To start with, let's read the passage and follow the instruction:
In this assignment you will take the provided starter code and fill in the missing details in order to create a working perceptron implementation.
To start, download the following code files:
And the following datasets:
Attention: some people have notified us that the provided datasets do not load under some versions of Octave. We are providing the same datasets in a different format that will hopefully work with more versions. You can find these files below.
And the following datasets:
- dataset1_ancient_octave.mat
- dataset2_ancient_octave.mat
- dataset3_ancient_octave.mat
- dataset4_ancient_octave.mat
For those who want to download all of the files together in a zip archive, you get get them here: Assignment1.zip
To run the code, you first need to load a dataset. To do so enter the following command in the Octave console (to load dataset 1):
load dataset1
after we type it, This should load 4 variables:
- neg_examples_nobias - The matrix containing the examples belonging to class 0.
- pos_examples_nobias - The matrix containing the examples belonging to class 1.
- w_init - Some initial weight vector.
- w_gen_feas - A generously feasible weight vector (empty if one doesn't exist)
That is: (the picture is as follow)
The variables have _nobias appended to their names because they do not have an additional column of 1's appended to them. This is done automatically in the learn_perceptron.m code already. Now that you have loaded a dataset, you can run the algorithm by entering the following at the Octave console:
w = learn_perceptron(neg_examples_nobias,pos_examples_nobias,w_init,w_gen_feas)
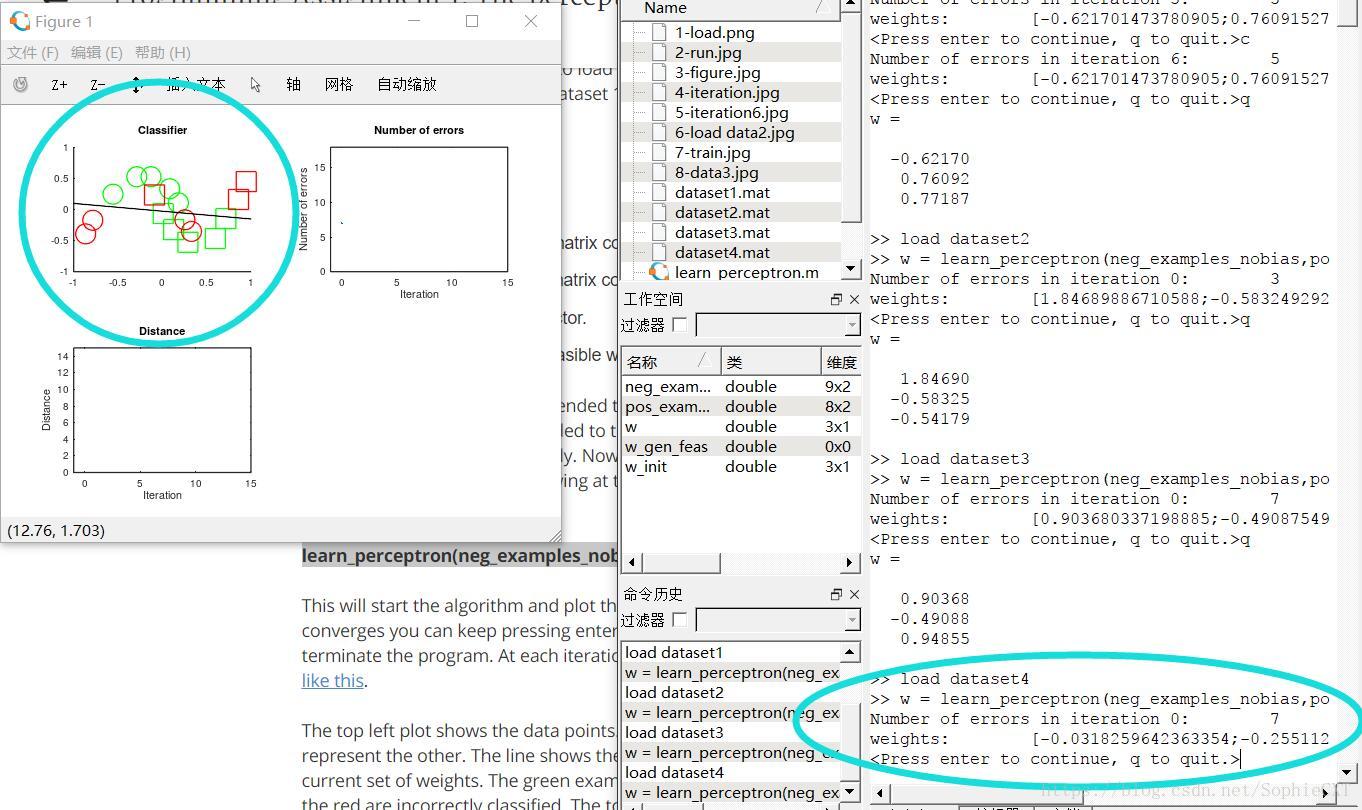
This will start the algorithm and plot the results as it proceeds. Until the algorithm converges you can keep pressing enter to run the next iteration. Pressing 'q' will terminate the program. At each iteration it should produce a plot that looks something like this.
