第一节 词的过滤,Removing Stop Words
对于NLP应用,通常先把通用词、出现频率很低的词汇过滤掉
这其实类似于特征筛选的过程
在英文中,比如 the, an,their这些都可以作为停用词来处理,但是也需要考虑自己的应用场景。
NLTK提供了停用词库,可以根据具体场景选择加入或删掉一些停用词。
Low Frequency Words
出现频率特别低的词汇对分析作用不大,一般也会去掉。把通用词和低频词过滤之后,即可以得到一个词典库。
词得标准化操作:
- stemming
- lenimazation
1、Stemming:one way to normalize

词的标准化:把相同意思的单词转为一个单词
-went,go,going-----> go
- fly,flies----------->fli
- deny,denied,denying--------->deni
不能保证还原后的单词是一个有效的原型。
应用最广泛的:PorterStemmer
给定很多词形转变的规则,按照给定的规则进行转换

2、lemmatization
保证生成的原型单词一定符合文法,一定存在在词典中。
第二节:Word Representation——文本的表示
- 如何用向量表达一个单词
- 如何用向量表达一个sequence/document
1、one-hot encoding:单词的表示
向量的维度-词典的大小:词典中单词的个数

2、Sentence Representation(boolean)
boolean representation只用1和0表示字典中的词是否在句子中出现,不考虑每个词出现的次数。出现即为1,没出现为0 。

3、Count-based representation
统计词典中的词在句子中出现的次数,建立一个n维的vector,n为词典中的单词个数。

4、Sentence Similarity:如何判断两个句子/两个单词之间的相似度
计算欧氏距离
距离越小,相似度越高。反之。
将两个句子的vector中的对应元素相减做平方,求累加和。针对词不一样的位置计算距离。

计算余弦相似度,考虑文本距离和方向
余弦相似度的判定:
- 余弦相似度越大,相似度越大
- 余弦相似度越小,相似度越小
主要看的是两个word vector相交的部分。

5、Weakness of Sentence Similarity using cosine similarity or counted based representation:
- 词频不能完全反映单词在sentence中的重要性
- 并不是出现的越少就越不重要

6、tf-idf
$$ t f i d f ( w ) = t f ( d , w ) ∗ i d f ( w ) tfidf(w)=tf(d,w)*idf(w) tfidf(w)=tf(d,w)∗idf(w)
- tf(d,w): 文档d中w的词频,这部分和count-based representation 一样
- idf(w): log(N/(N(w)) 考虑单词的重要性
- N: 语料库中的文档总数
- N(w): 词与w出现在多少个文档?
如果对于一个词,出现在其他文档的次数越少,说明对于这个词对于当前文档越重要。
加入log是不希望值太大,可能文档总数很大。
tf-idf example:
- 1、定义词典库
- 2、计算每个文档中每个词的tfidf(w)

Measure Similarity between words
one-hot encoding
- boolean-based representation
- count-based representation
- tf-idf-based representation
similarity:
- 欧氏距离
- 余弦相似度
7、词向量介绍—— Distributed Representation
使用one-hot encoding无法表达两个单词之间的相似度的。
one-hot encoding 的问题:
- sparsity,如果词典中单词数量太多,它的矩阵size太大,且稀疏。
- 不能表示单词之间的相似度。
- 也不能解决一词多义的问题
7.1 Distributed Representation,针对于单词的叫做word vectors
- word vector的长度只有100,200,300维
- 不是稀疏矩阵

在distributed representation下,词与词的相似度反映了两个词之间的关联性,如,运动与爬山之间的相似度大于我们和爬山。在样本空间中,具有部分相同,或词性接近的两个词会落在一定范围的空间中。cat,tiger,运动,爬山等。

