分词
在做文本挖掘的时候,首先要做的预处理就是分词。英文单词天然有空格隔开容易按照空格分词,但是也有时候需要把多个单词做为一个分词,比如一些名词如“New York”,需要做为一个词看待。而中文由于没有空格,分词就是一个需要专门去解决的问题了。无论是英文还是中文,分词的原理都是类似的,本文就对文本挖掘时的分词原理做一个总结。
1. 分词的基本原理
现代分词都是基于统计的分词,而统计的样本内容来自于一些标准的语料库。假如有一个句子:“小明来到荔湾区”,我们期望语料库统计后分词的结果是:"小明/来到/荔湾/区",而不是“小明/来到/荔/湾区”。那么如何做到这一点呢?
从统计的角度,我们期望"小明/来到/荔湾/区"这个分词后句子出现的概率要比“小明/来到/荔/湾区”大。如果用数学的语言来说说,如果有一个句子SS,它有m种分词选项如下:
其中下标nini代表第ii种分词的词个数。如果我们从中选择了最优的第rr种分词方法,那么这种分词方法对应的统计分布概率应该最大,即:
但是我们的概率分布P(Ai1,Ai2,...,Aini)P(Ai1,Ai2,...,Aini)并不好求出来,因为它涉及到nini个分词的联合分布。在NLP中,为了简化计算,我们通常使用马尔科夫假设,即每一个分词出现的概率仅仅和前一个分词有关,即:
在前面我们讲MCMC采样时,也用到了相同的假设来简化模型复杂度。使用了马尔科夫假设,则我们的联合分布就好求了,即:
而通过我们的标准语料库,我们可以近似的计算出所有的分词之间的二元条件概率,比如任意两个词w1,w2w1,w2,它们的条件概率分布可以近似的表示为:
其中freq(w1,w2)freq(w1,w2)表示w1,w2w1,w2在语料库中相邻一起出现的次数,而其中freq(w1),freq(w2)freq(w1),freq(w2)分别表示w1,w2w1,w2在语料库中出现的统计次数。
利用语料库建立的统计概率,对于一个新的句子,我们就可以通过计算各种分词方法对应的联合分布概率,找到最大概率对应的分词方法,即为最优分词。
2. N元模型
当然,你会说,只依赖于前一个词太武断了,我们能不能依赖于前两个词呢?即:
这样也是可以的,只不过这样联合分布的计算量就大大增加了。我们一般称只依赖于前一个词的模型为二元模型(Bi-Gram model),而依赖于前两个词的模型为三元模型。以此类推,我们可以建立四元模型,五元模型,...一直到通用的NN元模型。越往后,概率分布的计算复杂度越高。当然算法的原理是类似的。
在实际应用中,NN一般都较小,一般都小于4,主要原因是N元模型概率分布的空间复杂度为O(|V|N)O(|V|N),其中|V||V|为语料库大小,而NN为模型的元数,当NN增大时,复杂度呈指数级的增长。
NN元模型的分词方法虽然很好,但是要在实际中应用也有很多问题,首先,某些生僻词,或者相邻分词联合分布在语料库中没有,概率为0。这种情况我们一般会使用拉普拉斯平滑,即给它一个较小的概率值,这个方法在朴素贝叶斯算法原理小结也有讲到。第二个问题是如果句子长,分词有很多情况,计算量也非常大,这时我们可以用下一节维特比算法来优化算法时间复杂度。
3. 维特比算法与分词
为了简化原理描述,我们本节的讨论都是以二元模型为基础。
对于一个有很多分词可能的长句子,我们当然可以用暴力方法去计算出所有的分词可能的概率,再找出最优分词方法。但是用维特比算法可以大大简化求出最优分词的时间。
大家一般知道维特比算法是用于隐式马尔科夫模型HMM解码算法的,但是它是一个通用的求序列最短路径的方法,不光可以用于HMM,也可以用于其他的序列最短路径算法,比如最优分词。
维特比算法采用的是动态规划来解决这个最优分词问题的,动态规划要求局部路径也是最优路径的一部分,很显然我们的问题是成立的。首先我们看一个简单的分词例子:"人生如梦境"。它的可能分词可以用下面的概率图表示:
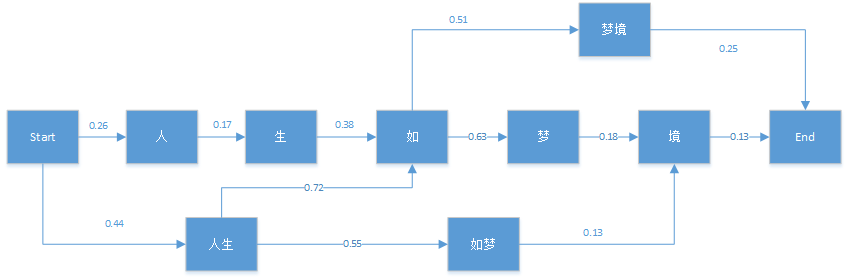
图中的箭头为通过统计语料库而得到的对应的各分词位置BEMS(开始位置,结束位置,中间位置,单词)的条件概率。比如P(生|人)=0.17。有了这个图,维特比算法需要找到从Start到End之间的一条最短路径。对于在End之前的任意一个当前局部节点,我们需要得到到达该节点的最大概率δδ,和记录到达当前节点满足最大概率的前一节点位置ΨΨ。
我们先用这个例子来观察维特比算法的过程。首先我们初始化有:
对于节点"生",它只有一个前向节点,因此有:
对于节点"如",就稍微复杂一点了,因为它有多个前向节点,我们要计算出到“如”概率最大的路径:
类似的方法可以用于其他节点如下:
最后我们看看最终节点End:
由于最后的最优解为“梦境”,现在我们开始用ΨΨ反推:
从而最终的分词结果为"人生/如/梦境"。是不是很简单呢。
由于维特比算法我会在后面讲隐式马尔科夫模型HMM解码算法时详细解释,这里就不归纳了。
4. 常用分词工具
对于文本挖掘中需要的分词功能,一般我们会用现有的工具。简单的英文分词不需要任何工具,通过空格和标点符号就可以分词了,而进一步的英文分词推荐使用nltk。对于中文分词,则推荐用结巴分词(jieba)。这些工具使用都很简单。你的分词没有特别的需求直接使用这些分词工具就可以了。
5. 结语
分词是文本挖掘的预处理的重要的一步,分词完成后,我们可以继续做一些其他的特征工程,比如向量化(vectorize),TF-IDF以及Hash trick,这些我们后面再讲。
向量化
在上文中,我们讲到了文本挖掘的预处理的关键一步:“分词”,而在做了分词后,如果我们是做文本分类聚类,则后面关键的特征预处理步骤有向量化或向量化的特例Hash Trick,本文我们就对向量化和特例Hash Trick预处理方法做一个总结。
1. 词袋模型
在讲向量化与Hash Trick之前,我们先说说词袋模型(Bag of Words,简称BoW)。词袋模型假设我们不考虑文本中词与词之间的上下文关系,仅仅只考虑所有词的权重。而权重与词在文本中出现的频率有关。
词袋模型首先会进行分词,在分词之后,通过统计每个词在文本中出现的次数,我们就可以得到该文本基于词的特征,如果将各个文本样本的这些词与对应的词频放在一起,就是我们常说的向量化。向量化完毕后一般也会使用TF-IDF进行特征的权重修正,再将特征进行标准化。 再进行一些其他的特征工程后,就可以将数据带入机器学习算法进行分类聚类了。
总结下词袋模型的三部曲:分词(tokenizing),统计修订词特征值(counting)与标准化(normalizing)。
与词袋模型非常类似的一个模型是词集模型(Set of Words,简称SoW),和词袋模型唯一的不同是它仅仅考虑词是否在文本中出现,而不考虑词频。也就是一个词在文本在文本中出现1次和多次特征处理是一样的。在大多数时候,我们使用词袋模型,后面的讨论也是以词袋模型为主。
当然,词袋模型有很大的局限性,因为它仅仅考虑了词频,没有考虑上下文的关系,因此会丢失一部分文本的语义。但是大多数时候,如果我们的目的是分类聚类,则词袋模型表现的很好。
2. 词袋模型之向量化
在词袋模型的统计词频这一步,我们会得到该文本中所有词的词频,有了词频,我们就可以用词向量表示这个文本。这里我们举一个例子,例子直接用scikit-learn的CountVectorizer类来完成,这个类可以帮我们完成文本的词频统计与向量化,代码如下:

from sklearn.feature_extraction.text import CountVectorizer vectorizer=CountVectorizer() corpus=["I come to China to travel", "This is a car polupar in China", "I love tea and Apple ", "The work is to write some papers in science"] print vectorizer.fit_transform(corpus)
我们看看对于上面4个文本的处理输出如下:
可以看出4个文本的词频已经统计出,在输出中,左边的括号中的第一个数字是文本的序号,第2个数字是词的序号,注意词的序号是基于所有的文档的。第三个数字就是我们的词频。
我们可以进一步看看每个文本的词向量特征和各个特征代表的词,代码如下:
print vectorizer.fit_transform(corpus).toarray() print vectorizer.get_feature_names()
输出如下:
[[0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 2 1 0 0] [0 0 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0] [1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0] [0 0 0 0 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1]] [u'and', u'apple', u'car', u'china', u'come', u'in', u'is', u'love', u'papers', u'polupar', u'science', u'some', u'tea', u'the', u'this', u'to', u'travel', u'work', u'write']
