梯度消失和梯度爆炸
- 在反向传播算法计算cost函数的对每个参数的梯度误差之后,在更新参数的时候,随着越来越到低层,梯度越来越小, 最后导致lower layer的连接权重最后变化很小,甚至不变。然后训练持续下去一直得不到拟合,这就是梯度消失问题(
vanishing gradients problem).相反的情况是梯度随着传播越来越大,这经常发生在RNNs的训练中。 - 结论:通常深度神经网络传播的梯度一般不稳定,不同层的学习速度都不一样。
# To support both python 2 and python 3
from __future__ import division, print_function, unicode_literals
import numpy as np
import os
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "deep"
path = os.path.join(PROJECT_ROOT_DIR, "images",CHAPTER_ID)
if not os.path.exists(path):
os.makedirs(path)
def save_fig(fig_id, tight_layout=True):
path = os.path.join(PROJECT_ROOT_DIR, "images",CHAPTER_ID,fig_id + ".png")
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format="png",dpi=300)当使用sigmoid时的情况:
def logit(z):
return 1 / (1 + np.exp(-z))
z = np.linspace(-5, 5, 200)
plt.plot([-5, 5], [0, 0], 'k-')
plt.plot([-5, 5], [1, 1], 'k--')
plt.plot([0, 0],[-0.2, 1.2],'k-')
plt.plot([-5, 5], [ -3/4, 7/4], 'g--')
plt.plot(z, logit(z), 'b-',linewidth=2)
props = dict(facecolor='black',shrink=0.1)
# xytext是注释的位置,xy是箭头位置
plt.annotate('Saturating', xytext=(3.5, 0.7), xy=(5, 1), arrowprops=props, fontsize=14,ha="center")
plt.annotate('Saturating',xytext=(-3.5,0.3),xy=(-5, 0),arrowprops=props,fontsize=14,ha="center")
plt.annotate('Linear', xytext=(2, 0.2),xy=(0, 0.5),arrowprops=props,fontsize=14,ha="center")
plt.grid(True)
plt.title("Sigmoid actication function",fontsize=14)
plt.axis([-5, 5, -0.2, 1.2])
save_fig("sigmoid_saturation_plot")
解决办法:Xavier初始化和He初始化
为了信号(神经元中传递的数据)能够顺利流通,需要每层输出(outputs)数据的方差等于该层输入(inputs)数据的方差,同样梯度也要求在反向传播中穿越每一层前后的方差相等。
实践中,通过初始化权重的策略达到很这个目的。这种初始化策略也称为Xavier initialization。
Equation 11-1: Xavier initialization (when using the logistic activation function)
其中 是连接每层的神经元数量(fan-in), 是每层输出到下一层的数量(fan-out)。下面是各种激活函数的初始化公式:
Table 11-1: Initialization parameters for each type of activation function
- Logistic uniform:
- Logistic normal:
- Hyperbolic tangent uniform:
- Hyperbolic tangent normal:
- ReLU (and its variants) uniform:
- ReLU (and its variants) normal:
其中ReLU及其变体的初始化策略也称为He initialization,但是He初始化只考虑了fan-in,这也是variance_scaling_initializer()默认状态,可以通过参数mode=“FAN_AVG”使考虑到fan-out。
代码:
import tensorflow as tf
reset_graph()
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 150
X = tf.placeholder(tf.float32,[4, n_inputs])
he_init = tf.contrib.layers.variance_scaling_initializer()
hidden1 = tf.layers.dense(X, n_hidden1,activation=tf.nn.relu,
kernel_initializer=he_init,name="hidden1")
hidden2 = tf.layers.dense(hidden1,n_hidden2,activation=tf.nn.relu,
kernel_initializer=he_init,name="hidden2")
noise = tf.random_normal(tf.shape(hidden2),dtype=tf.float32)
test = hidden2 * noise
init =tf.global_variables_initializer()
with tf.Session() as sess:
init.run()
X_batch = tf.random_normal(shape=tf.shape(X),dtype=tf.float32)
#X_batch = X_batch.eval()
hidden1_val = sess.run(hidden1,feed_dict={X:X_batch.eval()})
hidden2_val = sess.run(hidden2,feed_dict={X:X_batch.eval()})
print(sess.run(tf.shape(hidden1),feed_dict={X:X_batch.eval()}))
test_val = sess.run(test,feed_dict={X:X_batch.eval()})
输出:
[ 4 300]
hidden1_val.mean(axis=1)
array([0.55054766, 0.68728137, 0.581091 , 0.57153785], dtype=float32)
hidden1_val.var(axis=1)
array([0.6577774 , 0.87363034, 0.69525075, 0.7773675 ], dtype=float32)
ReLU的优点和缺点
- 优点:计算快、对于正数不会发生saturate。
缺点:在训练过程中,部分神经元会死掉,当输入神经元的连接权的和为负数时,该神经元只会输出0,而且神经元不会复活,因为ReLU的输入是负数时,梯度为0。
