读取文本文件
读取文本文件的时候会遇到一些问题,比如一个单词在句末未拼写完整,一般会用换行符连接到下行。如果我们不特别处理,直接将每一行加空格连接成一句话会造成这个单词被切断。之后在处理tfidf的时候,可能会因为分词问题带来误差。举个例子:
import re patternBar = re.compile(r'(.+)(- ){1}$') #匹配句末的连字符 lines = ['Language-Independent Morphological Analy- ', 'sis This paper proposes a framework of language indep- ', 'endent morphological analysis and mainly conce-ntrate ', 'on tokenization, the-first-process of morphological an- ', 'alysis.'] tempAbstract = '' for line in lines: findBar = re.search(patternBar, line) if findBar: #除去连字符,和空格 tempAbstract += findBar.group(1) else: #除去'\n'换行符,保留空格 tempAbstract += line.rstrip('\n')
输出结果如下,可见每行句中的连字符并没有被去掉,而行末的都被删去了,分离的词变成了完整的词,有利于接下来进行分词,去停用词,词干化等操作:
tempAbstract Out[68]: 'Language-Independent Morphological Analysis This paper proposes a framework of language independent morphological analysis and mainly conce-ntrate on tokenization, the-first-process of morphological analysis.'
再试一下不考虑连字符的情况,觉得这重要的词汇都被分隔开,根本没法用了:
for line in lines: tempAbstract += line.rstrip('\n') tempAbstract Out[73]: 'Language-Independent Morphological Analy- sis This paper proposes a framework of language indep- endent morphological analysis and mainly conce-ntrate on tokenization, the-first-process of morpholog-ical an- alysis.'