可以看到我们一共有19个词,所以4个文本都是19维的特征向量。而每一维的向量依次对应了下面的19个词。另外由于词"I"在英文中是停用词,不参加词频的统计。
由于大部分的文本都只会使用词汇表中的很少一部分的词,因此我们的词向量中会有大量的0。也就是说词向量是稀疏的。在实际应用中一般使用稀疏矩阵来存储。
将文本做了词频统计后,我们一般会通过TF-IDF进行词特征值修订,这部分我们后面再讲。
向量化的方法很好用,也很直接,但是在有些场景下很难使用,比如分词后的词汇表非常大,达到100万+,此时如果我们直接使用向量化的方法,将对应的样本对应特征矩阵载入内存,有可能将内存撑爆,在这种情况下我们怎么办呢?第一反应是我们要进行特征的降维,说的没错!而Hash Trick就是非常常用的文本特征降维方法。
3. Hash Trick
在大规模的文本处理中,由于特征的维度对应分词词汇表的大小,所以维度可能非常恐怖,此时需要进行降维,不能直接用我们上一节的向量化方法。而最常用的文本降维方法是Hash Trick。说到Hash,一点也不神秘,学过数据结构的同学都知道。这里的Hash意义也类似。
在Hash Trick里,我们会定义一个特征Hash后对应的哈希表的大小,这个哈希表的维度会远远小于我们的词汇表的特征维度,因此可以看成是降维。具体的方法是,对应任意一个特征名,我们会用Hash函数找到对应哈希表的位置,然后将该特征名对应的词频统计值累加到该哈希表位置。如果用数学语言表示,假如哈希函数hh使第ii个特征哈希到位置jj,即h(i)=jh(i)=j,则第ii个原始特征的词频数值ϕ(i)ϕ(i)将累加到哈希后的第jj个特征的词频数值ϕ¯ϕ¯上,即:
其中JJ是原始特征的维度。
但是上面的方法有一个问题,有可能两个原始特征的哈希后位置在一起导致词频累加特征值突然变大,为了解决这个问题,出现了hash Trick的变种signed hash trick,此时除了哈希函数hh,我们多了一个一个哈希函数:
此时我们有
这样做的好处是,哈希后的特征仍然是一个无偏的估计,不会导致某些哈希位置的值过大。
当然,大家会有疑惑,这种方法来处理特征,哈希后的特征是否能够很好的代表哈希前的特征呢?从实际应用中说,由于文本特征的高稀疏性,这么做是可行的。如果大家对理论上为何这种方法有效,建议参考论文:Feature hashing for large scale multitask learning.这里就不多说了。
在scikit-learn的HashingVectorizer类中,实现了基于signed hash trick的算法,这里我们就用HashingVectorizer来实践一下Hash Trick,为了简单,我们使用上面的19维词汇表,并哈希降维到6维。当然在实际应用中,19维的数据根本不需要Hash Trick,这里只是做一个演示,代码如下:
from sklearn.feature_extraction.text import HashingVectorizer vectorizer2=HashingVectorizer(n_features = 6,norm = None) print vectorizer2.fit_transform(corpus)
输出如下:
(0, 1) 2.0 (0, 2) -1.0 (0, 4) 1.0 (0, 5) -1.0 (1, 0) 1.0 (1, 1) 1.0 (1, 2) -1.0 (1, 5) -1.0 (2, 0) 2.0 (2, 5) -2.0 (3, 0) 0.0 (3, 1) 4.0 (3, 2) -1.0 (3, 3) 1.0 (3, 5) -1.0
大家可以看到结果里面有负数,这是因为我们的哈希函数ξξ可以哈希到1或者-1导致的。
和PCA类似,Hash Trick降维后的特征我们已经不知道它代表的特征名字和意义。此时我们不能像上一节向量化时候可以知道每一列的意义,所以Hash Trick的解释性不强。
4. 向量化与Hash Trick小结