So I type the command above( Which I colored it in blue)
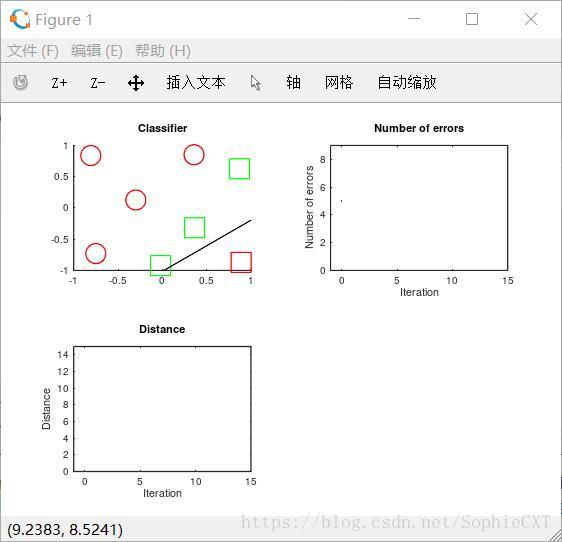
and things are shown below:
maybe you will be confused about the "distance" and " Number of errors", so let's do several iteration, and then you will see it clearly:
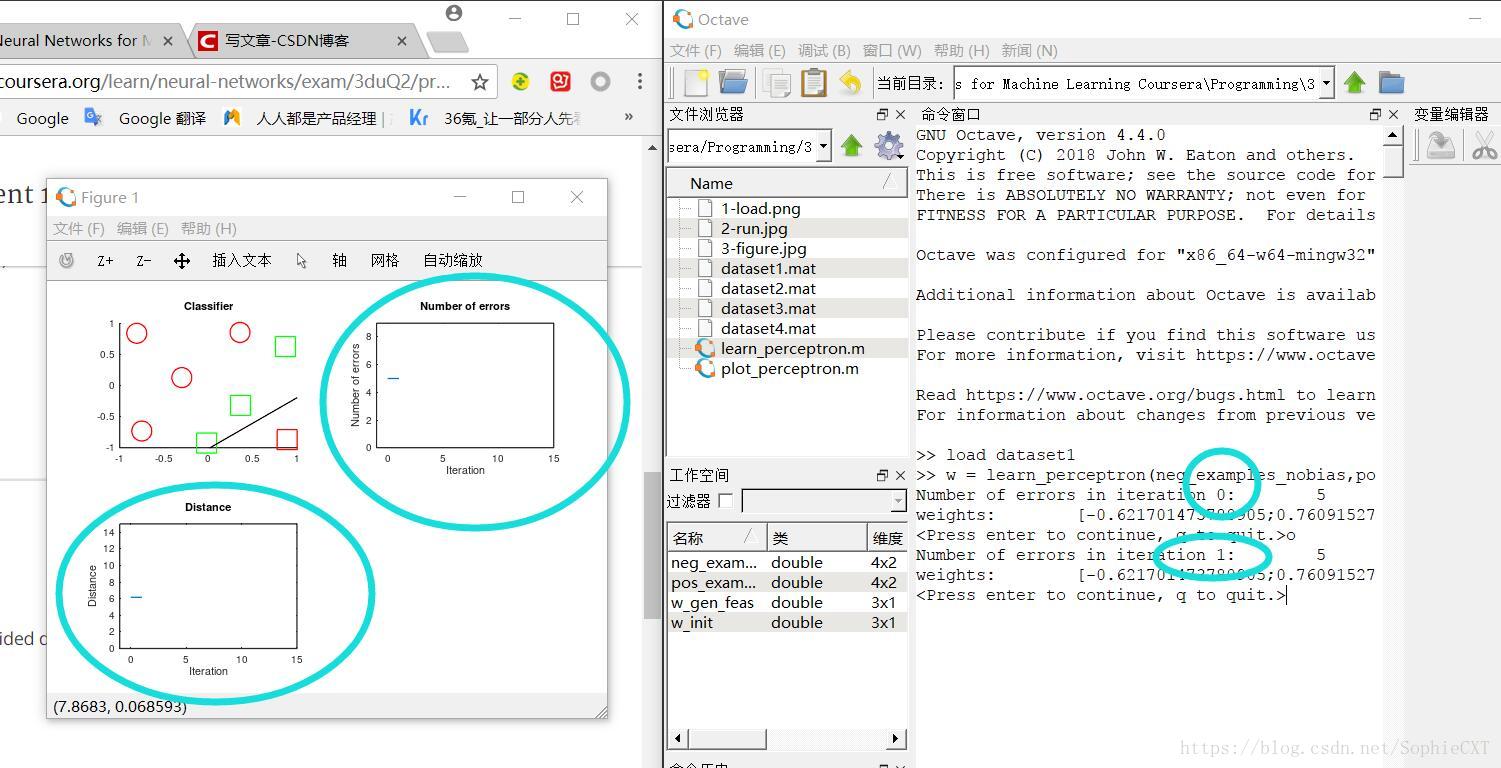
