- 1、Kafka GroupCoordinator的核心功能及其由来
- 2、Group协调
- 3、Consumer commit offset的存储
- 4、如何选择GroupCoordinator
- 5、Configuration
1、Kafka GroupCoordinator的核心功能及其由来
Kafka Consumer消费topic消息时,分配策略是将topic中的partition分配给Consumer,其中Consumer又是以组的方式进行管理的。一个Consumer Group订阅一个topic,最终是Group中的每一个Consumer去订阅部分的partition,Group中整个Group订阅所有的partition。
在Kafka里,用于管理Group与成员关系、协调重分配的过程,是一个被称为Coordinator的组件来完成的。并且在0.9版本之前,该协调是由ZooKeeper来完成的,从0.9开始,这个事情由Kafka Broker来完成了。
此外,每一个分区,其实是4个offset:
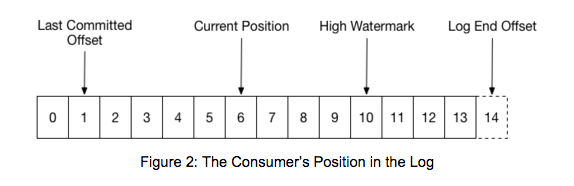
Leo:代表了producer提交的message set的最后一个offset
HW:代表了最大可以供Consumer消费的message set的offset
Current Position:代表了某个Consumer Group消费到的位置
Last Committed Offset:代表了某个Consumer Group Commit的offset。
其中leo,hw都不必说了,他们是存在于recovery-point-offset-checkpoint, replication-checkpoint 两个文件中的它两个都是针对于分区来说的。
Current position 是有Consumer自身知道的。
Last Committed Offset则是记录了Partition在某个Consumer Group的消费情况。
在0.9之前,这两个offset也是记录在zookeeper,则改为记录到内置topic __consumer_offset中了 ,这样的改变的一个重要原因是每一次消费consumer都要往zk上写一次commited offset,而kafka也要向zookeeper记录一次current position。这样给zk带来了沉重的负担,降低了消费性能。
也就说,在0.9之后版本中,Kafka Broker又承担了两个角色:1)管理consumer group offset commit, 2)对Group进行协调。
这两个新的特性,都是由Kafka GroupCoordinator来完成的。对于第2)个特性,Group协调工作,并不是只针对与Consumer Group,而是可以对于任何组。在Kafka 中,目前已经有两种组了: ConsumerGroup、WorkerGroup。
2、Group协调
具体来讲,是针对具备订阅关系的组进行协调。例如Consumer Group要订阅topic,那就将topic 中的partition按照某种策略分配给Group内的各个Consumer;Worker Group要订阅各个connector,那就把connector内的各个task分配给Group内的各个Worker。
2.1 Rebalance
GroupCoordinator提供了4个API来进行组协调工作:
join group, sync group,leave group, heartbeat。
也就是说GroupCoordinator是维持了动态的Group,然而因为这个Group是为了订阅到某种资源,所以,一旦成员数量发生了变更、或者资源数目发生了变更,需要进行资源重新分配(reblance)。此外为了跟踪各个member的状态,需要各个成员与Group Coordinator保持心跳,一旦心跳超时,也会认为该member离开了Group。
为了更好的协调Group,对Group划分了状态:
Dead:死了,该组将不再服务
AwaitingSync:等待Member Leader进行分配状态
Stable:稳定状态
PreparingRebalance:等待重分配状态
1) 一旦有member join group、leave group、 heartbeat timeout时,group变为PreparingRebalance状态
2) 在PreparingRebalance状态下,GroupCoordinator会通知所有的Member进行rebalance。此时该group变为AwaitingSync状态。
3) 在Member接收到需要rebalance时,一旦发现自己是group内所有member的leader,就开始调度assign过程。
4) 所有的member在执行完rebalance请求后,发起sync group的请求给Group Coordinator。非leader的member发的数据是空,而leader member发的是分配的结果。(例如ConsumerCoordinator 回发的是每一个consumer分配到了哪些partition,WorkerCoordinator回发的是每一个work分配到了哪些task。)
5) GroupCoordinator只对leader member的响应做处理,具体说是将该分配请求的数据(bytes)发给每一个member。此时该group变为Stable状态。
6)各个memebr拿到新的分配情况后,应用该分配,并进行heartbeat。
2.2 Group 内member的leader选择