这里我们对向量化与它的特例Hash Trick做一个总结。在特征预处理的时候,我们什么时候用一般意义的向量化,什么时候用Hash Trick呢?标准也很简单。
一般来说,只要词汇表的特征不至于太大,大到内存不够用,肯定是使用一般意义的向量化比较好。因为向量化的方法解释性很强,我们知道每一维特征对应哪一个词,进而我们还可以使用TF-IDF对各个词特征的权重修改,进一步完善特征的表示。
而Hash Trick用大规模机器学习上,此时我们的词汇量极大,使用向量化方法内存不够用,而使用Hash Trick降维速度很快,降维后的特征仍然可以帮我们完成后续的分类和聚类工作。当然由于分布式计算框架的存在,其实一般我们不会出现内存不够的情况。因此,实际工作中我使用的都是特征向量化。
向量化与Hash Trick就介绍到这里,下一篇我们讨论TF-IDF。
TF-IDF概述
在上文中我们讲到在文本挖掘的预处理中,向量化之后一般都伴随着TF-IDF的处理,那么什么是TF-IDF,为什么一般我们要加这一步预处理呢?这里就对TF-IDF的原理做一个总结。
1. 文本向量化特征的不足
在将文本分词并向量化后,我们可以得到词汇表中每个词在各个文本中形成的词向量,比如在文本挖掘预处理之向量化与Hash Trick这篇文章中,我们将下面4个短文本做了词频统计:
corpus=["I come to China to travel", "This is a car polupar in China", "I love tea and Apple ", "The work is to write some papers in science"]
不考虑停用词,处理后得到的词向量如下:
[[0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 2 1 0 0] [0 0 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0] [1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0] [0 0 0 0 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1]]
如果我们直接将统计词频后的19维特征做为文本分类的输入,会发现有一些问题。比如第一个文本,我们发现"come","China"和“Travel”各出现1次,而“to“出现了两次。似乎看起来这个文本与”to“这个特征更关系紧密。但是实际上”to“是一个非常普遍的词,几乎所有的文本都会用到,因此虽然它的词频为2,但是重要性却比词频为1的"China"和“Travel”要低的多。如果我们的向量化特征仅仅用词频表示就无法反应这一点。因此我们需要进一步的预处理来反应文本的这个特征,而这个预处理就是TF-IDF。
2. TF-IDF概述
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由两部分组成,TF和IDF。
前面的TF也就是我们前面说到的词频,我们之前做的向量化也就是做了文本中各个词的出现频率统计,并作为文本特征,这个很好理解。关键是后面的这个IDF,即“逆文本频率”如何理解。在上一节中,我们讲到几乎所有文本都会出现的"to"其词频虽然高,但是重要性却应该比词频低的"China"和“Travel”要低。我们的IDF就是来帮助我们来反应这个词的重要性的,进而修正仅仅用词频表示的词特征值。
概括来讲, IDF反应了一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低,比如上文中的“to”。而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。比如一些专业的名词如“Machine Learning”。这样的词IDF值应该高。一个极端的情况,如果一个词在所有的文本中都出现,那么它的IDF值应该为0。
上面是从定性上说明的IDF的作用,那么如何对一个词的IDF进行定量分析呢?这里直接给出一个词xx的IDF的基本公式如下:
其中,NN代表语料库中文本的总数,而N(x)N(x)代表语料库中包含词xx的文本总数。为什么IDF的基本公式应该是是上面这样的而不是像N/N(x)N/N(x)这样的形式呢?这就涉及到信息论相关的一些知识了。感兴趣的朋友建议阅读吴军博士的《数学之美》第11章。