所以有了ReLU的很多变体,都是Nonsaturating Activation Functions.Leaky ReLU:
def leaky_relu(z, alpha=0.01):
return np.maximum(alpha*z, z)
plt.plot(z, leaky_relu(z, 0.05),"b-", linewidth=2)
plt.plot([-5,5], [0, 0], 'k-')
plt.plot([0, 0],[-0.5, 4.2],'k-')
plt.grid(True)
props = dict(facecolor='black', shrink=0.1)
plt.annotate("Leak", xytext=(-3.5,0.5),xy=(-5,-0.2),arrowprops=props,fontsize=14,ha="center")
plt.title("Leaky ReLU actication function", fontsize=14)
plt.axis([-5, 5, -0.5, 4.2])
save_fig("leaky_relu_plot")
plt.show()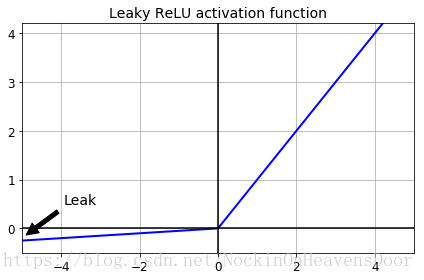
- tensorflow实现LReLU:
def leaky_relu(z, name=None):
return tf.maximum(0.01 * z, z, name=name)在mnist上用LReLU
reset_graph()
def leaky_relu(z, name=None):
return tf.maximum(0.01 * z, z, name=name)
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X = tf.placeholder(tf.float32,shape=(None, n_inputs),name ="X")
y = tf.placeholder(tf.int64,shape=(None),name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X,n_hidden1,activation=leaky_relu,name="hidden1")
hidden2 = tf.layers.dense(hidden1,n_hidden2,activation=leaky_relu,name="hidden2")
logits = tf.layers.dense(hidden2,n_outputs,activation=None,name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y , 1)
accuracy = tf.reduce_mean(tf.cast(correct,tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
#load the data:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/")
n_epochs = 40
batch_size = 50
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples// batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X:X_batch, y:y_batch})
if epoch % 5 == 0:
acc_train = accuracy.eval(feed_dict={X:X_batch,y: y_batch})
acc_test = accuracy.eval(feed_dict={X:mnist.validation.images,y:mnist.validation.labels})
print(epoch, "Batch accuracy:", acc_train, "Validation accuracy:", acc_test)
save_path = saver.save(sess,"./my_model_final.ckpt")
输出:
0 Batch accuracy: 0.86 Validation accuracy: 0.9044
5 Batch accuracy: 0.94 Validation accuracy: 0.951
10 Batch accuracy: 0.96 Validation accuracy: 0.9666
15 Batch accuracy: 1.0 Validation accuracy: 0.972
20 Batch accuracy: 1.0 Validation accuracy: 0.9748
25 Batch accuracy: 1.0 Validation accuracy: 0.9764
30 Batch accuracy: 0.98 Validation accuracy: 0.978
35 Batch accuracy: 0.96 Validation accuracy: 0.9792- ELU
Equation 11-2: ELU activation function
代码:
def elu(z, alpha=1):
return np.where(z < 0, alpha * (np.exp(z) - 1), z)plt.plot(z, elu(z), "b-", linewidth=2)
plt.plot([-5, 5], [0, 0], 'k-')
plt.plot([-5, 5], [-1, -1], 'k--')
plt.plot([0, 0], [-2.2, 3.2], 'k-')
plt.grid(True)
plt.title(r"ELU activation function ($\alpha=1$)", fontsize=14)
plt.axis([-5, 5, -2.2, 3.2])
save_fig("elu_plot")
plt.show()
- tensorflow中用ELU:
reset_graph()
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.elu, name="hidden1")- SELU
def selu(z,
scale=1.0507009873554804934193349852946,
alpha=1.6732632423543772848170429916717):
return scale * elu(z, alpha)plt.plot(z, selu(z), "b-", linewidth=2)
plt.plot([-5, 5], [0, 0], 'k-')
plt.plot([-5, 5], [-1.758, -1.758], 'k--')
plt.plot([0, 0], [-2.2, 3.2], 'k-')
plt.grid(True)
plt.title(r"SELU activation function", fontsize=14)
plt.axis([-5, 5, -2.2, 3.2])
save_fig("selu_plot")
plt.show()
注:With this activation function, even a 100 layer deep neural network preserves roughly mean 0 and standard deviation 1 across all layers, avoiding the exploding/vanishing gradients problem:
np.random.seed(42)
Z = np.random.normal(size=(500, 100))
for layer in range(100):
W = np.random.normal(size=(100, 100), scale=np.sqrt(1/100))
Z = selu(np.dot(Z, W))
means = np.mean(Z, axis=1)
stds = np.std(Z, axis=1)
if layer % 10 == 0:
print("Layer {}: {:.2f} < mean < {:.2f}, {:.2f} < std deviation < {:.2f}".format(
layer, means.min(), means.max(), stds.min(), stds.max()))输出:
Layer 0: -0.26 < mean < 0.27, 0.74 < std deviation < 1.27
Layer 10: -0.24 < mean < 0.27, 0.74 < std deviation < 1.27
Layer 20: -0.17 < mean < 0.18, 0.74 < std deviation < 1.24
Layer 30: -0.27 < mean < 0.24, 0.78 < std deviation < 1.20
Layer 40: -0.38 < mean < 0.39, 0.74 < std deviation < 1.25
Layer 50: -0.27 < mean < 0.31, 0.73 < std deviation < 1.27
Layer 60: -0.26 < mean < 0.43, 0.74 < std deviation < 1.35
Layer 70: -0.19 < mean < 0.21, 0.75 < std deviation < 1.21
Layer 80: -0.18 < mean < 0.16, 0.72 < std deviation < 1.19
Layer 90: -0.19 < mean < 0.16, 0.75 < std deviation < 1.20
- tensorflow实现:
def selu(z,
scale=1.0507009873554804934193349852946,
alpha=1.6732632423543772848170429916717):
return scale * tf.where(z >= 0.0, z, alpha * tf.nn.elu(z))SELUs结合dropout 参考这个
- MNIST上用SELU:
def selu(z,
scale=1.0507009873554804934193349852946,
alpha=1.6732632423543772848170429916717):
return scale * tf.where(z >= 0.0, z, alpha * tf.nn.elu(z))
reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=selu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=selu, name="hidden2")
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 40
batch_size = 50注意:接下来训练的时候得把输入数据标准化为期望0,标准差1(scale the inputs to mean 0 and standard deviation 1)
means = mnist.train.images.mean(axis=0, keepdims=True)
stds = mnist.train.images.std(axis=0, keepdims=True) + 1e-10
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
X_batch_scaled = (X_batch - means) / stds
sess.run(training_op, feed_dict={X: X_batch_scaled, y: y_batch})
if epoch % 5 == 0:
acc_train = accuracy.eval(feed_dict={X: X_batch_scaled, y: y_batch})
X_val_scaled = (mnist.validation.images - means) / stds
acc_test = accuracy.eval(feed_dict={X: X_val_scaled, y: mnist.validation.labels})
print(epoch, "Batch accuracy:", acc_train, "Validation accuracy:", acc_test)
save_path = saver.save(sess, "./my_model_final_selu.ckpt")输出:
0 Batch accuracy: 0.96 Validation accuracy: 0.924
5 Batch accuracy: 1.0 Validation accuracy: 0.9568
10 Batch accuracy: 0.94 Validation accuracy: 0.967
15 Batch accuracy: 0.98 Validation accuracy: 0.9686
20 Batch accuracy: 1.0 Validation accuracy: 0.971
25 Batch accuracy: 1.0 Validation accuracy: 0.9692
30 Batch accuracy: 1.0 Validation accuracy: 0.9702
35 Batch accuracy: 1.0 Validation accuracy: 0.971
隐层中使用激活函数的策略
通常是
关注运行时间,那么 leaky ReLUs(超参默认为0.01)比ELUs(超参默认为1)好些,RReLU可用在过拟合的情况,PReLU可用在训练集很多的情况。
Batch Normalization
每层使用激活函数之前,对输入进行正则化。
Equation 11-3: Batch Normalization algorithm
- 是mini-batch 上的样本期望;
- 是样本标准差;
- 是mini-batch的数量;
- 是正则化之后的输入;
- 每层的规模参数(scaling parameter);
- 是每层的均衡(offset)参数;
- 防止分母是0的smoothing term;
- 是BN操作后的输出。
代码:
reset_graph()
import tensorflow as tf
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None,n_inputs),name="X")
training = tf.placeholder_with_default(False, shape=(),name="training")
hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1")
#先正则化之后再激活