构造停用词列表
在构建向量空间模型时,我们首先要分词,去除停用词,词干化。为了方便我们直接用nltk库和string库中的现有内容即可:
import nltk import string stopwords = nltk.corpus.stopwords.words('english') punctuations = [i for i in strinsg.punctuation] alphabet = list(string.ascii_lowercase) setStopwords = set(punctuations + stopwords + alphabet)
构造词袋模型
词袋模型,即向量的稀疏表示。我们需要先对文档库中的每一个句子进行分词,去停用词,词根化。结果如下:
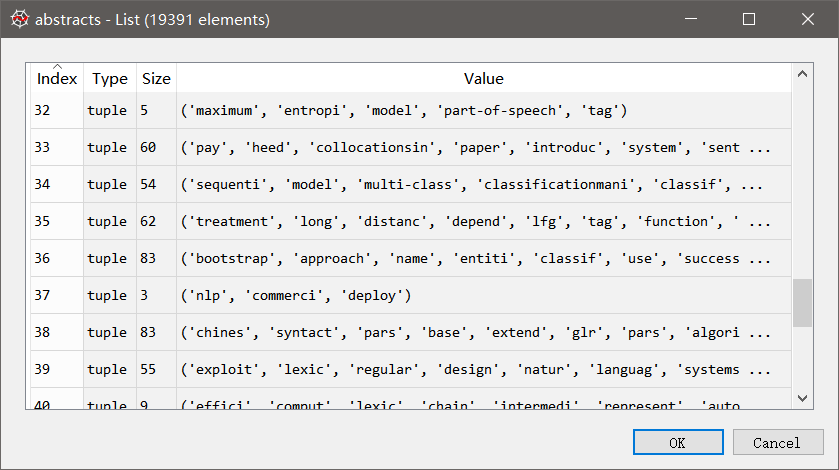
我们再以abstacts作为语料库构造字典:
dictionary = corpora.Dictionary(abstracts) bowCorpus = [dictionary.doc2bow(abstract) for abstract in abstracts]
此时的bowCorpus就是语料库的词袋模型,其中每一个子列表表示一个句子,每个子列表中由一个个元组组成。元组的第一个元素为该单词在字典dictionary中对应的索引,这里我们可以将它来理解为接下来我们将要构造的向量空间中的“维度”,第二个元素即是词频,我们可以理解为该句子在向量空间中的该“维度”上的投影值。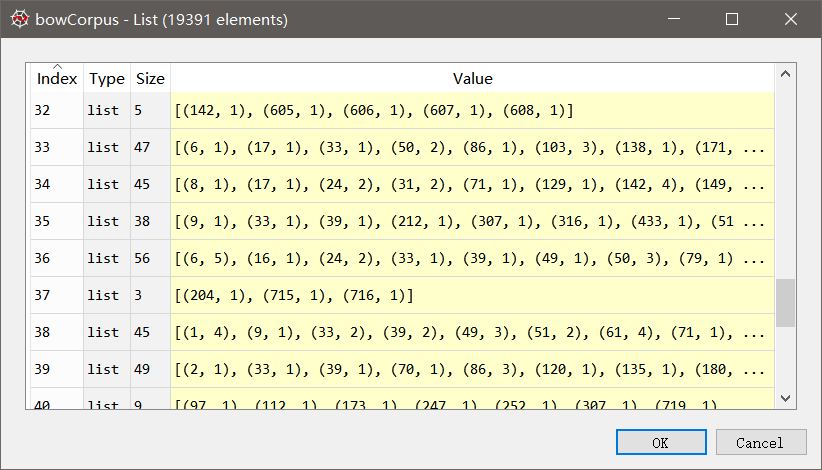
仔细想一下,这和前面提到的稀疏矩阵还蛮像的。这里只需要将向量空间中文本向量投影非零的维度,以及该维度上的权重表示出来即可。
构造向量空间模型
利用当前语料库的BOW模型,来训练出一个TF-IDF模型。这个操作很简单,载入gensim模块,一句话就搞定了:
from gensim import corpora, models, similarities tfidf = models.TfidfModel(bowCorpus) #当然还可以保存,载入模型 tfidf.save("./model.tfidf") tfidf = models.TfidfModel.load("./model.tfidf")