上面的IDF公式已经可以使用了,但是在一些特殊的情况会有一些小问题,比如某一个生僻词在语料库中没有,这样我们的分母为0, IDF没有意义了。所以常用的IDF我们需要做一些平滑,使语料库中没有出现的词也可以得到一个合适的IDF值。平滑的方法有很多种,最常见的IDF平滑后的公式之一为:
有了IDF的定义,我们就可以计算某一个词的TF-IDF值了:
其中TF(x)TF(x)指词xx在当前文本中的词频。
3. 用scikit-learn进行TF-IDF预处理
在scikit-learn中,有两种方法进行TF-IDF的预处理。
第一种方法是在用CountVectorizer类向量化之后再调用TfidfTransformer类进行预处理。第二种方法是直接用TfidfVectorizer完成向量化与TF-IDF预处理。
首先我们来看第一种方法,CountVectorizer+TfidfTransformer的组合,代码如下:
from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer corpus=["I come to China to travel", "This is a car polupar in China", "I love tea and Apple ", "The work is to write some papers in science"] vectorizer=CountVectorizer() transformer = TfidfTransformer() tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus)) print tfidf
输出的各个文本各个词的TF-IDF值如下:
(0, 4) 0.442462137895 (0, 15) 0.697684463384 (0, 3) 0.348842231692 (0, 16) 0.442462137895 (1, 3) 0.357455043342 (1, 14) 0.453386397373 (1, 6) 0.357455043342 (1, 2) 0.453386397373 (1, 9) 0.453386397373 (1, 5) 0.357455043342 (2, 7) 0.5 (2, 12) 0.5 (2, 0) 0.5 (2, 1) 0.5 (3, 15) 0.281131628441 (3, 6) 0.281131628441 (3, 5) 0.281131628441 (3, 13) 0.356579823338 (3, 17) 0.356579823338 (3, 18) 0.356579823338 (3, 11) 0.356579823338 (3, 8) 0.356579823338 (3, 10) 0.356579823338
现在我们用TfidfVectorizer一步到位,代码如下:
from sklearn.feature_extraction.text import TfidfVectorizer tfidf2 = TfidfVectorizer() re = tfidf2.fit_transform(corpus) print re
输出的各个文本各个词的TF-IDF值和第一种的输出完全相同。大家可以自己去验证一下。
由于第二种方法比较的简洁,因此在实际应用中推荐使用,一步到位完成向量化,TF-IDF与标准化。
4. TF-IDF小结
TF-IDF是非常常用的文本挖掘预处理基本步骤,但是如果预处理中使用了Hash Trick,则一般就无法使用TF-IDF了,因为Hash Trick后我们已经无法得到哈希后的各特征的IDF的值。使用了IF-IDF并标准化以后,我们就可以使用各个文本的词特征向量作为文本的特征,进行分类或者聚类分析。
当然TF-IDF不光可以用于文本挖掘,在信息检索等很多领域都有使用。因此值得好好的理解这个方法的思想。
流程总结
在对文本做数据分析时,我们一大半的时间都会花在文本预处理上,而中文和英文的预处理流程稍有不同,本文就对中文文本挖掘的预处理流程做一个总结。
1. 中文文本挖掘预处理特点
首先我们看看中文文本挖掘预处理和英文文本挖掘预处理相比的一些特殊点。
首先,中文文本是没有像英文的单词空格那样隔开的,因此不能直接像英文一样可以直接用最简单的空格和标点符号完成分词。所以一般我们需要用分词算法来完成分词,在文本挖掘的分词原理中,我们已经讲到了中文的分词原理,这里就不多说。