we can find that in the plot above, the dot linked into a line, let's do more iterations and you can figure it out:
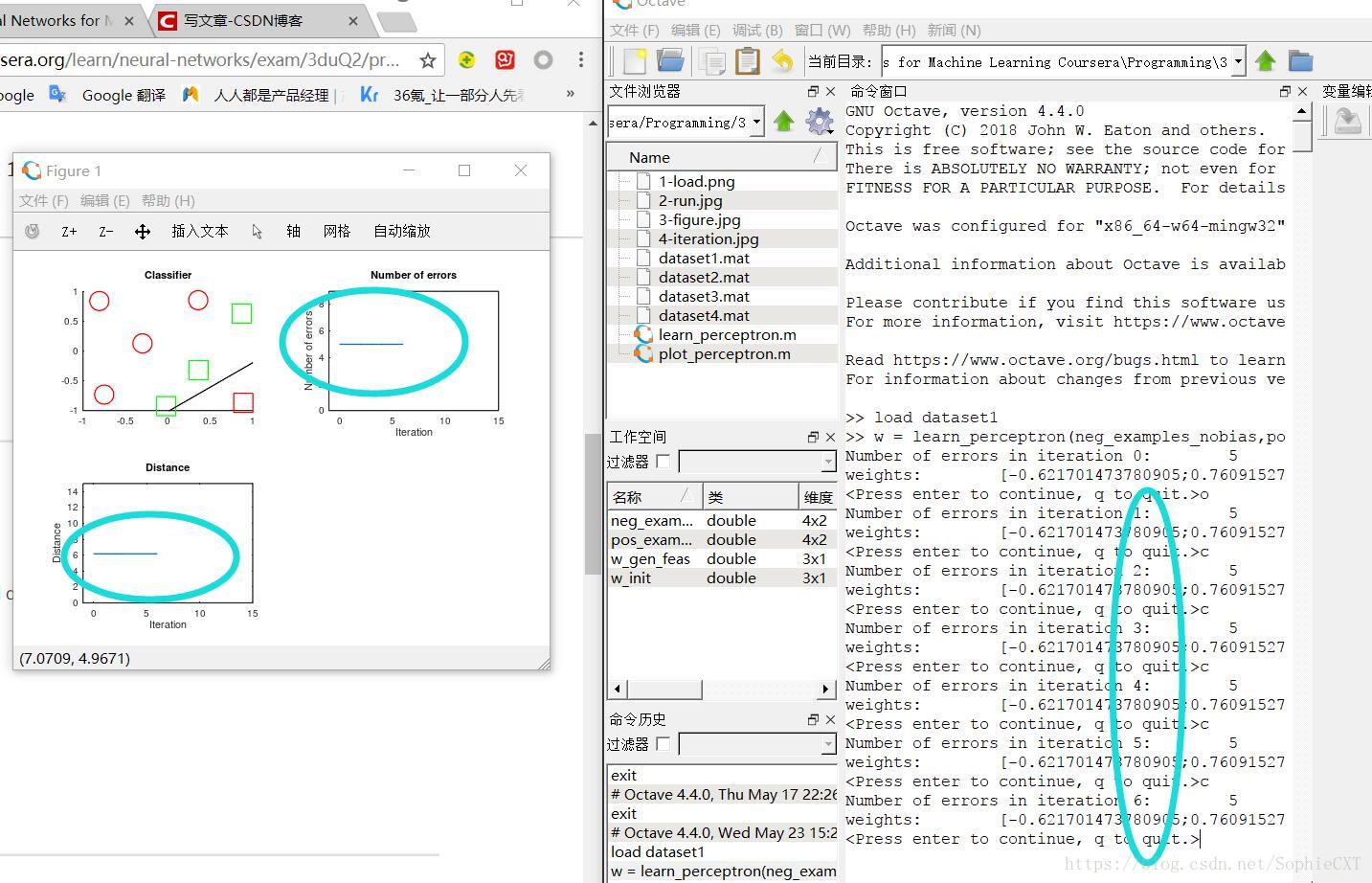
this is after 6 interations, we get a longer line, because we didn't make up the missing part in the code, so now the distance will not change.