当然,现在模型训练好了,想要得到某一个句子的句子向量应该怎么做呢?需要传入该句子的词袋模型作为索引,来得到该句子的向量空间模型。
#由之前构造的语料库词袋模型中获取第33个句子的词袋模型,作为索引传入tfidf模型 tfidfSent = tfidf[bowCorpus[32]]
结果如下图所示,可见,还是此时向量空间中的句子向量仍然是稀疏表示的。
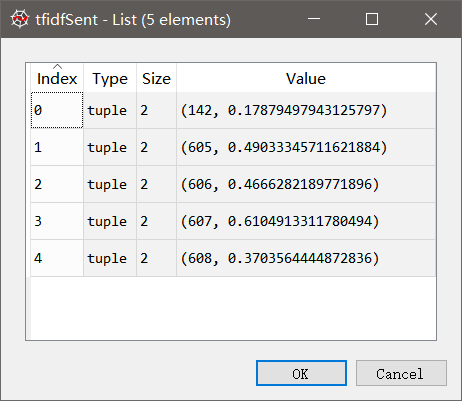
此时以句子的tfidf模型构造其之间的相似度矩阵:
#确定维度,即为词袋模型中特征词项个数 numFeature = len(dictionary.token2id.keys()) index = similarities.SparseMatrixSimilarity(tfidfCorpus, num_features=numFeature)
构建了相似度索引矩阵之后不能直接拿来用,同样的我们需要传入一个句子的TFIDF向量模型,来获取该句子与所有句子之间的相似度关系(以向量来储存),我们以之前的摘要为例:
tempAbstract Out[68]: 'Language Independent Morphological Analysis This paper proposes a framework of language independent morphological analysis and mainly concentrate on tokenization, the first process of morphological analysis.' query = tempAbstract #先处理该查询文本,分词,去停用词,词干化 porter = nltk.PorterStemmer() textQuery = [porter.stem(t) for t in nltk.word_tokenize(query) if t.lower() not in stopwords] #利用已经构造的dictionary来构造查询的bow模型 bowQuery = dictionary.doc2bow(textQuery) #利用bow模型和训练好的tfidf模型,得到查询的向量空间模型 tfidf = models.TfidfModel.load("./model.tfidf") tfidfQuery = tfidf[bowQuery] #向索引矩阵中传入以tfidf为权重的向量 relPQ = index[tfidfQuery]