第二,中文的编码不是utf8,而是unicode。这样会导致在分词的时候,和英文相比,我们要处理编码的问题。
这两点构成了中文分词相比英文分词的一些不同点,后面我们也会重点讲述这部分的处理。当然,英文分词也有自己的烦恼,这个我们在以后再讲。了解了中文预处理的一些特点后,我们就言归正传,通过实践总结下中文文本挖掘预处理流程。
2. 中文文本挖掘预处理一:数据收集
在文本挖掘之前,我们需要得到文本数据,文本数据的获取方法一般有两种:使用别人做好的语料库和自己用爬虫去在网上去爬自己的语料数据。
对于第一种方法,常用的文本语料库在网上有很多,如果大家只是学习,则可以直接下载下来使用,但如果是某些特殊主题的语料库,比如“机器学习”相关的语料库,则这种方法行不通,需要我们自己用第二种方法去获取。
对于第二种使用爬虫的方法,开源工具有很多,通用的爬虫我一般使用beautifulsoup。但是我们我们需要某些特殊的语料数据,比如上面提到的“机器学习”相关的语料库,则需要用主题爬虫(也叫聚焦爬虫)来完成。这个我一般使用ache。 ache允许我们用关键字或者一个分类算法来过滤出我们需要的主题语料,比较强大。
3. 中文文本挖掘预处理二:除去数据中非文本部分
这一步主要是针对我们用爬虫收集的语料数据,由于爬下来的内容中有很多html的一些标签,需要去掉。少量的非文本内容的可以直接用Python的正则表达式(re)删除, 复杂的则可以用beautifulsoup来去除。去除掉这些非文本的内容后,我们就可以进行真正的文本预处理了。
4. 中文文本挖掘预处理三:处理中文编码问题
由于Python2不支持unicode的处理,因此我们使用Python2做中文文本预处理时需要遵循的原则是,存储数据都用utf8,读出来进行中文相关处理时,使用GBK之类的中文编码,在下面一节的分词时,我们再用例子说明这个问题。
5. 中文文本挖掘预处理四:中文分词
常用的中文分词软件有很多,个人比较推荐结巴分词。安装也很简单,比如基于Python的,用"pip install jieba"就可以完成。下面我们就用例子来看看如何中文分词。
首先我们准备了两段文本,这两段文本在两个文件中。两段文本的内容分别是nlp_test0.txt和nlp_test2.txt:
沙瑞金赞叹易学习的胸怀,是金山的百姓有福,可是这件事对李达康的触动很大。易学习又回忆起他们三人分开的前一晚,大家一起喝酒话别,易学习被降职到道口县当县长,王大路下海经商,李达康连连赔礼道歉,觉得对不起大家,他最对不起的是王大路,就和易学习一起给王大路凑了5万块钱,王大路自己东挪西撮了5万块,开始下海经商。没想到后来王大路竟然做得风生水起。沙瑞金觉得他们三人,在困难时期还能以沫相助,很不容易。
沙瑞金向毛娅打听他们家在京州的别墅,毛娅笑着说,王大路事业有成之后,要给欧阳菁和她公司的股权,她们没有要,王大路就在京州帝豪园买了三套别墅,可是李达康和易学习都不要,这些房子都在王大路的名下,欧阳菁好像去住过,毛娅不想去,她觉得房子太大很浪费,自己家住得就很踏实。
我们先讲文本从第一个文件中读取,并使用中文GBK编码,再调用结巴分词,最后把分词结果用uft8格式存在另一个文本nlp_test1.txt
中。代码如下:
# -*- coding: utf-8 -*- import jieba with open('./nlp_test0.txt') as f: document = f.read() document_decode = document.decode('GBK') document_cut = jieba.cut(document_decode) #print ' '.join(jieba_cut) //如果打印结果,则分词效果消失,后面的result无法显示 result = ' '.join(document_cut) result = result.encode('utf-8') with open('./nlp_test1.txt', 'w') as f2: f2.write(result) f.close() f2.close()
输出的文本内容如下:
沙 瑞金 赞叹 易 学习 的 胸怀 , 是 金山 的 百姓 有福 , 可是 这件 事对 李达康 的 触动 很大 。 易 学习 又 回忆起 他们 三人 分开 的 前一晚 , 大家 一起 喝酒 话别 , 易 学习 被 降职 到 道口 县当 县长 , 王 大路 下海经商 , 李达康 连连 赔礼道歉 , 觉得 对不起 大家 , 他 最 对不起 的 是 王 大路 , 就 和 易 学习 一起 给 王 大路 凑 了 5 万块 钱 , 王 大路 自己 东挪西撮 了 5 万块 , 开始 下海经商 。 没想到 后来 王 大路 竟然 做 得 风生水 起 。 沙 瑞金 觉得 他们 三人 , 在 困难 时期 还 能 以沫 相助 , 很 不 容易 。