hn1 = tf.layers.batch_normalization(hidden1,training=training,momentum=0.9)
bn1_act = tf.nn.elu(hn1)
hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2")
#先正则化之后再激活
bn2 = tf.layers.batch_normalization(hidden2, training=training,momentum=0.9)
bn2_act = tf.nn.elu(bn2)
#outputs的正则化
logits_before_bn = tf.layers.dense(bn2_act,n_outputs,name="outputs")
logits = tf.layers.batch_normalization(logits_before_bn, training=training,
momentum=0.9)
- 用partial封装的参数正则化函数
reset_graph()
X = tf.placeholder(tf.float32, shape=(None, n_inputs),name="X")
training = tf.placeholder_with_default(False, shape=(),name="training")
from functools import partial
"""
tf.layers.batch_normalization
Note: when training, the moving_mean and moving_variance need to be updated.
By default the update ops are placed in `tf.GraphKeys.UPDATE_OPS`, so they
need to be added as a dependency to the `train_op`. For example:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss)
"""
my_batch_norm_layer = partial(tf.layers.batch_normalization,
training=training,momentum=0.9)
hidden1 = tf.layers.dense(X, n_hidden1,name ="hidden1")
bn1 = my_batch_norm_layer(hidden1)
bn1_act = tf.nn.elu(bn1)
hidden2 = tf.layers.dense(bn1_act,n_hidden2, name="hidden2")
bn2 = my_batch_norm_layer(hidden2)
bn2_act = tf.nn.elu(bn2)
logits_before_bn = tf.layers.dense(bn2_act, n_outputs,name="outputs")
logits = my_batch_norm_layer(logits_before_bn)- using the ELU activation function and Batch Normalization at each layer:
reset_graph()
batch_norm_momentum = 0.9
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
training = tf.placeholder_with_default(False, shape=(), name='training')
with tf.name_scope("dnn"):
he_init = tf.contrib.layers.variance_scaling_initializer()
my_batch_norm_layer = partial(
tf.layers.batch_normalization,
training=training,
momentum=batch_norm_momentum)
my_dense_layer = partial(
tf.layers.dense,
kernel_initializer=he_init)
hidden1 = my_dense_layer(X, n_hidden1, name="hidden1")
bn1 = tf.nn.elu(my_batch_norm_layer(hidden1))
hidden2 = my_dense_layer(bn1, n_hidden2, name="hidden2")
bn2 = tf.nn.elu(my_batch_norm_layer(hidden2))
logits_before_bn = my_dense_layer(bn2, n_outputs, name="outputs")
logits = my_batch_norm_layer(logits_before_bn)
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 20
batch_size = 200
#tf.layers.batch_normalization()需要额外的运行依赖更新如下
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run([training_op, extra_update_ops],
feed_dict={training: True, X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_model_final.ckpt")输出:
0 Test accuracy: 0.8666
1 Test accuracy: 0.894
2 Test accuracy: 0.9088
3 Test accuracy: 0.9189
4 Test accuracy: 0.9262
5 Test accuracy: 0.9334
6 Test accuracy: 0.9379
7 Test accuracy: 0.942
8 Test accuracy: 0.9444
9 Test accuracy: 0.9477
10 Test accuracy: 0.9499
11 Test accuracy: 0.952
12 Test accuracy: 0.9546
13 Test accuracy: 0.956
14 Test accuracy: 0.9567
15 Test accuracy: 0.9591
16 Test accuracy: 0.9609
17 Test accuracy: 0.9612
18 Test accuracy: 0.9618
19 Test accuracy: 0.9635
注1:也可以用tf.control_dependencies实现一下:
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(extra_update_ops):
training_op = optimizer.minimize(loss)当执行training_op的时候,tensorflow会自动执行更新的操作:
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})注2: trainable variables 少于 global variables. This is because the moving averages are non-trainable variables.