The top left plot shows the data points. The circles represent one class while the squares represent the other. The line shows the decision boundary of the perceptron using the current set of weights. The green examples are those that are correctly classified while the red are incorrectly classified. The top-right plot will show the number of mistakes made by the perceptron. If a generously feasible weight vector is provided (and not empty), then the bottom left plot will show the distance of the learned weight vectors to the generously feasible weight vector.
Currently, the code doesn't do any learning. It is your job to fill this part in. Specifically, you need to fill in the lines under learn_perceptron.m marked %YOUR CODE HERE (lines 114 and 122). When you are finished, use this program to help you answer the questions below.
In addition, we print out the plot of dataset 2/3/4, because it will help us answering the questions below.
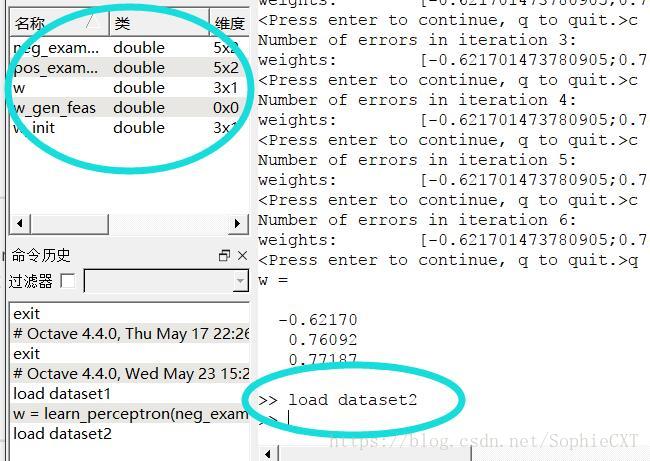
we can see that if we load different dataset, the variables will also change, and the plot of dataset2 is:
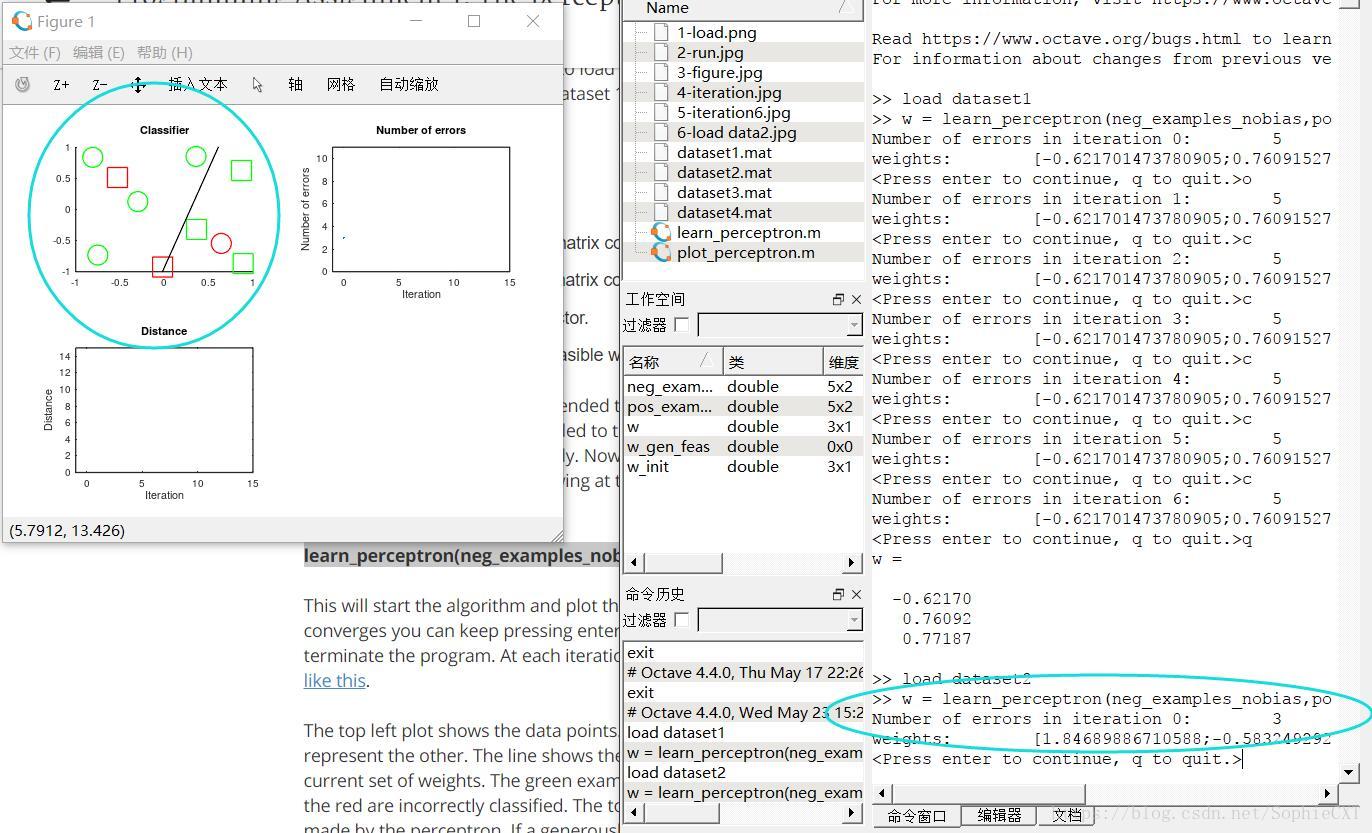
then, dataset3:
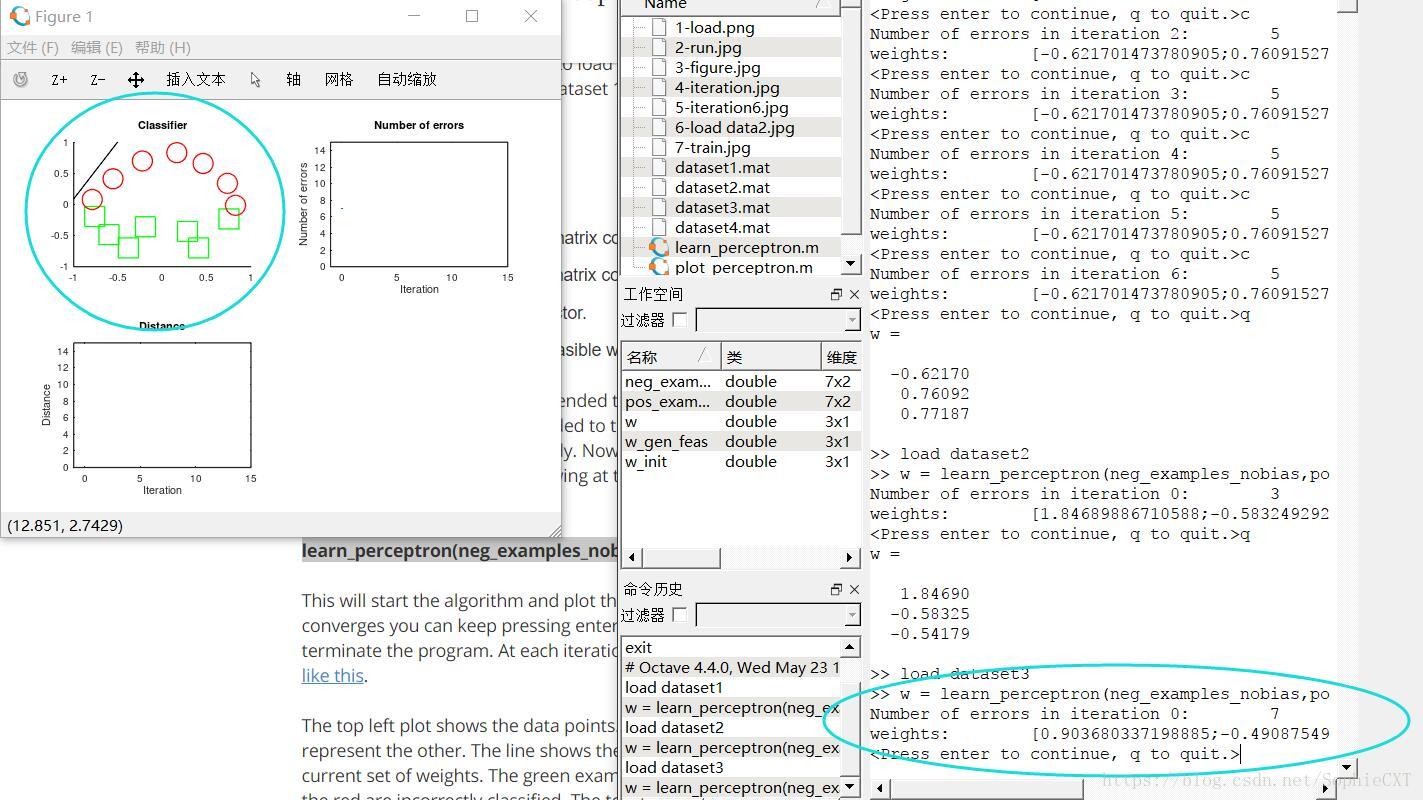
then, dataset4
{kind=link}
第 1 个问题
now we can answer the following questions:
2。第 2 个问题
Which of the provided datasets are not linearly separable? Check all that apply.
Dataset 2
Dataset 1
Dataset 4
Dataset 3
3。第 3 个问题