可以发现对于一些人名和地名,jieba处理的不好,不过我们可以帮jieba加入词汇如下:
jieba.suggest_freq('沙瑞金', True) jieba.suggest_freq('易学习', True) jieba.suggest_freq('王大路', True) jieba.suggest_freq('京州', True)
现在我们再来进行读文件,编码,分词,编码和写文件,代码如下:
with open('./nlp_test0.txt') as f: document = f.read() document_decode = document.decode('GBK') document_cut = jieba.cut(document_decode) #print ' '.join(jieba_cut) result = ' '.join(document_cut) result = result.encode('utf-8') with open('./nlp_test1.txt', 'w') as f2: f2.write(result) f.close() f2.close()
输出的文本内容如下:
沙瑞金 赞叹 易学习 的 胸怀 , 是 金山 的 百姓 有福 , 可是 这件 事对 李达康 的 触动 很大 。 易学习 又 回忆起 他们 三人 分开 的 前一晚 , 大家 一起 喝酒 话别 , 易学习 被 降职 到 道口 县当 县长 , 王大路 下海经商 , 李达康 连连 赔礼道歉 , 觉得 对不起 大家 , 他 最 对不起 的 是 王大路 , 就 和 易学习 一起 给 王大路 凑 了 5 万块 钱 , 王大路 自己 东挪西撮 了 5 万块 , 开始 下海经商 。 没想到 后来 王大路 竟然 做 得 风生水 起 。 沙瑞金 觉得 他们 三人 , 在 困难 时期 还 能 以沫 相助 , 很 不 容易 。
基本已经可以满足要求。同样的方法我们对第二段文本nlp_test2.txt进行分词和写入文件nlp_test3.txt。
with open('./nlp_test2.txt') as f: document2 = f.read() document2_decode = document2.decode('GBK') document2_cut = jieba.cut(document2_decode) #print ' '.join(jieba_cut) result = ' '.join(document2_cut) result = result.encode('utf-8') with open('./nlp_test3.txt', 'w') as f2: f2.write(result) f.close() f2.close()
输出的文本内容如下:
沙瑞金 向 毛娅 打听 他们 家 在 京州 的 别墅 , 毛娅 笑 着 说 , 王大路 事业有成 之后 , 要 给 欧阳 菁 和 她 公司 的 股权 , 她们 没有 要 , 王大路 就 在 京州 帝豪园 买 了 三套 别墅 , 可是 李达康 和 易学习 都 不要 , 这些 房子 都 在 王大路 的 名下 , 欧阳 菁 好像 去 住 过 , 毛娅 不想 去 , 她 觉得 房子 太大 很 浪费 , 自己 家住 得 就 很 踏实 。
可见分词效果还不错。
6. 中文文本挖掘预处理五:引入停用词
在上面我们解析的文本中有很多无效的词,比如“着”,“和”,还有一些标点符号,这些我们不想在文本分析的时候引入,因此需要去掉,这些词就是停用词。常用的中文停用词表是1208个,下载地址在这。当然也有其他版本的停用词表,不过这个1208词版是我常用的。
在我们用scikit-learn做特征处理的时候,可以通过参数stop_words来引入一个数组作为停用词表。
现在我们将停用词表从文件读出,并切分成一个数组备用:
#从文件导入停用词表 stpwrdpath = "stop_words.txt" stpwrd_dic = open(stpwrdpath, 'rb') stpwrd_content = stpwrd_dic.read() #将停用词表转换为list stpwrdlst = stpwrd_content.splitlines() stpwrd_dic.close()
