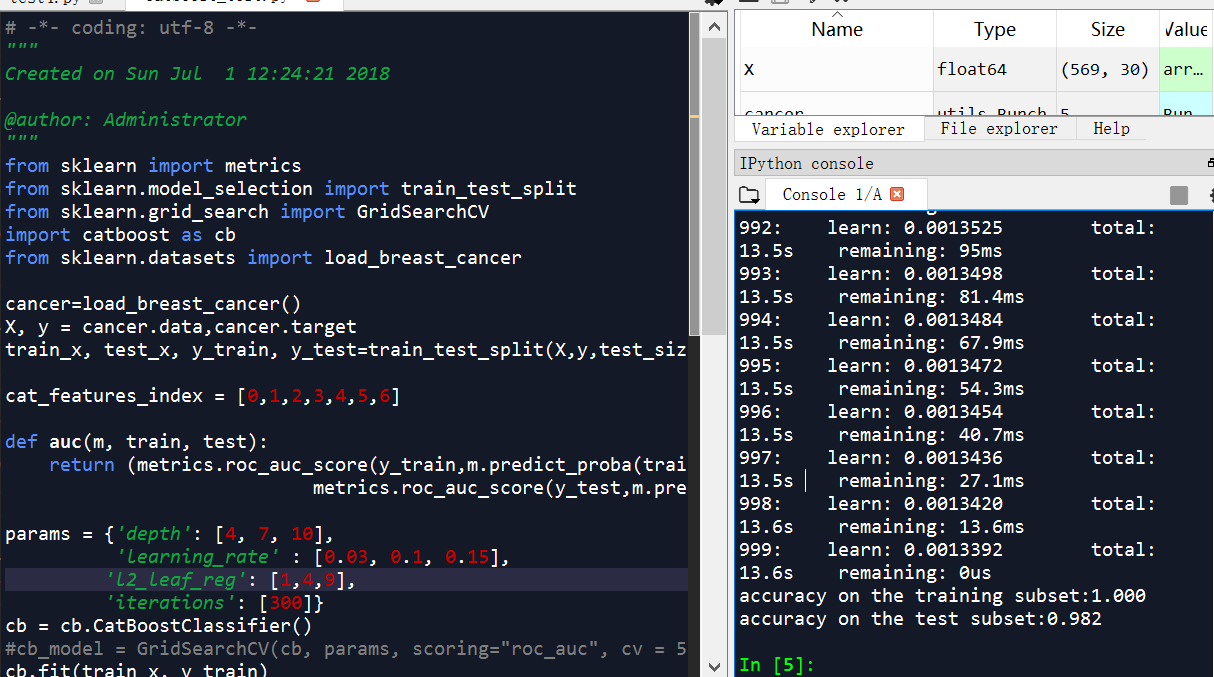
# -*- coding: utf-8 -*-
"""
Created on Sun Jul 1 12:24:21 2018
@author: Administrator
"""
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.grid_search import GridSearchCV
import catboost as cb
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
X, y = cancer.data,cancer.target
train_x, test_x, y_train, y_test=train_test_split(X,y,test_size=0.3,random_state=0)
cat_features_index = [0,1,2,3,4,5,6]
def auc(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]),
metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))
params = {'depth': [4, 7, 10],
'learning_rate' : [0.03, 0.1, 0.15],
'l2_leaf_reg': [1,4,9],
'iterations': [300]}
cb = cb.CatBoostClassifier()
#cb_model = GridSearchCV(cb, params, scoring="roc_auc", cv = 5)
cb.fit(train_x, y_train)
print("accuracy on the training subset:{:.3f}".format(cb.score(train_x,y_train)))
print("accuracy on the test subset:{:.3f}".format(cb.score(test_x,y_test)))
'''
accuracy on the training subset:1.000
accuracy on the test subset:0.982
'''
俄罗斯最大搜索引擎Yandex开源了一款梯度提升机器学习库CatBoost
摘要: 俄罗斯搜索巨头Yandex宣布,将向开源社区提交一款梯度提升机器学习库CatBoost。它能够在数据稀疏的情况下“教”机器学习。特别是在没有像视频、文本、图像这类感官型数据的时候,CatBoost也能根据事务型数据或历史数据进行操作。
关键词: 人工智能 搜索引擎 算法

现在,人工智能正在为越来越多的计算功能提供支持,今天,俄罗斯搜索巨头Yandex宣布,将向开源社区提交一款梯度提升机器学习库CatBoost。它能够在数据稀疏的情况下“教”机器学习。特别是在没有像视频、文本、图像这类感官型数据的时候,CatBoost也能根据事务型数据或历史数据进行操作。
今天,CatBoost以两种方式进行了亮相。
首先,Yandex宣布,将在自有服务中使用这款新的框架替换原来的机器学习算法MatrixNet。MatrixNet一直被应用在公司的很多业务上,比如排名、天气预报、出租车和推荐业务。现在,业务正在逐步从MatrixNet切换到CatBoost上来,并将延续几个月。
其次,Yandex将免费提供CatBoost库,任何希望在自己的程序中使用梯度提升技术的人员都可以在Apache许可证下使用这个库。 Yandex机器智能研究主管Misha Bilenko在接受采访时表示:“CatBoost是Yandex多年研究的巅峰之作。我们自己一直在使用大量的开源机器学习工具,所以是时候向社会作出回馈了。” 他提到,Google在2015年开源的Tensorflow以及Linux的建立与发展是本次开源CatBoost的原动力。
Bilenko补充说到,暂时还没有计划将CatBoost商业化,或以任何专利的形式将其闭源。 “这和竞争对手无关,”他说,“我们很高兴有竞争对手使用它”
长期以来,随着Yandex的不断发展,它一直在寻求提升俄语世界之外的国际地位。本次开源举动不仅仅是Yandex对开源社区的承诺,而且也展示了Yandex希望成为大型科技公司与开发者社区发展中心的决心。
就像Google持续地扩展和更新Tensorflow一样,今天的CatBoost版本是其第一个版本,以后将持续更新迭代。目前,这个库主要有三个特点:
“减少过度拟合”:这可以帮助你在训练计划中取得更好的成果。它基于一种构建模型的专有算法,这种算法与标准的梯度提升方案不同。
“类别特征支持”:这将改善你的训练结果,同时允许你使用非数字因素,“而不必预先处理数据,或花费时间和精力将其转化为数字。”
“API??接口支持”:可以通过命令行或者基于Python或R的API接口来使用CatBoost,包括公式分析和训练可视化工具。
虽然目前有大量的库可以利用梯度提升或其他解决方案来训练机器学习系统,但Bilenko认为,CatBoost相较其他大型公司使用的框架(如Yandex)的最大优点是测试精准度高。
“有很多机器学习库的代码质量比较差,需要做大量的调优工作,”他说,“而CatBoost只需少量调试,就可以实现良好的性能。这是一个关键性的区别。”
附CatBoost开源代码地址: https://catboost.yandex/