所以想重用一个预先训练好的神经网络,要把non-trainable variables包含进来。
可训练变量:
[v.name for v in tf.trainable_variables()]
输出:
['hidden1/kernel:0',
'hidden1/bias:0',
'batch_normalization/gamma:0',
'batch_normalization/beta:0',
'hidden2/kernel:0',
'hidden2/bias:0',
'batch_normalization_1/gamma:0',
'batch_normalization_1/beta:0',
'outputs/kernel:0',
'outputs/bias:0',
'batch_normalization_2/gamma:0',
'batch_normalization_2/beta:0']
全局变量:
[v.name for v in tf.global_variables()]
输出:
['hidden1/kernel:0',
'hidden1/bias:0',
'batch_normalization/gamma:0',
'batch_normalization/beta:0',
'batch_normalization/moving_mean:0',
'batch_normalization/moving_variance:0',
'hidden2/kernel:0',
'hidden2/bias:0',
'batch_normalization_1/gamma:0',
'batch_normalization_1/beta:0',
'batch_normalization_1/moving_mean:0',
'batch_normalization_1/moving_variance:0',
'outputs/kernel:0',
'outputs/bias:0',
'batch_normalization_2/gamma:0',
'batch_normalization_2/beta:0',
'batch_normalization_2/moving_mean:0',
'batch_normalization_2/moving_variance:0']梯度修剪
参考我写的这个梯度修剪
重用训练好的层
已经有了一个训练好的神经网络,那么做另一个相似的任务时,可以利用已经训练好的层,称为transfer learning:

注:迁移学习得到很好的利用的饿前提是新的输入数据和之前的训练数据有相似的低维特征,比如区分图片为100个类别,包括动物,飞机,机车,和其他目标对象。现在想要区分不同的机车,如摩托、单车、汽车等,因为任务相似,低维特征相似,可以用来做迁移学习。
代码:
import_meta_graph()函数导入图的结构和所有操作到default graph上,返回一个saver用来后面恢复模型的状态;注:saver把图的结构保存在.meta文件中。
reset_graph()
saver = tf.train.import_meta_graph("./my_model_final.ckpt.meta")
for op in tf.get_default_graph().get_operations():
print(op.name)输出:
save/RestoreV2/shape_and_slices
save/RestoreV2/tensor_names
save/SaveV2/shape_and_slices
save/SaveV2/tensor_names
save/Const
save/RestoreV2
eval/Const
eval/in_top_k/InTopKV2/k
GradientDescent/learning_rate
clip_by_value_11/clip_value_max
clip_by_value_11/clip_value_min
clip_by_value_10/clip_value_max
clip_by_value_10/clip_value_min
……
……
……
知道还原的图的操作名和tensor名的话,直接get_tensor_by_name和get_operation_by_name获取:
X = tf.get_default_graph().get_tensor_by_name("X:0")
y = tf.get_default_graph().get_tensor_by_name("y:0")
accuracy = tf.get_default_graph().get_tensor_by_name("eval/accuracy:0")
training_op = tf.get_default_graph().get_operation_by_name("GradientDescent")注: create a collection containing all the important operations that people will want to get a handle on
for op in (X, y, accuracy, training_op):
tf.add_to_collection("my_important_ops", op)创建一个"my_important_ops"的集合,放着之后重新恢复模型需要再次利用的ops,恢复使用:
X, y, accuracy, training_op = tf.get_collection("my_important_ops")恢复了图的结构之后,就可以启动一个会话session开始训练了:
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_new_model_final.ckpt") 输出:
……….