结果如下,句子预处理之后的结果,以及构造的词袋模型,以及向量空间中的表示: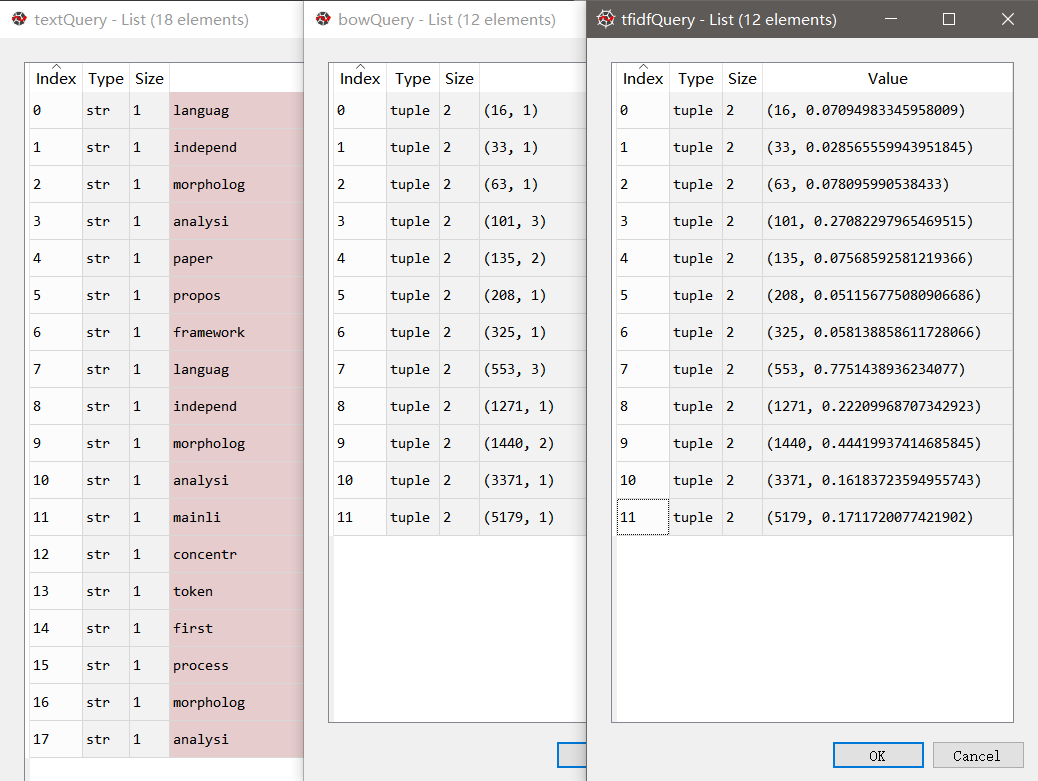
tfidfQuery中的各个元组,第一个元素表示向量空间中的对应维度,第二个元素为该维度上的权重。是一种稀疏表示,如果在该维度上投影为零,不再记录。
接下来获取该查询与语料库中的每一个句子之间的相似度:
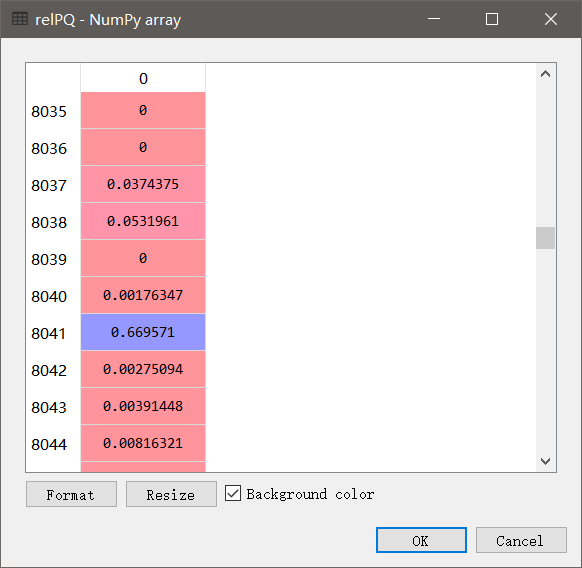
rel = index[tfidfQuery]
其中index是刚刚构造的稀疏相似度矩阵,tfidfQuery是句子的向量空间中的表达。结果如下,返回的是一个array数组,每个元素为语料库中对应句子与query之间的相似度,可见最小为0,最大为0.669571。
构造隐性语义空间模型
与构造向量空间模型极其相似,将向量空间中的数据仅仅通过SVD奇异值分解,就可以压缩到低维的LSI语义空间中。当然具体计算如果还用SVD一步一步计算就太麻烦了,我们仍然用到gensim中的模块。
我们仍然用到一开始构造的语料库的TFIDF向量空间模型,以及语料库的词袋模型:
#构造语料库的tfidf模型 tfidf = models.TfidfModel.load("./model.tfidf") tfidfCorpus = tfidf[bowCorpus] #将高维的向量空间压缩到200维的低维空间 lsi_model = models.LsiModel(tfidfCorpus, id2word=dictionary, num_topics=200) #构建LSI相似度矩阵 index = similarities.Similarity('Similarity-LSI-index', lsiCorpus, num_features=200) #获取语料库的lsi空间的向量表示 lsiCorpus = lsi_model[tfidfCorpus]
其中的200维是我拍脑袋选的,当然主题个数的选取对结果有一定的影响,但在此处就大致取200.
我们获取语料库中第24个句子的隐性语义空间中的表示:
lsiCorpus_24 = lsiCorpus[23]
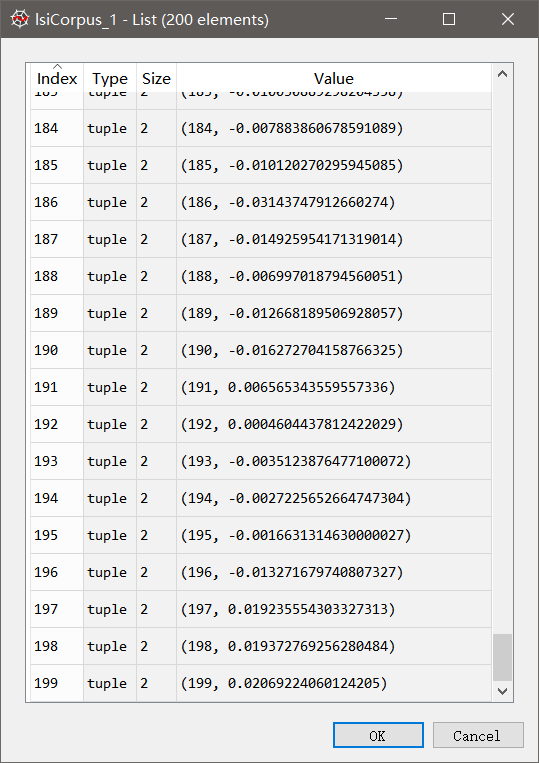
该LSI空间的向量与VSM空间中的向量差别很大:
VSM空间中的向量是稀疏表示,而LSI空间中的向量在每一个维度(主题)上都有投影。
VSM空间中的维度是词项,每一维度上的权重都是tfidf,因此都为正实数;但LSI空间中的维度并非词项而是语义主题,可能会出现负值。
该例中VSM空间的维数即为字典中的键值对数,LSI空间的维度均为200。