True or false: if the dataset is not linearly separable, then it is possible for the number of classification errors to increase during learning.
True
One training case might send the parameters off in a bad direction, that suddenly makes the perceptron misclassify many other training cases.
False
4。第 4 个问题
True or false: If a generously feasible region exists, then the distance between the current weight vector and any weight vector in the feasible region will monotonically decrease as the learning proceeds.
True
If a generously feasible region exists then the problem is linearly separable, however it is not true that the distance between the current weight vector and a vector that is merely in the feasible region will monotonically decrease as the learning proceeds. It is possible to verify this using the program.
False
5。第 5 个问题
The perceptron algorithm as implemented and described in class implicitly uses a learning rate of 1. We can modify the algorithm to use a different learning rate \alphaα so that the update rule for an input xx and target tt becomes:
w^{(t)} \leftarrow w^{(t-1)} + \alpha (t - \text{prediction})xw(t)←w(t−1)+α(t−prediction)x,
where \text{prediction}prediction is the decision made by the perceptron using the current weight vector w^{(t-1)}w(t−1), given by:
\text{prediction} =
True or false: if we use a learning rate of -1, then the perceptron algorithm will always converge to a solution for linearly separable datasets.
True
False
A learning rate of -1 means that the learning going in the wrong direction, and makes things worse instead of better.
6。第 6 个问题
According to the code, how many iterations does it take for the perceptron to converge to a solution on dataset 3 using the provided initial weight vector w_init?
Note: the program will output
Number of errors in iteration xx: 0
You simply need to report xx.
2
It doesn't converge.
6
9
The perceptron algorithm as implemented and described in class implicitly uses a learning rate of 1. We can modify the algorithm to use a different learning rate \alphaα so that the update rule for an input xx and target tt becomes:
w^{(t)} \leftarrow w^{(t-1)} + \alpha (t - \text{prediction})xw(t)←w(t−1)+α(t−prediction)x,
where \text{prediction}prediction is the decision made by the perceptron using the current weight vector w^{(t-1)}w(t−1), given by:
True or false: if we use a learning rate of 2, then the perceptron algorithm will always converge to a solution for linearly separable datasets.
True
This is equivalent to doubling the magnitude of each training example, which will not change the fact that the dataset is still linearly separable.
False
6。第 6 个问题
According to the code, how many iterations does it take for the perceptron to converge to a solution on dataset 1 using the provided initial weight vector w_init?
Note: the program will output
Number of errors in iteration xx: 0
You simply need to report xx.
5
It doesn't converge.
1
3