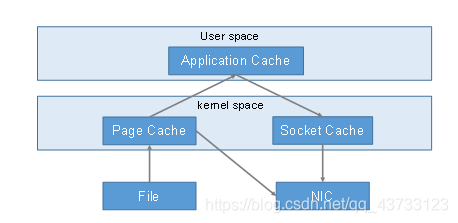
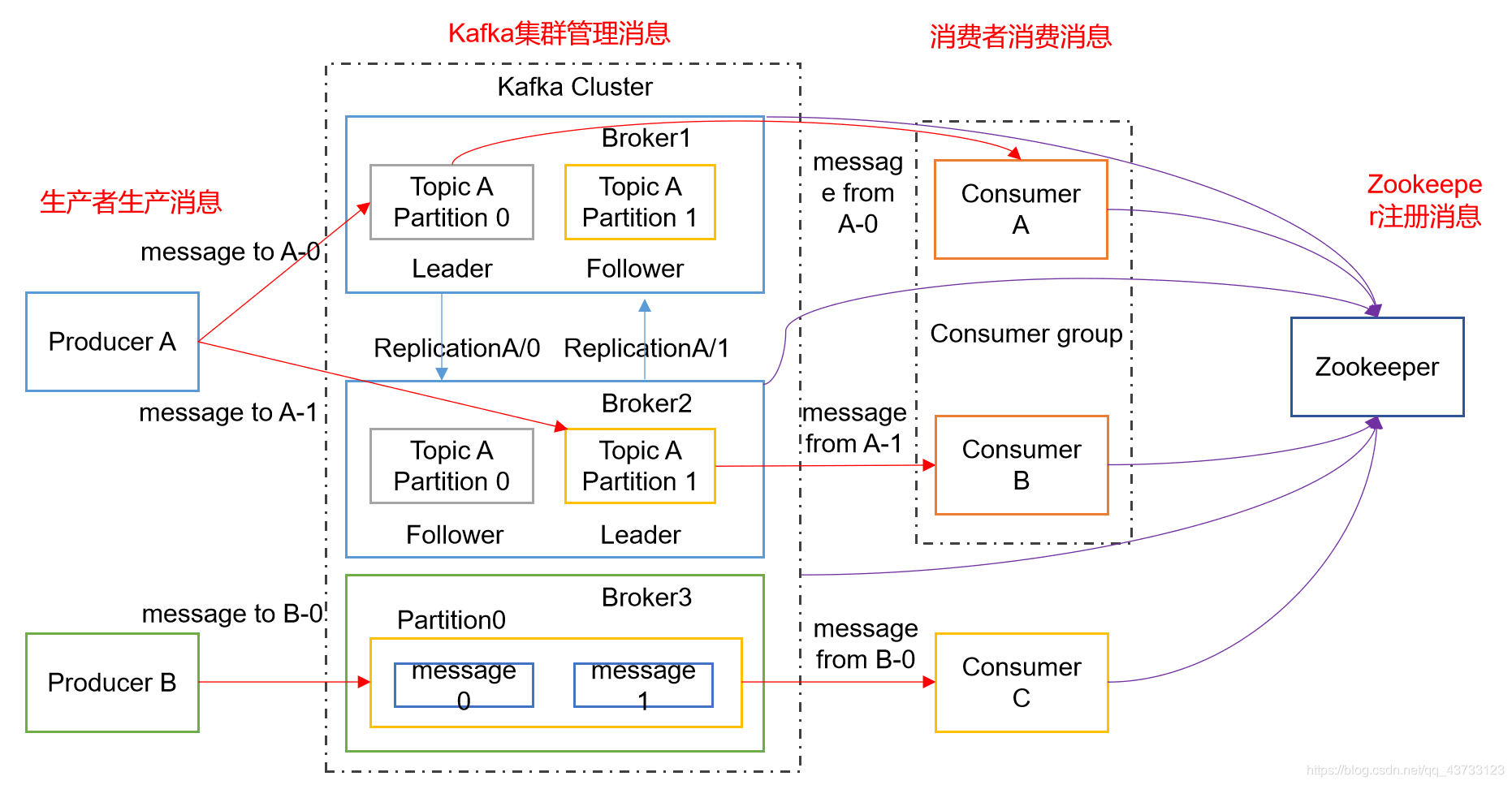
1.Kafka架构图
2.Kafka的机器数量
Kafka机器数量=2*(峰值生产速度*副本数/100)+1
3.Kafka的日志保存时间
默认保存7天

4.Kafka的硬盘大小
每天的数据量 * 7天 /70%
5.Kafka监控器
开源的监控器:KafkaManager、KafkaMonitor、kafkaeagle
6.Kafka的分区数
分区数并不是越多越好,一般分区数不要超过集群机器数量
分区数越多占用内存越大(ISR等),一个节点集中的分区也就越多,当它宕机的时候,对系统的影响也就越大
分区数一般设置为:3-10个
7.副本数设定
企业中一般为2 - 3个
8.Topic数量
通常情况:多少个日志类型就多少个Topic,也有对日志类型进行合并的
9.Kafka Ack
Ack=0:producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker接收到还
没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据
Ack=1:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower
同步成功之前 leader 故障,那么将会丢失数据
Ack=-1(all):producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盘成功后才
返回 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会
造成数据重复
10.Kafka的ISR副本同步队列
ISR(In-Sync Replicas),副本同步队列:ISR中包括Leader和Follower,如果Leader进程挂掉,会在ISR队列中选择一个Follower作为新的Leader;有replica.lag.max.messages(延迟条数)和replica.lag.time.max.ms(延迟时间)两个参数决定一台服务是否可以加入ISR副本队列,在0.10版本移除了replica.lag.max.messages参数,防止服务频繁的进去队列。
任意一个维度超过阈值都会把Follower剔除出ISR,存入OSR(Out-Sync Replicas)列表,新加入的Follower也会先存放在OSR中
11.Kafka分区分配策略
Kafka内部存在两种默认的分区分配策略:Range、RoundRobin,其中Range是默认策略
Range是对每个Topic而言的,首先对同一个Topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序,然后用Partitions分区数除以消费者总数来决定每个消费者线程消费几个分区,如果除不尽,那么前面几个消费者线程将会多消费一个分区
Producer分区规则:
(1)指明 partition 的情况下,直接将指明的值直接作为 partiton 值
(2)没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值
(3)既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法
12.Kafka中数据量
计算每天总数据量100G,每天产生1亿条日志, 10000万/24/60/60=1150条/每秒钟
平均每秒钟:1150条
低谷每秒钟:50条
高峰每秒钟:1150条 *(2-20倍)=2300条 - 23000条
每条日志大小:0.5k - 2k
每秒多少数据量:2.3M - 20MB
13.Kafka消息数据积压,Kafka消费能力不足怎么处理?
1)如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。(两者缺一不可)
2)如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积