7. 中文文本挖掘预处理六:特征处理
现在我们就可以用scikit-learn来对我们的文本特征进行处理了,在文本挖掘预处理之向量化与Hash Trick中,我们讲到了两种特征处理的方法,向量化与Hash Trick。而向量化是最常用的方法,因为它可以接着进行TF-IDF的特征处理。在文本挖掘预处理之TF-IDF中,我们也讲到了TF-IDF特征处理的方法。这里我们就用scikit-learn的TfidfVectorizer类来进行TF-IDF特征处理。
TfidfVectorizer类可以帮助我们完成向量化,TF-IDF和标准化三步。当然,还可以帮我们处理停用词。
现在我们把上面分词好的文本载入内存:
with open('./nlp_test1.txt') as f3: res1 = f3.read() print res1 with open('./nlp_test3.txt') as f4: res2 = f4.read() print res2
这里的输出还是我们上面分完词的文本。现在我们可以进行向量化,TF-IDF和标准化三步处理了。注意,这里我们引入了我们上面的停用词表。
from sklearn.feature_extraction.text import TfidfVectorizer corpus = [res1,res2] vector = TfidfVectorizer(stop_words=stpwrdlst) tfidf = vector.fit_transform(corpus) print tfidf
部分输出如下:
(0, 44) 0.154467434933 (0, 59) 0.108549295069 (0, 39) 0.308934869866 (0, 53) 0.108549295069 .... (1, 27) 0.139891059658 (1, 47) 0.139891059658 (1, 30) 0.139891059658 (1, 60) 0.139891059658
我们再来看看每次词和TF-IDF的对应关系:
wordlist = vector.get_feature_names()#获取词袋模型中的所有词 # tf-idf矩阵 元素a[i][j]表示j词在i类文本中的tf-idf权重 weightlist = tfidf.toarray() #打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重 for i in range(len(weightlist)): print "-------第",i,"段文本的词语tf-idf权重------" for j in range(len(wordlist)): print wordlist[j],weightlist[i][j]
部分输出如下:
-------第 0 段文本的词语tf-idf权重------ 一起 0.217098590137 万块 0.217098590137 三人 0.217098590137 三套 0.0 下海经商 0.217098590137 ..... -------第 1 段文本的词语tf-idf权重------ ..... 李达康 0.0995336411066 欧阳 0.279782119316 毛娅 0.419673178975 沙瑞金 0.0995336411066 没想到 0.0 没有 0.139891059658 浪费 0.139891059658 王大路 0.29860092332 .....
8. 中文文本挖掘预处理七:建立分析模型
有了每段文本的TF-IDF的特征向量,我们就可以利用这些数据建立分类模型,或者聚类模型了,或者进行主题模型的分析。比如我们上面的两段文本,就可以是两个训练样本了。此时的分类聚类模型和之前讲的非自然语言处理的数据分析没有什么两样。因此对应的算法都可以直接使用。而主题模型是自然语言处理比较特殊的一块,这个我们后面再单独讲。
9.中文文本挖掘预处理总结
上面我们对中文文本挖掘预处理的过程做了一个总结,希望可以帮助到大家。需要注意的是这个流程主要针对一些常用的文本挖掘,并使用了词袋模型,对于某一些自然语言处理的需求则流程需要修改。比如我们涉及到词上下文关系的一些需求,此时不能使用词袋模型。而有时候我们对于特征的处理有自己的特殊需求,因此这个流程仅供自然语言处理入门者参考。