7.2 Comparing the capacities
从容量空间评价one-hot和word vector
- Q: 100维的one-hot表示法可以最多表达多少个不同的单词?
A:100个不同的单子 - Q: 100维的分布式表示法最多可以表达多少个不同的单词?
A:加入word vector的值是binary的,即只有0,1表示,则有 2 1 00 2^100 2100个单词可以用100维的分布表达。
8、学习word embeddings
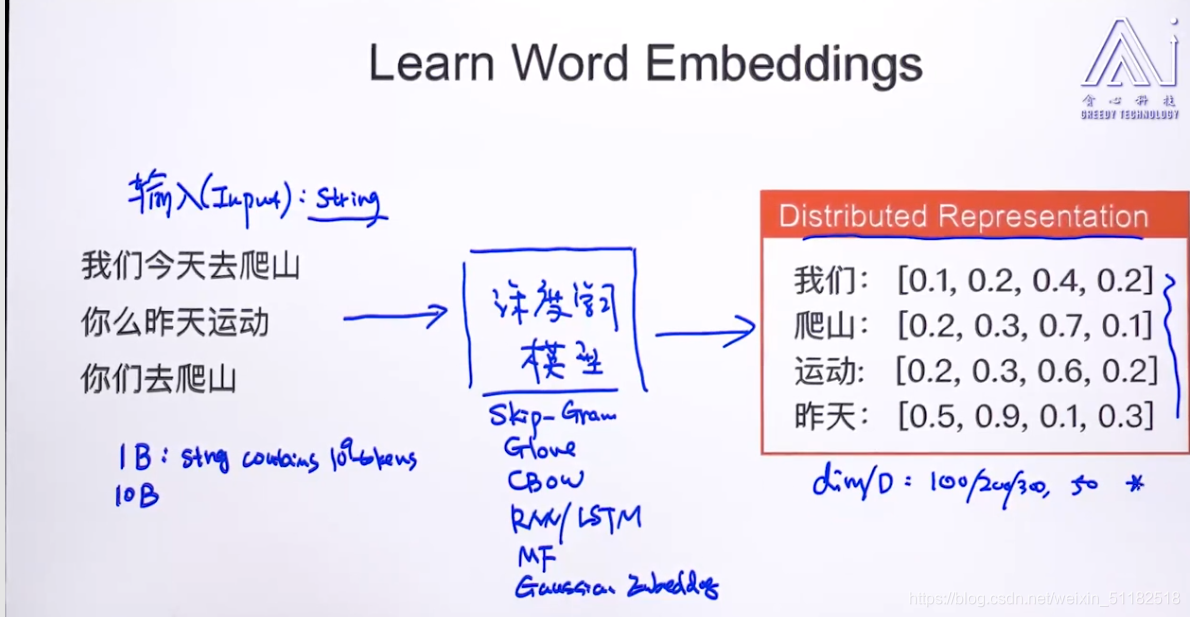
- 要确定的参数:Dims of word vector: 100/200/300?
- 要输入一个很庞大的string作为input输入
足够多的数据
- 面对一些特定的领域,需要自己去训练词向量。
- Glove/skip-gram/RNN&LSTM等分词库
8.1 词向量的本质——Essence of word Embedding:represent word meaning
词向量代表单词的意思(meaning)

意思相近的单词聚在一起,定位在相近的空间维度中。
e.g: woman-man=girl-boy
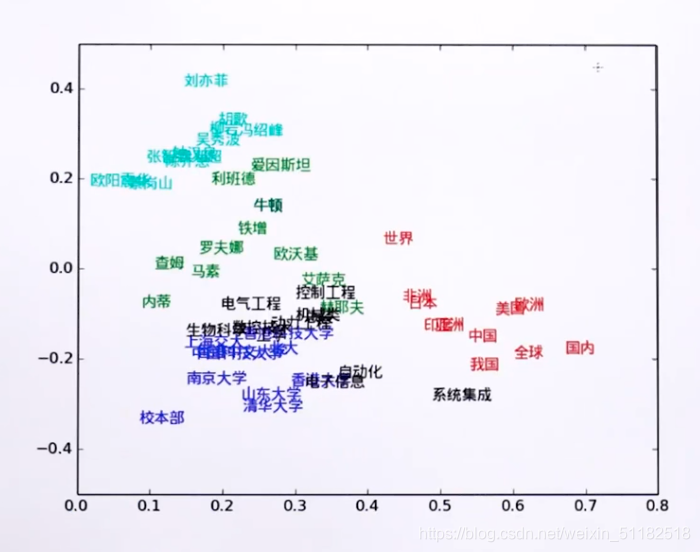
word vectors的每一个dim会代表着单词的某种特性或者意义。
8.2 From word embedding to sentence embedding
-
Average 法则

计算两个sentence embedding 之间的余弦相似度 -
LSTM/RNN