13 Test accuracy: 0.9693
14 Test accuracy: 0.9687
15 Test accuracy: 0.9698
16 Test accuracy: 0.9685
17 Test accuracy: 0.9697
18 Test accuracy: 0.9687
19 Test accuracy: 0.9684
但是通常只想重用训练好的低层神经网络,下面重用前面的3个隐层,第四层重新训练,不用前面训练好的第四层,同时用一个新的输出层和新的loss和优化器优化它。
代码:
reset_graph()
n_hidden4 = 20 # new layer
n_outputs = 10 # new layer
#这个saver用来恢复旧的图
saver = tf.train.import_meta_graph("./my_model_final.ckpt.meta")
X = tf.get_default_graph().get_tensor_by_name("X:0")
y = tf.get_default_graph().get_tensor_by_name("y:0")
hidden3 = tf.get_default_graph().get_tensor_by_name("dnn/hidden4/Relu:0")
new_hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="new_hidden4")
new_logits = tf.layers.dense(new_hidden4, n_outputs, name="new_outputs")
with tf.name_scope("new_loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=new_logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("new_eval"):
correct = tf.nn.in_top_k(new_logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
with tf.name_scope("new_train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
#用来存储新的训练完成的图
new_saver = tf.train.Saver()
#训练并存储新的训练图
with tf.Session() as sess:
init.run()
#这个图用来恢复旧的模型
saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
#用新创建的saver存储图
save_path = new_saver.save(sess, "./my_new_model_final.ckpt")
结果:
INFO:tensorflow:Restoring parameters from ./my_model_final.ckpt
0 Test accuracy: 0.9242
1 Test accuracy: 0.9403
2 Test accuracy: 0.9463
3 Test accuracy: 0.9511
4 Test accuracy: 0.9544
5 Test accuracy: 0.9544
6 Test accuracy: 0.9585
7 Test accuracy: 0.9596
8 Test accuracy: 0.9596
9 Test accuracy: 0.9621
10 Test accuracy: 0.9634
11 Test accuracy: 0.9638
12 Test accuracy: 0.9648
13 Test accuracy: 0.9653
14 Test accuracy: 0.9659
15 Test accuracy: 0.9653
16 Test accuracy: 0.9664
17 Test accuracy: 0.9668
18 Test accuracy: 0.9677
19 Test accuracy: 0.9675
另一种重用方式是修改原有的代码的方式:
reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300 # reused
n_hidden2 = 50 # reused
n_hidden3 = 50 # reused
n_hidden4 = 20 # new!
n_outputs = 10 # new!
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1") # reused
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2") # reused
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3") # reused
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4") # new!
logits = tf.layers.dense(hidden4, n_outputs, name="outputs") # new!
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
#重用隐层1、2、3
reuse_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
scope="hidden[123]") # regular expression
#重用变量的字典
reuse_vars_dict = dict([(var.op.name, var) for var in reuse_vars])
restore_saver = tf.train.Saver(reuse_vars_dict) # to restore layers 1-3
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
init.run()
restore_saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_new_model_final.ckpt")
输出:
INFO:tensorflow:Restoring parameters from ./my_model_final.ckpt
0 Test accuracy: 0.9231
1 Test accuracy: 0.9375
2 Test accuracy: 0.9454
3 Test accuracy: 0.9518
4 Test accuracy: 0.9563
5 Test accuracy: 0.9576
6 Test accuracy: 0.959
7 Test accuracy: 0.9605
8 Test accuracy: 0.961
9 Test accuracy: 0.9622
10 Test accuracy: 0.9612
11 Test accuracy: 0.9637
12 Test accuracy: 0.9627
13 Test accuracy: 0.9653
14 Test accuracy: 0.9661
15 Test accuracy: 0.9669
16 Test accuracy: 0.9666
17 Test accuracy: 0.9663
18 Test accuracy: 0.9659
19 Test accuracy: 0.9668冻结低层神经网络
reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300 # reused
n_hidden2 = 50 # reused
n_hidden3 = 50 # reused
n_hidden4 = 20 # new!
n_outputs = 10 # new!
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1") # reused
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2") # reused
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3") # reused
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4") # new!
logits = tf.layers.dense(hidden4, n_outputs, name="outputs") # new!
