数据有限的情况下可能会出现紧张局势 - 因为学习更复杂的假设通常需要更多的实践数据。
使用CleverHans进行可重复测试
尽管从理论角度来看验证具有挑战性,但从实际角度来看,即使是简单的测试也是具有挑战性的。 假设研究人员提出了一种新的防御程序,并针对特定的对抗性示例攻击程序评估了防御。 如果最终的模型获得高准确性,这是否意味着辩护是有效的? 可能,但也可能意味着研究人员对攻击的执行力度很弱。 当研究人员针对他们自己的共同防御程序的实施测试所提出的攻击技术时,会出现类似的问题。
为了解决这些困难,我们创建了CleverHans库 。 这个库包含几个攻击和防御程序的参考实现。 研究人员和产品开发人员可以使用cleverhans来测试他们的模型,以对抗标准化,最先进的攻击和防御。 通过这种方式,如果防御对抗cleverhans攻击获得高准确性,测试结果显示防御力强,而且如果攻击获得了对抗cleverhans防御的高失败率,测试结果显示攻击强烈。 此外,发表的研究结果可以相互比较,只要它们在类似的计算环境中使用相同版本的CleverHans制作即可。
结论
机器学习模型的验证仍处于起步阶段,因为方法会做出假设,阻止它们提供缺乏对抗性例子的绝对保证。 我们希望我们的读者能够得到启发,解决其中的一些问题。 另外,我们鼓励研究人员使用CleverHans来提高敌对设置中机器学习测试的可重复性。
致谢
我们要感谢Martin Abadi对这篇文章的草稿的反馈。 感谢Marta Kwiatkowska指出动画图例中的颜色错误,将测试与验证进行比较。
References
[GBB11] Glorot, X., Bordes, A., & Bengio, Y. (2011, April). Deep Sparse Rectifier Neural Networks. In Aistats (Vol. 15, No. 106, p. 275).
[GSS14] Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572.
[HKW16] Huang, X., Kwiatkowska, M., Wang, S., & Wu, M. (2016). Safety Verification of Deep Neural Networks. arXiv preprint arXiv:1610.06940.
[JKL09] Jarrett, K., Kavukcuoglu, K., & LeCun, Y. (2009, September). What is the best multi-stage architecture for object recognition?. In Computer Vision, 2009 IEEE 12th International Conference on (pp. 2146-2153). IEEE.
[KBD17] Katz, G., Barrett, C., Dill, D., Julian, K., & Kochenderfer, M. (2017). Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks. arXiv preprint arXiv:1702.01135.
[NH10] Nair, V., & Hinton, G. E. (2010). Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10) (pp. 807-814).
[PMJ16] Papernot, N., McDaniel, P., Jha, S., Fredrikson, M., Celik, Z. B., & Swami, A. (2016, March). The limitations of deep learning in adversarial settings. In 2016 IEEE European Symposium on Security and Privacy (EuroS&P) (pp. 372-387). IEEE.
[PMS16] Papernot, N., McDaniel, P., Sinha, A., & Wellman, M. (2016). Towards the Science of Security and Privacy in Machine Learning. arXiv preprint arXiv:1611.03814.
[PT10] Pulina, L., & Tacchella, A. (2010, July). An abstraction-refinement approach to verification of artificial neural networks. In International Conference on Computer Aided Verification (pp. 243-257). Springer Berlin Heidelberg.
[SZS13] Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. (2013). Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199.
[V98] Vapnik, V. (1998). Statistical Learning Theory.
[W96] Wolpert, D. H. (1996). The lack of a priori distinctions between learning algorithms. Neural computation, 8(7), 1341-1390.