member的leader选择不会频繁的发生,只会出现在两个情况:1) group是empty的组时,会在第一个member加入组是将其选为leader。2)当leader失败或者离开组时,才会重新选择leader,选择的办法很简单,只将第一个member选择leader即可。
def add(memberId: String, member: MemberMetadata) { assert(supportsProtocols(member.protocols)) if (leaderId == null) leaderId = memberId members.put(memberId, member) } // members是一个hashmap def remove(memberId: String) { members.remove(memberId) if (memberId == leaderId) { leaderId = if (members.isEmpty) { null } else { members.keys.head } } }
3、Consumer commit offset存储
__consumer_offsets 是 Kafka 内部使用的一个 topic,专门用来存储 group 消费的情况,默认情况下有50个 partition,每个 partition 三个副本。
具体 group 的消费情况要存储到哪一个 partition 上,是根据 Math.abs(groupId.hashCode()) % partitionCount来计算(其中,parititionCount 是__consumer_offsets的 partition 数,默认是50个)的。
对于offset commit提供了 两个api:
1) commit offset 发生在consumer消费完一次数据后进行commit时,将其存到__consumer_offsets中
2) fetch offset 任何一个客户端都可以随时的调用该请求来获取到last committed offset
此外,每一个group的消费情况也不会是永久的存储到__consumer_offsets里了,也会被定期的清理掉的。
4、如何选择GroupCoordinator?
在一个Kafka集群里,有那么多的Broker的,一旦Consumer 消费了一次数据,还得给GroupCoordinator发一个commit offset的请求,也就是说这个GroupCoordinator处理的最多的是1)接收commit offset请求,2)写offset到__consumer_offsets。所以选择哪个Broker作为Group Coordinator就比较重要了,主要依赖于第2)项了,毕竟对于1)来讲,哪一个Broker都是无可厚非的,但对于2)就不同了,如果作为GroupCoordinator的Broker与group所以对应的parition的leader不在一台机器上,又增加了各个Broker之间的网络负载。
所以GroupCoordinator是选择的group在__consumer_offsets所对应的partition的leader所在的Broker上。
5、Configuration
1) offsets.commit.required.acks, offsets.commit.timeout.ms
GroupCoordinator在处理commit offset请求时,会将消费情况写到__consumer_offsets中,实际上调用的是replicaManager.appendMessage(timeout, requiredAcks,messageSet)方法。
offsets.commit.required.acks,这个配置项,其实就是这个requeiredAcks参数,也就是说,这个配置项和一个producer发送数据是设置的ack是同样的作用,要求在写数据前确认ISR中有足够的replica。它的默认值是-1。
offsets.commit.timeout.ms 就是这个timeout参数,默认值是 5000
2)offsets.load.buffer.size
读取offset segment时的batch size
3)offsets在磁盘上保留多久:offsets.retention.check.interval.ms, offset.retention.minutes
4)offsets.topic.num.parititons, offsets.topic.replication.factor, offsets.topic.segment.bytes,offsets.topic.compression.codec
__consumer_offset Topic的分区数,复制因子,段大小,压缩方式
5) Group成员到GroupCoordinator的session的时间配置:group.max.session.timeout.ms, group.min.session.timeout.ms
Broker中执行heartbeat检查是基于member 的sessiontimeout + member.lastheartbeat作为heartbeat的deadline的。也就是说完全由member自身来控制的。
那么这两个配置项有啥用呢?只是划定一个范围,用于规范member的sesssion timeout配置的,怎么理解呢?
在handleJoinGroup请求时,基于这两个配置,来验证member的session timeout是否在这两个值的范围内,没有其他的作用。