14.Kafka幂等性
Producer的幂等性指的是当发送同一条消息时,数据在Server端只会被持久化一次,数据不丟不重,但是这里的幂等性是有条件的:
1)只能保证Producer在单个会话内不丟不重,如果Producer出现意外挂掉再重启是无法保证的(幂等性情况下,是无法获取之前的状态信息,因此是无法做到跨会话级别的不丢不重)
2)幂等性不能跨多个Topic-Partition,只能保证单个Partition内的幂等性,当涉及多个 Topic-Partition时,这中间的状态并没有同步
15.Kafka事务
Kafka从0.11版本开始引入了事务支持。事务可以保证Kafka在Exactly Once语义的基础上,生产和消费可以跨分区和会话,要么全部成功,要么全部失败
1)Producer事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID。
为了管理Transaction,Kafka引入了一个新的组件Transaction Coordinator。Producer就是通过和Transaction Coordinator交互获得Transaction ID对应的任务状态。Transaction Coordinator还负责将事务所有写入Kafka的一个内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行
2)Consumer事务
上述事务机制主要是从Producer方面考虑,对于Consumer而言,事务的保证就会相对较弱,尤其时无法保证Commit的信息被精确消费。这是由于Consumer可以通过offset访问任意信息,而且不同的Segment File生命周期不同,同一事务的消息可能会出现重启后被删除的情况
16.Kafka数据重复
幂等性+ack-1+事务
Kafka数据重复,可以再下一级:SparkStreaming、redis或者hive中dwd层去重,去重的手段:分组、按照id开窗只取第一个值
17.Kafka参数优化
1)Broker参数配置(server.properties)
# broker处理消息的最大线程数(默认为3)
num.network.threads=cpu核数+1
# broker处理磁盘IO的线程数
num.io.threads=cpu核数*2
2)log数据文件刷盘策略
# 每当producer写入10000条消息时,刷数据到磁盘
log.flush.interval.messages=10000
# 每间隔1秒钟时间,刷数据到磁盘
log.flush.interval.ms=1000
3)日志保留策略配置
# 保留三天,也可以更短 (log.cleaner.delete.retention.ms)
log.retention.hours=72
4)Replica相关配置
offsets.topic.replication.factor:3
# 这个参数指新创建一个topic时,默认的Replica数量,
Replica过少会影响数据的可用性,太多则会白白浪费存储资源,
一般建议在2~3为宜。
2)Producer优化(producer.properties)
buffer.memory:33554432 (32m)
#在Producer端用来存放尚未发送出去的Message的缓冲区大小。缓冲区满了之后可
以选择阻塞发送或抛出异常,由block.on.buffer.full的配置来决定。
compression.type:none
#默认发送不进行压缩,推荐配置一种适合的压缩算法,
可以大幅度的减缓网络压力和Broker的存储压力
5)Kafka内存调整(kafka-server-start.sh)
默认内存1个G,生产环境尽量不要超过6个G。
export KAFKA_HEAP_OPTS="-Xms4g -Xmx4g"
18.Kafka 高效读写数据
1)Kafka本身是分布式集群,同时采用分区技术,并发度高
2)顺序写磁盘
Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间
3)零复制技术