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
#收集要训练的变量
train_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,scope="hidden[34]|outputs")
#重新训练
training_op = optimizer.minimize(loss ,var_list=train_vars)
init = tf.global_variables_initializer()
new_saver = tf.train.Saver()
#收集要重用的变量
reuse_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
scope="hidden[123]")
#建立字典
reuse_var_list = dict([(var.op.name,var) for var in reuse_vars])
restore_saver = tf.train.Saver(reuse_var_list) #恢复1-3层
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
init.run()
restore_saver.restore(sess,"./my_model_final.ckpt")
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X:X_batch, y:y_batch})
accuracy_val = accuracy.eval(feed_dict={X:mnist.test.images,
y:mnist.test.labels})
print(epoch, "Test accuracy:",accuracy_val)
save_path = saver.save(sess,"./my_model+final.ckpt")
输出:
INFO:tensorflow:Restoring parameters from ./my_model_final.ckpt
0 Test accuracy: 0.7505
1 Test accuracy: 0.777
2 Test accuracy: 0.8008
3 Test accuracy: 0.8225
4 Test accuracy: 0.8487
5 Test accuracy: 0.8613
6 Test accuracy: 0.8673
7 Test accuracy: 0.8774
8 Test accuracy: 0.8808
9 Test accuracy: 0.8879
10 Test accuracy: 0.8969
11 Test accuracy: 0.896
12 Test accuracy: 0.9036
13 Test accuracy: 0.9089
14 Test accuracy: 0.9095
15 Test accuracy: 0.9126
16 Test accuracy: 0.9136
17 Test accuracy: 0.9165
18 Test accuracy: 0.9157
19 Test accuracy: 0.921缓存冻结的低层
冻结的层不会改变,所以对冻结层的最上层用一个训练样本做缓存,这样做每个训练实例在冻结层中执行一次,而不是每一个epoch都会被执行:
hidden2_outputs = sess.run(hidden2, feed_dict={X:X_train})reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300 # reused
n_hidden2 = 50 # reused
n_hidden3 = 50 # reused
n_hidden4 = 20 # new!
n_outputs = 10 # new!
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,
name="hidden1") # reused frozen
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu,
name="hidden2") # reused frozen & cached
hidden2_stop = tf.stop_gradient(hidden2)
hidden3 = tf.layers.dense(hidden2_stop, n_hidden3, activation=tf.nn.relu,
name="hidden3") # reused, not frozen
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu,
name="hidden4") # new!
logits = tf.layers.dense(hidden4, n_outputs, name="outputs") # new!
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
reuse_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
scope="hidden[123]") # regular expression
reuse_vars_dict = dict([(var.op.name, var) for var in reuse_vars])
restore_saver = tf.train.Saver(reuse_vars_dict) # to restore layers 1-3
init = tf.global_variables_initializer()
saver = tf.train.Save()
import numpy as np
n_batches = mnist.train.num_examples // batch_size
with tf.Session() as sess:
init.run()
restore_saver.restore(sess, "./my_model_final.ckpt")
h2_cache = sess.run(hidden2, feed_dict={X: mnist.train.images})
h2_cache_test = sess.run(hidden2, feed_dict={X: mnist.test.images}) # not shown in the book
for epoch in range(n_epochs):
shuffled_idx = np.random.permutation(mnist.train.num_examples)
hidden2_batches = np.array_split(h2_cache[shuffled_idx], n_batches)
y_batches = np.array_split(mnist.train.labels[shuffled_idx], n_batches)
for hidden2_batch, y_batch in zip(hidden2_batches, y_batches):
sess.run(training_op, feed_dict={hidden2:hidden2_batch, y:y_batch})
accuracy_val = accuracy.eval(feed_dict={hidden2: h2_cache_test, # not shown
y: mnist.test.labels}) # not shown
print(epoch, "Test accuracy:", accuracy_val) # not shown
save_path = saver.save(sess, "./my_new_model_final.ckpt")
输出:
INFO:tensorflow:Restoring parameters from ./my_model_final.ckpt
0 Test accuracy: 0.9033
1 Test accuracy: 0.9322
2 Test accuracy: 0.9423
3 Test accuracy: 0.9449
4 Test accuracy: 0.9471
5 Test accuracy: 0.9477
6 Test accuracy: 0.951
7 Test accuracy: 0.9507
8 Test accuracy: 0.9514
9 Test accuracy: 0.9522
10 Test accuracy: 0.9512
11 Test accuracy: 0.9521
12 Test accuracy: 0.9522
13 Test accuracy: 0.9539
14 Test accuracy: 0.9536
15 Test accuracy: 0.9534
16 Test accuracy: 0.9547
17 Test accuracy: 0.9537
18 Test accuracy: 0.9542
19 Test accuracy: 0.9547